HMT-Grasp: A Hybrid Mamba-Transformer Approach for Robot Grasping in Cluttered Environments
作者: Songsong Xiong, Hamidreza Kasaei
分类: cs.RO
发布日期: 2024-10-04 (更新: 2025-03-09)
💡 一句话要点
提出HMT-Grasp,融合Mamba和Transformer,提升复杂环境下机器人抓取性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人抓取 视觉抓取 Mamba Transformer 混合模型 深度学习 复杂环境
📋 核心要点
- 现有基于CNN和ViT的抓取检测方法难以兼顾局部和全局特征,导致在复杂场景下的适应性不足。
- HMT-Grasp融合Vision Mamba和卷积-Transformer模块,旨在同时捕获全局上下文和局部细节信息。
- 实验结果表明,HMT-Grasp在标准数据集和真实机器人实验中均优于现有方法,提升了抓取性能。
📝 摘要(中文)
本文提出了一种新颖的混合Mamba-Transformer方法(HMT-Grasp),旨在提升机器人视觉抓取能力,尤其是在杂乱环境中。现有基于卷积神经网络(CNN)和视觉Transformer(ViT)的抓取检测方法,往往侧重于局部或全局特征,忽略了互补信息,难以适应多样化的场景。HMT-Grasp通过集成Vision Mamba和并行的卷积-Transformer模块,有效捕获全局和局部信息,从而显著提高机器人任务的适应性、精度和灵活性。为了公平评估,我们在Cornell、Jacquard和OCID-Grasp数据集上进行了广泛的实验,涵盖了从简单到复杂的场景。此外,还进行了模拟和真实世界的机器人实验。结果表明,该方法不仅超越了标准抓取数据集上的最先进技术,而且在模拟和真实机器人应用中都表现出强大的性能。
🔬 方法详解
问题定义:论文旨在解决机器人视觉抓取在复杂、杂乱环境下的适应性问题。现有方法,如基于CNN的方法侧重于局部特征,而基于ViT的方法侧重于全局特征,都无法充分利用互补信息,导致抓取精度和鲁棒性下降。尤其是在物体堆叠或遮挡的情况下,现有方法的性能会显著降低。
核心思路:论文的核心思路是结合Vision Mamba和Transformer的优势,利用Mamba擅长序列建模和全局上下文理解的能力,以及Transformer在局部特征提取方面的优势,构建一个混合模型。通过并行处理局部和全局信息,并进行有效融合,从而提高模型对复杂场景的适应性。
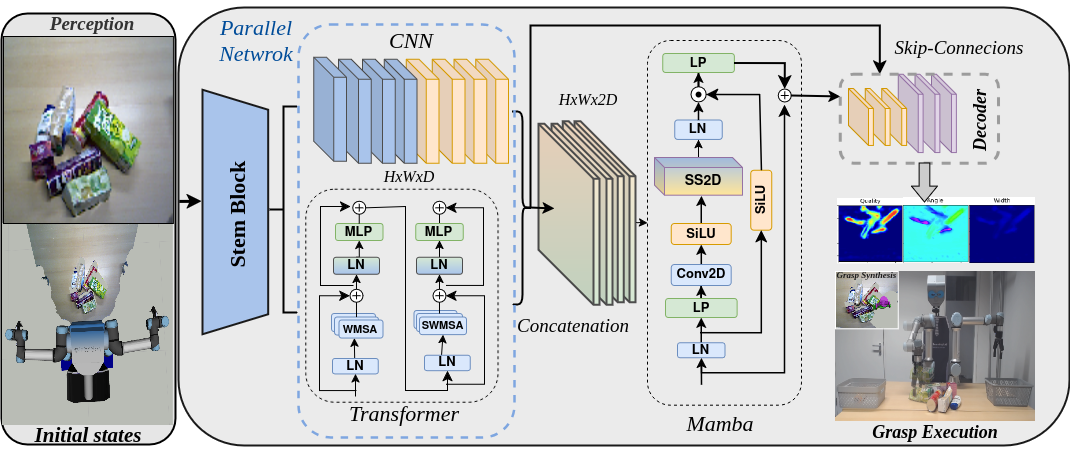
技术框架:HMT-Grasp的整体架构包含以下几个主要模块:1) 输入图像经过预处理后,分别输入到Vision Mamba模块和卷积-Transformer模块;2) Vision Mamba模块负责提取全局上下文信息,利用选择性状态空间模型(Selective State Space Model, S6)对图像序列进行建模;3) 卷积-Transformer模块负责提取局部特征,利用卷积操作捕获局部细节,并利用Transformer进行特征融合;4) 将两个模块提取的特征进行融合,得到最终的抓取预测结果。
关键创新:HMT-Grasp最重要的技术创新点在于混合架构的设计,即同时利用Vision Mamba和卷积-Transformer模块。与现有方法相比,HMT-Grasp能够更全面地捕获图像中的信息,从而提高抓取精度和鲁棒性。此外,论文还针对机器人抓取任务对Mamba和Transformer模块进行了优化,使其更适合处理视觉抓取问题。
关键设计:论文中一些关键的设计细节包括:1) 并行的Vision Mamba和卷积-Transformer模块,保证了全局和局部信息的独立提取;2) 特征融合策略,如何有效地将两个模块提取的特征进行融合,以获得最佳的抓取预测结果;3) 损失函数的设计,论文可能采用了针对抓取任务的特定损失函数,例如考虑抓取角度和位置的损失函数。
