BUMBLE: Unifying Reasoning and Acting with Vision-Language Models for Building-wide Mobile Manipulation
作者: Rutav Shah, Albert Yu, Yifeng Zhu, Yuke Zhu, Roberto Martín-Martín
分类: cs.RO, cs.AI
发布日期: 2024-10-08
备注: 7 Figures, 2 Tables, 11 Pages
💡 一句话要点
BUMBLE:利用视觉-语言模型统一推理与行动,实现楼宇级移动操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 移动操作 机器人 长时程任务 楼宇级环境
📋 核心要点
- 现有移动操作方法难以应对楼宇尺度下的长时程任务,面临着环境复杂、任务多样、技能需求广泛等挑战。
- BUMBLE框架利用视觉-语言模型统一推理与行动,结合RGBD感知、多粒度运动技能和双层记忆,实现高效的楼宇级移动操作。
- 实验结果表明,BUMBLE在长时程任务中显著优于现有方法,用户满意度更高,并展现了利用更强大的基础模型进一步提升性能的潜力。
📝 摘要(中文)
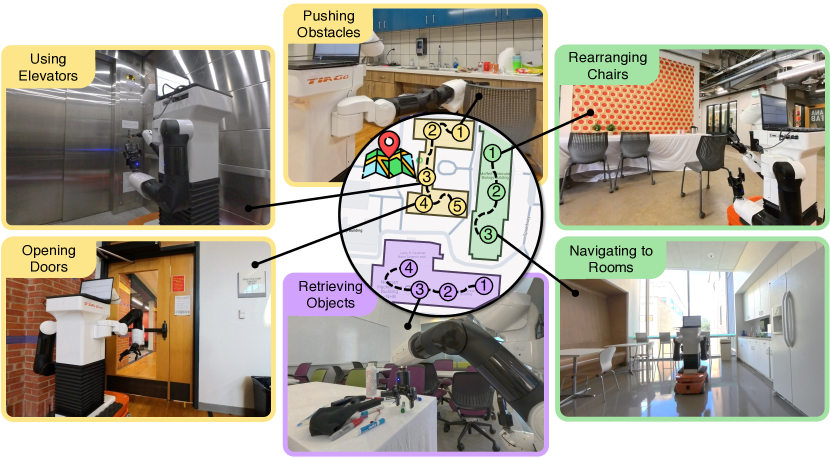
为了在楼宇尺度上运行,服务机器人必须执行超长时程的移动操作任务,包括导航到不同的房间、进入不同的楼层,以及与各种未见过的日常物品互动。我们将这些任务称为楼宇级移动操作。为了解决这些固有的长时程任务,我们引入了BUMBLE,这是一个统一的基于视觉-语言模型(VLM)的框架,集成了开放世界的RGBD感知、广泛的从粗到精的运动技能以及双层记忆。我们广泛的评估(90+小时)表明,BUMBLE在长时程楼宇级任务中优于多个基线,这些任务需要排序多达12个真实技能,每次试验跨越15分钟。BUMBLE在不同建筑物、任务和场景布局(从不同的起始房间和楼层开始)的70次试验中,平均成功率达到47.1%。我们的用户研究表明,用户对我们的方法的满意度比最先进的移动操作方法高22%。最后,我们展示了使用日益强大的基础模型来进一步提升性能的潜力。更多信息请参见https://robin-lab.cs.utexas.edu/BUMBLE/。
🔬 方法详解
问题定义:论文旨在解决楼宇级移动操作问题,即服务机器人需要在大型建筑物内完成涉及导航、物体交互等多个步骤的复杂任务。现有方法通常难以处理这种长时程、高复杂度的任务,因为它们缺乏对环境的全面感知、对任务的有效分解以及对多种技能的灵活运用。
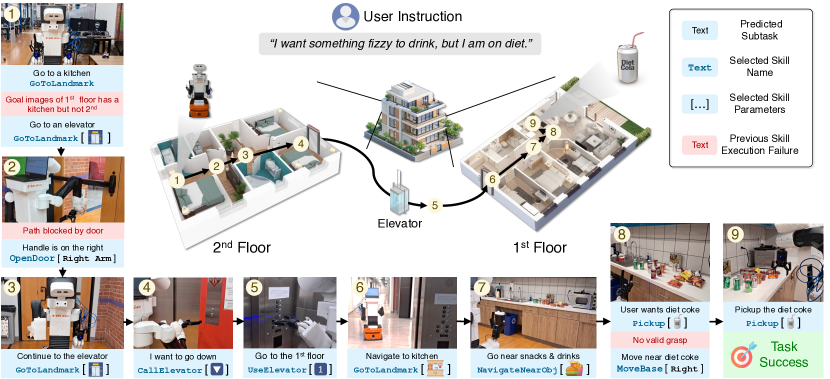
核心思路:BUMBLE的核心思路是利用视觉-语言模型(VLM)将感知、推理和行动统一起来。VLM能够理解自然语言指令,并将其转化为一系列可执行的动作。通过结合RGBD感知,机器人可以理解周围环境;通过集成多种运动技能,机器人可以执行各种操作;通过双层记忆,机器人可以记住任务目标和执行历史,从而更好地完成长时程任务。
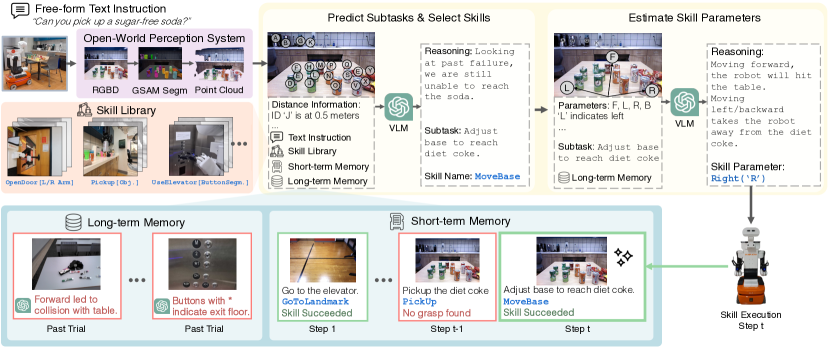
技术框架:BUMBLE框架包含以下几个主要模块:1) 视觉感知模块:利用RGBD相机获取环境信息,并使用VLM进行场景理解和物体识别。2) 任务规划模块:将自然语言指令分解为一系列子任务,并规划执行顺序。3) 运动技能模块:包含多种预定义的运动技能,如导航、抓取、放置等。4) 执行控制模块:根据任务规划,选择合适的运动技能,并控制机器人执行。5) 双层记忆模块:包含短期记忆和长期记忆,用于存储任务目标、执行历史和环境信息。
关键创新:BUMBLE的关键创新在于其统一的基于VLM的框架,能够将感知、推理和行动无缝集成。与传统方法相比,BUMBLE不需要手动设计复杂的规则和策略,而是通过VLM自动学习任务执行策略。此外,BUMBLE的双层记忆机制能够有效地处理长时程任务,提高任务完成的成功率。
