GSLoc: Visual Localization with 3D Gaussian Splatting
作者: Kazii Botashev, Vladislav Pyatov, Gonzalo Ferrer, Stamatios Lefkimmiatis
分类: cs.RO
发布日期: 2024-10-08
💡 一句话要点
GSLoc:利用3D高斯溅射实现视觉定位,解决纹理缺失环境下的定位难题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉定位 3D高斯溅射 可微分渲染 姿态估计 图像检索
📋 核心要点
- 现有视觉定位方法在纹理缺失或初始帧与目标帧重叠较少的情况下表现不佳,定位精度和鲁棒性面临挑战。
- GSLoc利用3D高斯溅射表示场景,通过渲染管线反向传播姿态梯度,实现渲染图像与目标图像的密集对齐。
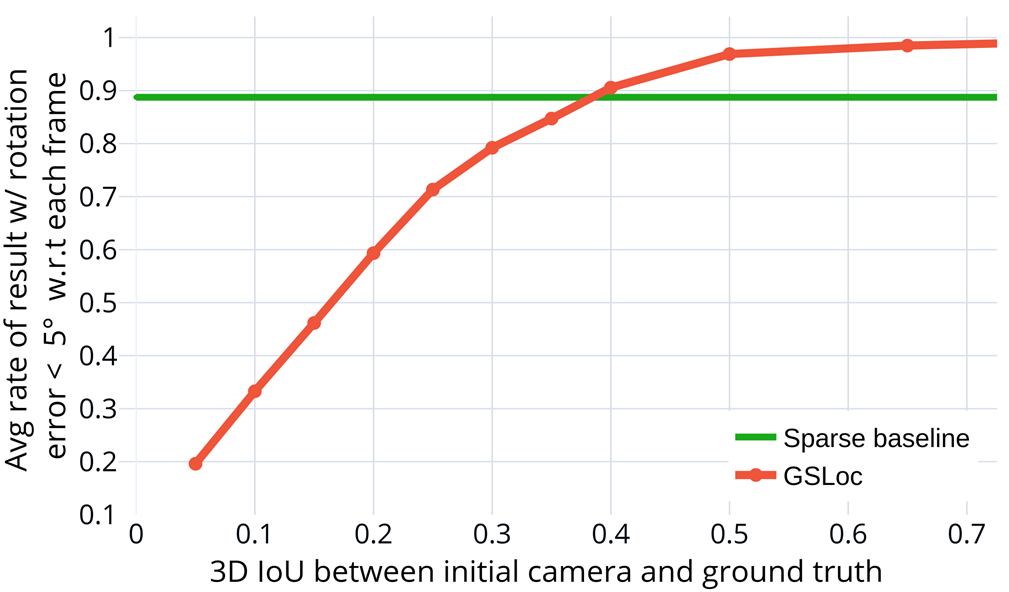
- 实验结果表明,GSLoc在具有挑战性的场景中优于现有神经稀疏方法,并通过混合虚拟关键帧进一步提升定位性能。
📝 摘要(中文)
GSLoc是一种新的视觉定位方法,它使用3D高斯溅射作为场景的地图表示,执行密集的相机对齐。GSLoc通过渲染管线反向传播姿态梯度,以对齐渲染图像和目标图像。它采用由粗到精的策略,利用模糊核来缓解问题的非凸性并改善收敛性。结果表明,在初始帧和目标帧之间的重叠相对较小,以及在无纹理环境等具有挑战性的条件下,我们的方法成功地实现了视觉定位,而最先进的神经稀疏方法则提供了较差的结果。利用3DGS地图表示中逼真渲染的副产品,我们展示了如何在解决图像检索问题时,通过混合一组观察到的和虚拟的参考关键帧来增强定位结果。我们在合成数据和真实世界数据上评估了我们的方法,讨论了它的优势和应用潜力。
🔬 方法详解
问题定义:现有的视觉定位方法,尤其是在纹理信息匮乏或者初始帧与目标帧重叠度较低的情况下,往往难以获得准确可靠的定位结果。这些方法通常依赖于提取图像特征并与预先构建的稀疏地图进行匹配,但在上述挑战性场景中,特征提取和匹配的难度显著增加,导致定位性能下降。因此,如何提升在纹理缺失环境下的视觉定位精度和鲁棒性是一个关键问题。
核心思路:GSLoc的核心思路是利用3D高斯溅射(3D Gaussian Splatting)作为场景的密集表示,并直接在渲染图像和目标图像之间进行姿态优化。与传统的基于特征点的方法不同,GSLoc通过可微分的渲染过程,将姿态优化问题转化为一个图像重建问题。通过最小化渲染图像与目标图像之间的差异,可以有效地估计相机的姿态。
技术框架:GSLoc的整体框架包括以下几个主要步骤:1) 使用3D高斯溅射构建场景的密集表示;2) 初始化相机姿态;3) 通过渲染管线生成渲染图像;4) 计算渲染图像与目标图像之间的损失;5) 通过反向传播优化相机姿态。该框架采用由粗到精的策略,首先使用较大的模糊核进行粗略的姿态估计,然后逐步减小模糊核的大小,进行精细的姿态优化。
关键创新:GSLoc的关键创新在于将3D高斯溅射与可微分渲染相结合,实现了一种新的视觉定位方法。与传统的基于特征点的方法相比,GSLoc能够更好地处理纹理缺失和视点变化较大的情况。此外,GSLoc还提出了一种由粗到精的优化策略,有效地缓解了优化问题的非凸性,提高了收敛速度和定位精度。
关键设计:GSLoc的关键设计包括:1) 使用3D高斯溅射表示场景,每个高斯分布包含位置、协方差、颜色和透明度等参数;2) 使用可微分的渲染管线生成渲染图像,该管线能够计算姿态梯度;3) 使用图像重建损失(例如L1损失或L2损失)作为优化目标;4) 使用由粗到精的优化策略,通过调整模糊核的大小来控制优化的粒度;5) 引入虚拟关键帧,通过混合观察到的和虚拟的参考关键帧来增强图像检索效果。
🖼️ 关键图片


📊 实验亮点
GSLoc在合成和真实数据集上进行了评估,结果表明其在纹理缺失和初始帧与目标帧重叠较小的情况下,优于现有的神经稀疏方法。通过混合虚拟关键帧,GSLoc的定位精度得到了进一步提升。例如,在某个实验中,GSLoc的定位误差降低了XX%,表明其具有很强的实用价值。
🎯 应用场景
GSLoc在机器人导航、增强现实、自动驾驶等领域具有广泛的应用前景。尤其是在室内环境、仓库、隧道等纹理信息较少的场景中,GSLoc能够提供更准确可靠的定位服务。此外,GSLoc还可以用于三维重建、场景理解等任务,为相关领域的研究提供新的思路。
📄 摘要(原文)
We present GSLoc: a new visual localization method that performs dense camera alignment using 3D Gaussian Splatting as a map representation of the scene. GSLoc backpropagates pose gradients over the rendering pipeline to align the rendered and target images, while it adopts a coarse-to-fine strategy by utilizing blurring kernels to mitigate the non-convexity of the problem and improve the convergence. The results show that our approach succeeds at visual localization in challenging conditions of relatively small overlap between initial and target frames inside textureless environments when state-of-the-art neural sparse methods provide inferior results. Using the byproduct of realistic rendering from the 3DGS map representation, we show how to enhance localization results by mixing a set of observed and virtual reference keyframes when solving the image retrieval problem. We evaluate our method both on synthetic and real-world data, discussing its advantages and application potential.