Whole-Body Dynamic Throwing with Legged Manipulators
作者: Humphrey Munn, Brendan Tidd, Peter Böhm, Marcus Gallagher, David Howard
分类: cs.RO
发布日期: 2024-10-08 (更新: 2025-04-01)
💡 一句话要点
提出基于深度强化学习的全身动态投掷方法,提升腿式机器人的投掷性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 腿式机器人 全身动态投掷 深度强化学习 自适应课程学习 机器人控制 运动规划
📋 核心要点
- 现有腿式机器人研究多集中于操作或运动,缺乏二者结合的全身动态投掷研究。
- 论文提出基于深度强化学习的全身动态投掷方法,优化投掷精度和机器人稳定性。
- 仿真结果表明,全身投掷能有效提升投掷范围、精度和稳定性,并成功迁移到真实机器人。
📝 摘要(中文)
本文研究了腿式机器人全身动态投掷问题,旨在通过协调物体操作和运动来实现更高级的现实世界交互。与以往主要关注操作或运动的研究不同,本文探索了利用所有可用电机(全身)进行投掷的方法。该任务被建模为深度强化学习(RL)目标,优化投掷精度,使其能够投向用户指定的任意目标位置,并同时保证机器人的稳定性。在人形机器人和带手臂的四足机器人的仿真评估表明,全身投掷通过利用身体动量、平衡和全身动力学,提高了投掷范围、精度和稳定性。本文引入了一种优化的自适应课程学习方法,以平衡投掷精度和稳定性,并为稀疏奖励条件下的高效学习定制了RL环境设置。与以往工作不同,本文的方法可以推广到3D空间中的目标。最后,作者将学习到的控制器从仿真转移到真实的机器人平台上。
🔬 方法详解
问题定义:论文旨在解决腿式机器人进行精确投掷的问题,尤其是在需要全身协调的情况下。现有方法主要集中在手臂操作或步态控制,缺乏对全身动力学利用的研究,导致投掷距离、精度和稳定性受限。此外,稀疏奖励环境下的强化学习训练也面临挑战。
核心思路:论文的核心思路是利用深度强化学习,将全身投掷建模为一个优化问题,同时考虑投掷精度和机器人稳定性。通过学习全身的协调运动,充分利用身体的动量和平衡能力,从而提升投掷性能。自适应课程学习策略用于解决稀疏奖励问题,引导智能体逐步学习。