关键设计:BUMBLE使用预训练的视觉-语言模型,并针对楼宇级移动操作任务进行微调。运动技能模块包含多种预定义的技能,并使用强化学习进行优化。双层记忆模块使用循环神经网络(RNN)进行建模,并使用注意力机制来选择重要的记忆信息。损失函数包括任务完成损失、技能选择损失和记忆更新损失。
🖼️ 关键图片
📊 实验亮点
BUMBLE在长时程楼宇级任务中表现出色,成功率达到47.1%,显著优于多个基线方法。用户研究表明,用户对BUMBLE的满意度比现有移动操作方法高22%。此外,论文还展示了通过使用更强大的基础模型来进一步提升BUMBLE性能的潜力,预示着未来性能提升的空间。
🎯 应用场景
BUMBLE框架具有广泛的应用前景,可用于开发各种服务机器人,例如:楼宇清洁机器人、物流配送机器人、导览机器人等。该研究的实际价值在于提高了服务机器人在复杂环境中的自主操作能力,降低了人工干预的需求。未来,随着VLM技术的不断发展,BUMBLE框架有望实现更高级别的自主性和智能化。
📄 摘要(原文)
To operate at a building scale, service robots must perform very long-horizon mobile manipulation tasks by navigating to different rooms, accessing different floors, and interacting with a wide and unseen range of everyday objects. We refer to these tasks as Building-wide Mobile Manipulation. To tackle these inherently long-horizon tasks, we introduce BUMBLE, a unified Vision-Language Model (VLM)-based framework integrating open-world RGBD perception, a wide spectrum of gross-to-fine motor skills, and dual-layered memory. Our extensive evaluation (90+ hours) indicates that BUMBLE outperforms multiple baselines in long-horizon building-wide tasks that require sequencing up to 12 ground truth skills spanning 15 minutes per trial. BUMBLE achieves 47.1% success rate averaged over 70 trials in different buildings, tasks, and scene layouts from different starting rooms and floors. Our user study demonstrates 22% higher satisfaction with our method than state-of-the-art mobile manipulation methods. Finally, we demonstrate the potential of using increasingly-capable foundation models to push performance further. For more information, see https://robin-lab.cs.utexas.edu/BUMBLE/