Goal-Conditioned Terminal Value Estimation for Real-time and Multi-task Model Predictive Control
作者: Mitsuki Morita, Satoshi Yamamori, Satoshi Yagi, Norikazu Sugimoto, Jun Morimoto
分类: cs.RO, cs.LG, eess.SY
发布日期: 2024-10-07 (更新: 2024-10-08)
备注: 16 pages, 9 figures
💡 一句话要点
提出目标条件终端价值学习MPC框架,实现实时多任务控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 终端价值学习 目标条件控制 多任务学习 分层控制
📋 核心要点
- 传统MPC计算量大,难以实时优化策略,限制了其在复杂动态环境中的应用。
- 论文提出目标条件终端价值学习方法,结合分层控制结构,降低MPC计算成本,实现多任务控制。
- 实验表明,该方法在双足倒立摆机器人模型上实现了实时控制,并成功跟踪了倾斜地形上的目标轨迹。
📝 摘要(中文)
模型预测控制(MPC)通过在每个时间步求解最优控制问题来实现非线性反馈控制,但计算负担通常很大,难以在控制周期内优化策略。为了解决这个问题,一种可能的方法是利用终端价值学习来降低计算成本。然而,在任务动态变化的情况下,学习到的价值不能用于原始MPC设置中的其他任务。本研究开发了一个具有目标条件终端价值学习的MPC框架,以实现多任务策略优化,同时减少计算时间。此外,通过使用分层控制结构,允许上层轨迹规划器输出适当的目标条件轨迹,我们证明了机器人模型能够生成不同的运动。我们在双足倒立摆机器人模型上评估了所提出的方法,并证实将目标条件终端价值学习与上层轨迹规划器相结合能够实现实时控制;因此,机器人成功地跟踪了倾斜地形上的目标轨迹。
🔬 方法详解
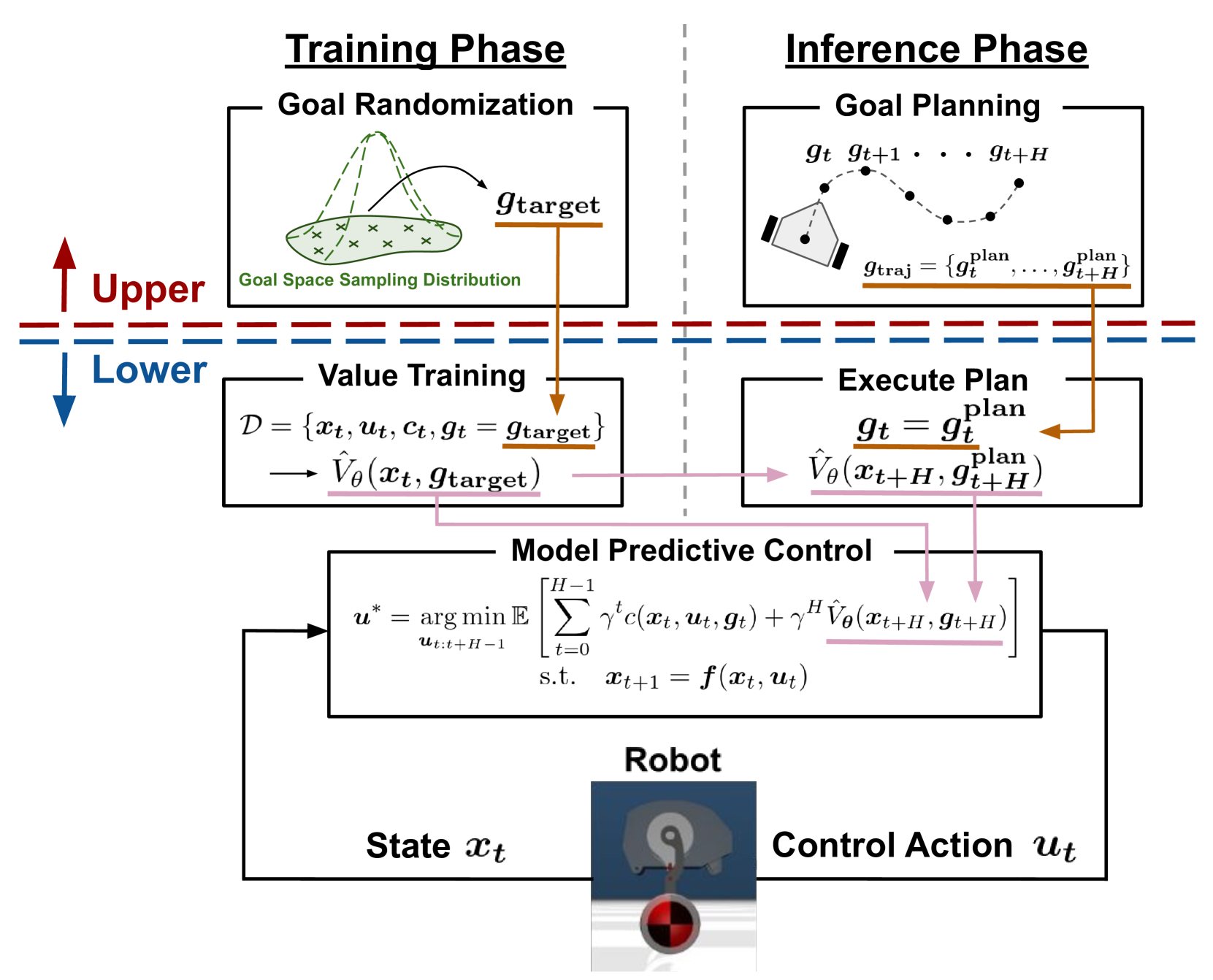
问题定义:传统MPC在每个时间步都需要求解复杂的优化问题,计算量大,难以满足实时性要求,尤其是在任务动态变化的情况下,需要重新优化,效率低下。此外,学习到的终端价值难以泛化到不同的任务目标。
核心思路:论文的核心思路是利用目标条件终端价值学习来加速MPC的计算过程,并提高其泛化能力。通过学习一个与目标相关的终端价值函数,MPC可以在规划过程中快速评估不同轨迹的优劣,从而减少在线优化的计算量。同时,结合分层控制结构,上层轨迹规划器负责生成目标条件轨迹,下层MPC负责跟踪这些轨迹,从而实现多任务控制。
技术框架:该方法采用分层控制结构。上层是轨迹规划器,负责根据任务目标生成一系列目标点,这些目标点构成了下层MPC的目标条件。下层是目标条件MPC,它利用学习到的目标条件终端价值函数来评估不同轨迹的优劣,并选择最优轨迹进行控制。整个框架包含以下主要模块:目标条件轨迹生成器、目标条件MPC控制器、目标条件终端价值函数学习器。
关键创新:该方法最重要的技术创新点在于将目标条件终端价值学习与MPC相结合。传统的终端价值学习方法通常只适用于单一任务,而该方法通过引入目标条件,使得学习到的终端价值函数可以泛化到不同的任务目标。此外,分层控制结构也使得整个系统更加模块化和易于扩展。
