Next Best Sense: Guiding Vision and Touch with FisherRF for 3D Gaussian Splatting
作者: Matthew Strong, Boshu Lei, Aiden Swann, Wen Jiang, Kostas Daniilidis, Monroe Kennedy
分类: cs.RO, cs.CV
发布日期: 2024-10-07 (更新: 2025-03-09)
备注: To appear in International Conference on Robotics and Automation (ICRA) 2025
💡 一句话要点
提出基于FisherRF的视角与触觉引导方法,提升3D高斯溅射在机器人操作中的性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D高斯溅射 机器人操作 主动视角选择 深度不确定性 语义深度对齐
📋 核心要点
- 现有3DGS方法在视角有限的在线机器人场景中,由于视角冗余和重叠,随机视角选择效率低下。
- 提出一种端到端的在线训练和主动视角选择流程,结合语义深度对齐和深度不确定性估计,优化3DGS性能。
- 在真实机器人系统上验证了该方法,通过实验证明其在少视角场景下能显著提升3DGS的重建质量。
📝 摘要(中文)
本文提出了一种主动选择最佳视角和触碰位置的框架,用于机器人操作臂,该框架基于3D高斯溅射(3DGS)。3DGS正逐渐成为机器人领域一种有用的显式3D场景表示方法,因为它能够以逼真的照片质量和几何精度表示场景。然而,在实际的在线机器人场景中,由于效率要求,视角数量有限,随机选择视角变得不切实际,因为视角通常重叠且冗余。为了解决这个问题,我们提出了一个端到端的在线训练和主动视角选择流程,从而增强了3DGS在少视角机器人环境中的性能。我们首先使用一种新颖的语义深度对齐方法(使用Segment Anything Model 2 (SAM2))来提升少样本3DGS的性能,并辅以Pearson深度和表面法线损失,以改善真实场景的颜色和深度重建。然后,我们扩展了FisherRF(一种用于3DGS的最佳视角选择方法),以基于深度不确定性选择视角和触碰姿势。我们在实时3DGS训练期间,在真实的机器人系统上执行在线视角选择。我们论证了对少样本GS场景的改进,并将基于深度的FisherRF扩展到这些场景,从而在具有挑战性的机器人场景中展示了定性和定量的改进。
🔬 方法详解
问题定义:论文旨在解决在视角受限的在线机器人场景中,如何高效地利用3D高斯溅射(3DGS)进行场景重建和操作规划的问题。现有方法,特别是随机视角选择,在这些场景下效率低下,因为视角之间存在大量冗余信息,导致重建质量提升缓慢。
核心思路:论文的核心思路是主动选择信息量最大的视角和触碰位置,以最小化深度不确定性,从而提高3DGS的重建质量和操作性能。通过结合语义信息和深度不确定性估计,引导机器人选择最佳的观测点,避免冗余观测,加速场景理解。
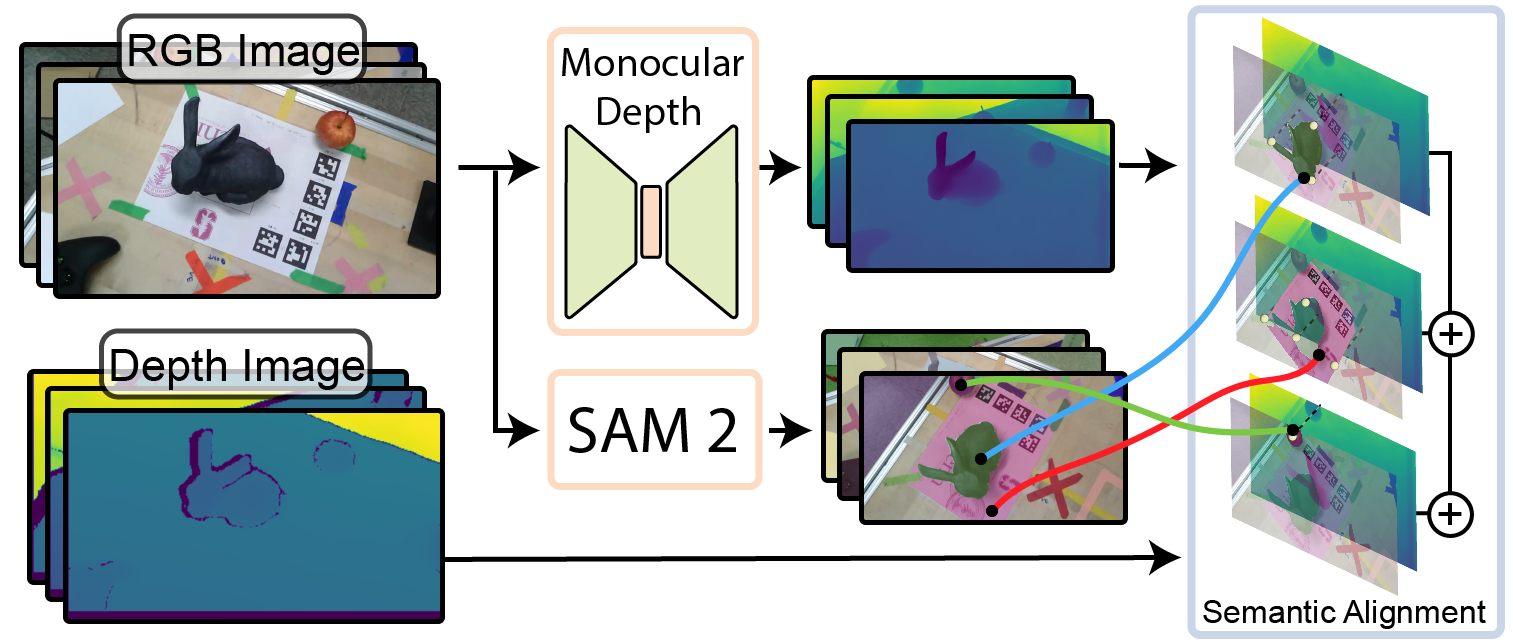
技术框架:整体框架包含以下几个主要模块:1) 基于Segment Anything Model 2 (SAM2) 的语义深度对齐模块,用于提升少样本3DGS的初始重建质量。2) Pearson深度和表面法线损失,用于进一步优化颜色和深度重建。3) 基于深度不确定性的FisherRF扩展模块,用于主动选择下一个最佳视角和触碰位置。4) 在线3DGS训练模块,用于实时更新场景表示。
关键创新:论文的关键创新在于将FisherRF扩展到基于深度不确定性的视角和触碰位置选择,并将其应用于在线3DGS训练中。此外,利用SAM2进行语义深度对齐,显著提升了少样本3DGS的重建效果。与传统方法相比,该方法能够更有效地利用有限的视角信息,实现更精确的场景重建。