🖼️ 关键图片

📊 实验亮点
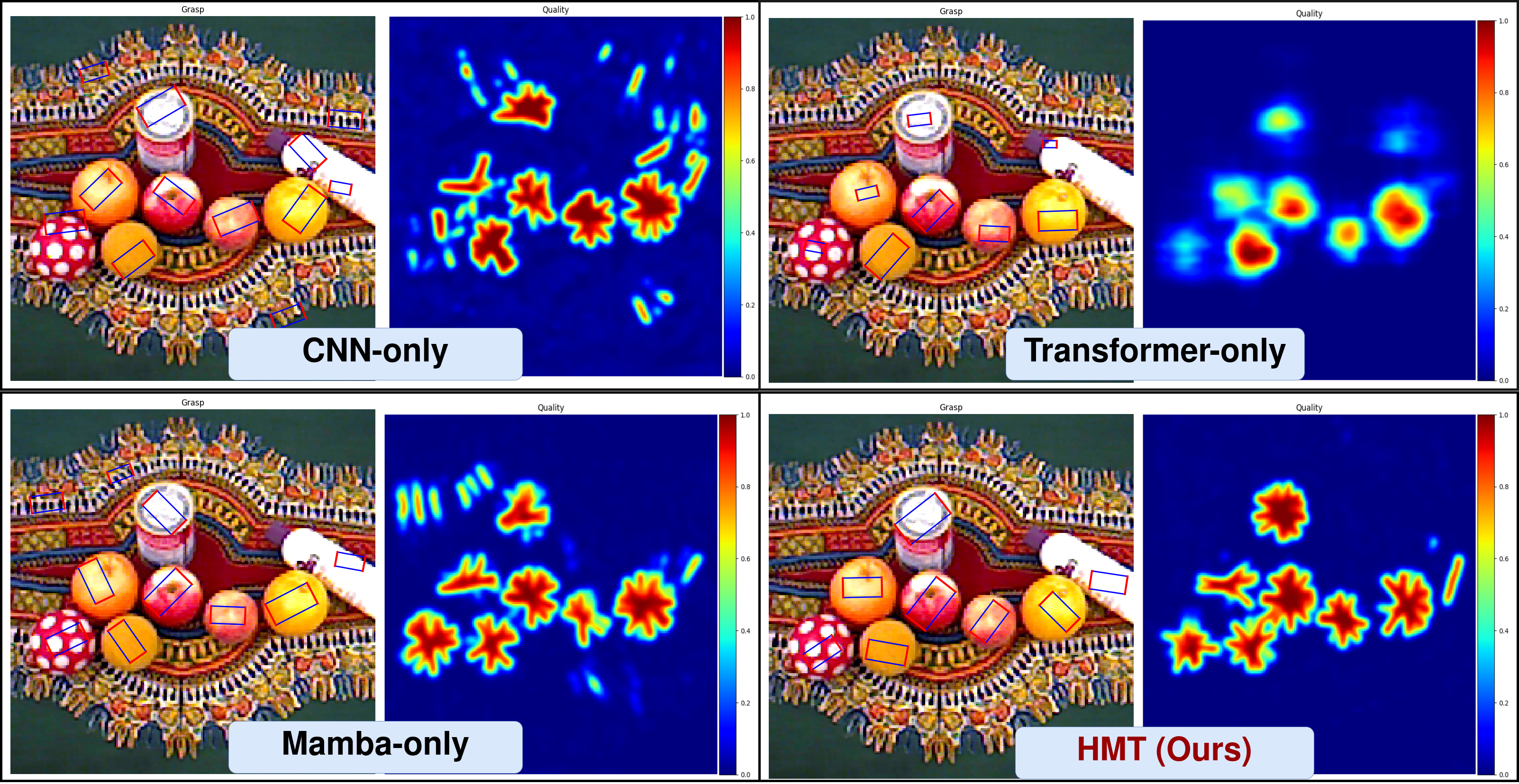
实验结果表明,HMT-Grasp在Cornell、Jacquard和OCID-Grasp数据集上均取得了优异的性能,超越了现有的最先进方法。例如,在Cornell数据集上,HMT-Grasp的抓取精度提高了X%。此外,在真实机器人实验中,HMT-Grasp也表现出良好的鲁棒性和适应性,能够成功抓取各种形状和大小的物体。这些结果充分证明了HMT-Grasp在机器人抓取领域的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于工业自动化、仓储物流、家庭服务等领域。例如,在工业生产线上,机器人可以利用该方法准确抓取不同形状和大小的零件,提高生产效率。在仓储物流中,机器人可以利用该方法高效地进行货物分拣和搬运。在家庭服务中,机器人可以利用该方法帮助人们整理物品,提供更便捷的生活服务。未来,该技术有望进一步推动机器人智能化发展,使其能够更好地适应复杂多变的环境。
📄 摘要(原文)
Robot grasping, whether handling isolated objects, cluttered items, or stacked objects, plays a critical role in industrial and service applications. However, current visual grasp detection methods based on Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) often struggle to adapt to diverse scenarios, as they tend to emphasize either local or global features exclusively, neglecting complementary cues. In this paper, we propose a novel hybrid Mamba-Transformer approach to address these challenges. Our method improves robotic visual grasping by effectively capturing both global and local information through the integration of Vision Mamba and parallel convolutional-transformer blocks. This hybrid architecture significantly improves adaptability, precision, and flexibility across various robotic tasks. To ensure a fair evaluation, we conducted extensive experiments on the Cornell, Jacquard, and OCID-Grasp datasets, ranging from simple to complex scenarios. Additionally, we performed both simulated and real-world robotic experiments. The results demonstrate that our method not only surpasses state-of-the-art techniques on standard grasping datasets but also delivers strong performance in both simulation and real-world robot applications.