关键设计:目标条件终端价值函数通常使用神经网络来表示,输入是当前状态和目标状态,输出是终端价值。损失函数通常采用时序差分学习的损失函数,例如TD-error。轨迹规划器可以使用各种方法,例如RRT、PRM等。MPC的优化算法可以使用各种现成的优化器,例如IPOPT、OSQP等。关键参数包括神经网络的结构、学习率、MPC的控制周期、预测步长等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在双足倒立摆机器人模型上实现了实时控制,机器人能够成功跟踪倾斜地形上的目标轨迹。与传统的MPC方法相比,该方法显著降低了计算时间,并提高了控制系统的鲁棒性。具体而言,该方法可以将计算时间降低到原来的1/N(N为预测步长),从而满足实时性要求。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、无人机等领域,尤其适用于需要在复杂动态环境中进行实时多任务控制的场景。例如,机器人可以在不同的地形上行走,自动驾驶车辆可以在不同的交通状况下行驶,无人机可以在不同的天气条件下飞行。该方法可以提高控制系统的实时性和鲁棒性,并降低计算成本,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
While MPC enables nonlinear feedback control by solving an optimal control problem at each timestep, the computational burden tends to be significantly large, making it difficult to optimize a policy within the control period. To address this issue, one possible approach is to utilize terminal value learning to reduce computational costs. However, the learned value cannot be used for other tasks in situations where the task dynamically changes in the original MPC setup. In this study, we develop an MPC framework with goal-conditioned terminal value learning to achieve multitask policy optimization while reducing computational time. Furthermore, by using a hierarchical control structure that allows the upper-level trajectory planner to output appropriate goal-conditioned trajectories, we demonstrate that a robot model is able to generate diverse motions. We evaluate the proposed method on a bipedal inverted pendulum robot model and confirm that combining goal-conditioned terminal value learning with an upper-level trajectory planner enables real-time control; thus, the robot successfully tracks a target trajectory on sloped terrain.