关键设计:语义深度对齐模块利用SAM2提取图像中的语义分割信息,并将其与深度信息对齐,从而提高深度估计的准确性。Pearson深度损失用于衡量预测深度与真实深度之间的相关性,表面法线损失用于约束重建表面的平滑性。FisherRF的扩展基于深度不确定性,选择能够最大程度降低不确定性的视角和触碰位置。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文在真实机器人场景中进行了实验验证,结果表明,所提出的方法能够显著提升少视角3DGS的重建质量。通过结合语义深度对齐和深度不确定性估计,该方法能够更有效地利用有限的视角信息,实现更精确的场景重建。具体的性能数据和提升幅度在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于机器人自主导航、物体抓取、场景理解等领域。通过主动选择最佳视角,机器人能够更高效地构建精确的3D场景模型,从而提高操作的准确性和效率。未来,该技术有望应用于工业自动化、家庭服务机器人等领域,实现更智能、更可靠的机器人操作。
📄 摘要(原文)
We propose a framework for active next best view and touch selection for robotic manipulators using 3D Gaussian Splatting (3DGS). 3DGS is emerging as a useful explicit 3D scene representation for robotics, as it has the ability to represent scenes in a both photorealistic and geometrically accurate manner. However, in real-world, online robotic scenes where the number of views is limited given efficiency requirements, random view selection for 3DGS becomes impractical as views are often overlapping and redundant. We address this issue by proposing an end-to-end online training and active view selection pipeline, which enhances the performance of 3DGS in few-view robotics settings. We first elevate the performance of few-shot 3DGS with a novel semantic depth alignment method using Segment Anything Model 2 (SAM2) that we supplement with Pearson depth and surface normal loss to improve color and depth reconstruction of real-world scenes. We then extend FisherRF, a next-best-view selection method for 3DGS, to select views and touch poses based on depth uncertainty. We perform online view selection on a real robot system during live 3DGS training. We motivate our improvements to few-shot GS scenes, and extend depth-based FisherRF to them, where we demonstrate both qualitative and quantitative improvements on challenging robot scenes. For more information, please see our project page at https://arm.stanford.edu/next-best-sense.