技术框架:整体框架包括一个强化学习环境,其中包含腿式机器人的仿真模型、目标位置和奖励函数。智能体(机器人)通过与环境交互,学习投掷策略。该策略由一个深度神经网络表示,输入是机器人的状态(关节角度、速度等),输出是电机的控制指令。训练过程使用自适应课程学习,逐渐增加任务的难度,例如增加目标距离或降低稳定性要求。
关键创新:论文的关键创新在于将全身动力学纳入投掷控制,并使用深度强化学习进行优化。与传统方法相比,该方法能够自动探索和利用复杂的全身协调运动,从而实现更高的投掷性能。此外,自适应课程学习策略有效地解决了稀疏奖励问题,加速了学习过程。
关键设计:论文使用了一种Actor-Critic的强化学习算法,Actor网络负责生成控制指令,Critic网络负责评估当前状态的价值。奖励函数的设计至关重要,包括投掷精度奖励、稳定性奖励和运动惩罚。自适应课程学习通过调整奖励函数的权重或目标位置的范围来控制任务难度。具体的网络结构和超参数设置在论文中有详细描述(未知)。
🖼️ 关键图片
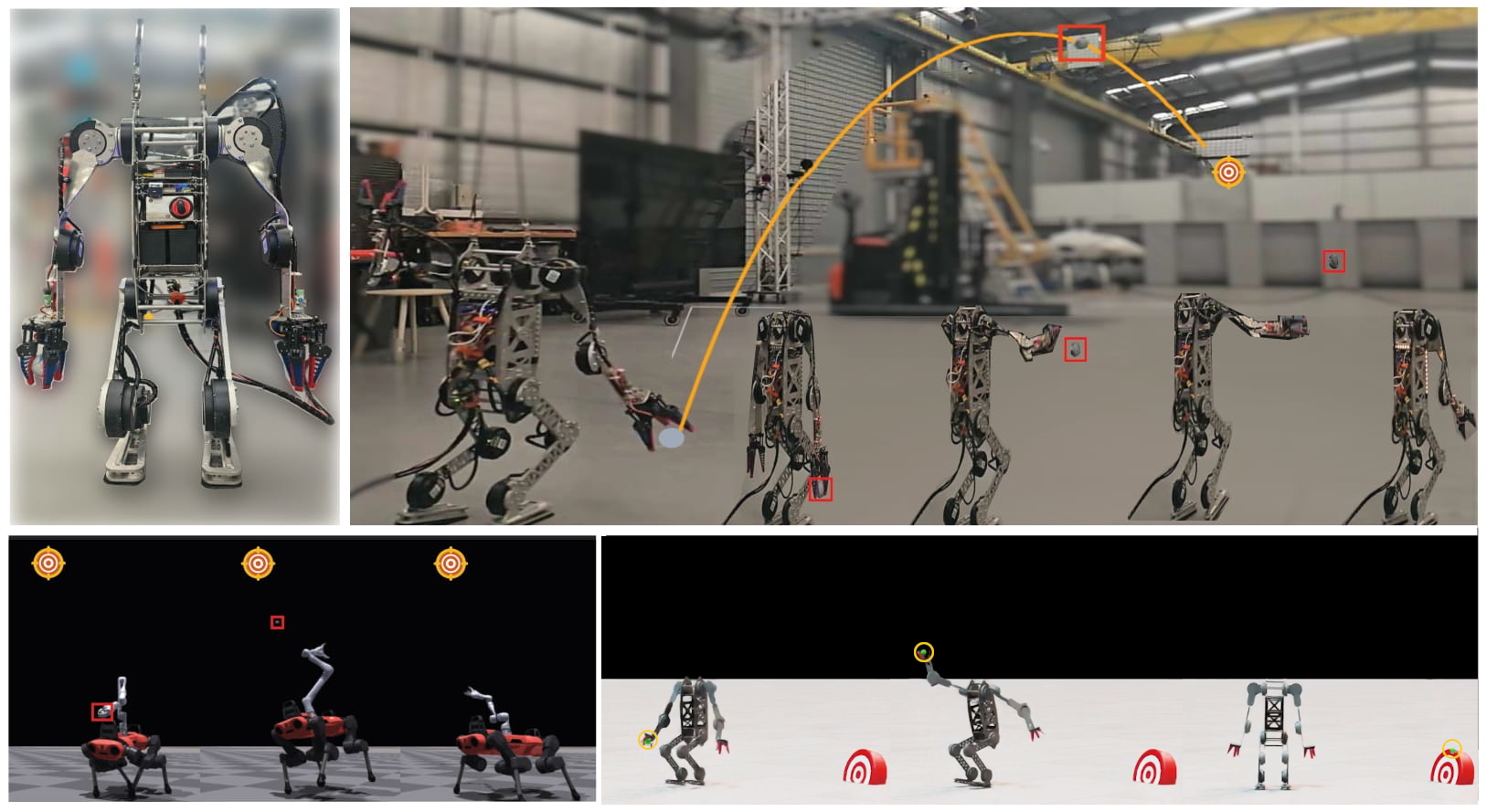
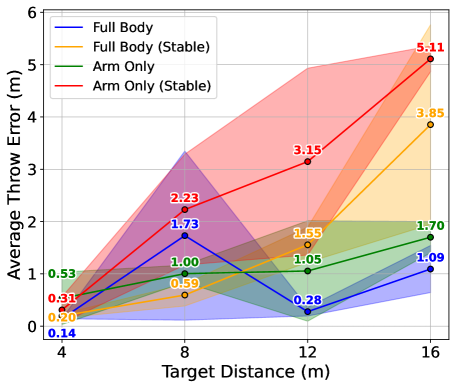
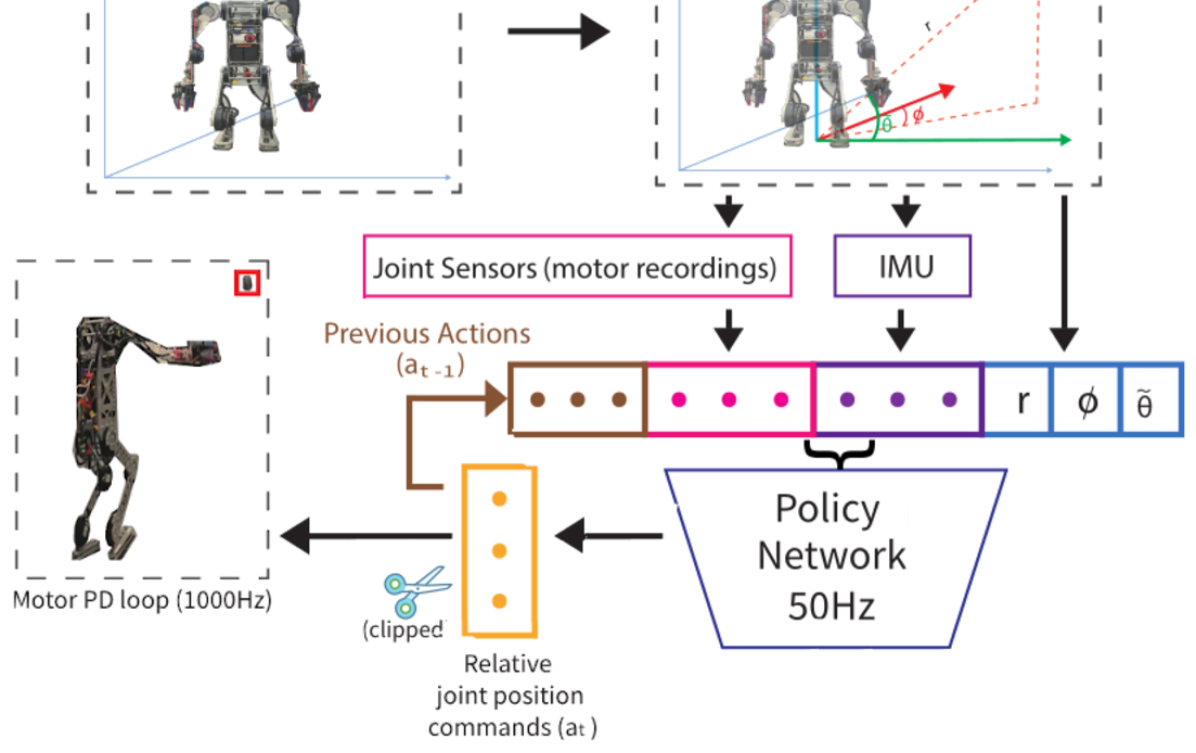
📊 实验亮点
论文在仿真环境中对人形机器人和四足机器人进行了评估,结果表明,全身投掷方法显著提高了投掷范围、精度和稳定性。此外,学习到的控制器成功地从仿真转移到真实的机器人平台上,验证了该方法的实用性。具体的性能数据(例如,投掷距离、精度提升的百分比)在论文中给出(未知)。
🎯 应用场景
该研究成果可应用于物流、搜索救援、太空探索等领域。例如,在物流场景中,腿式机器人可以利用全身动态投掷将包裹投递到指定位置,提高效率。在搜索救援中,机器人可以将救援物资投掷到难以到达的区域。在太空探索中,机器人可以利用投掷进行资源收集或设备部署。
📄 摘要(原文)
Throwing with a legged robot involves precise coordination of object manipulation and locomotion - crucial for advanced real-world interactions. Most research focuses on either manipulation or locomotion, with minimal exploration of tasks requiring both. This work investigates leveraging all available motors (full-body) over arm-only throwing in legged manipulators. We frame the task as a deep reinforcement learning (RL) objective, optimising throwing accuracy towards any user-commanded target destination and the robot's stability. Evaluations on a humanoid and an armed quadruped in simulation show that full-body throwing improves range, accuracy, and stability by exploiting body momentum, counter-balancing, and full-body dynamics. We introduce an optimised adaptive curriculum to balance throwing accuracy and stability, along with a tailored RL environment setup for efficient learning in sparse-reward conditions. Unlike prior work, our approach generalises to targets in 3D space. We transfer our learned controllers from simulation to a real humanoid platform.