Residual Policy Learning for Perceptive Quadruped Control Using Differentiable Simulation
作者: Jing Yuan Luo, Yunlong Song, Victor Klemm, Fan Shi, Davide Scaramuzza, Marco Hutter
分类: cs.RO
发布日期: 2024-10-04
💡 一句话要点
提出基于可微仿真的残差策略学习方法,提升四足机器人感知控制性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 四足机器人 强化学习 残差策略学习 可微仿真 运动控制 感知导航 一阶策略梯度
📋 核心要点
- 一阶策略梯度算法在接触丰富的任务中学习动态较差,现有方法主要通过缓解接触动力学问题来解决。
- 本文提出残差策略学习,通过学习基线策略的残差来引导策略搜索,提升渐近奖励。
- 实验表明,该方法能快速训练四足机器人完成运动和感知导航任务,并提升了性能。
📝 摘要(中文)
本文提出了一种基于可微仿真的残差策略学习(FoPG RPL)方法,用于提升四足机器人的感知控制性能。一阶策略梯度(FoPG)算法,如时间反向传播和解析策略梯度,利用局部仿真物理来加速策略搜索,与标准的无模型强化学习相比,显著提高了机器人控制的样本效率。然而,FoPG算法在像步态运动这样接触丰富的任务中可能表现出较差的学习动态。以往的方法通过算法或仿真创新来缓解接触动力学问题。相比之下,我们建议通过学习一个基于简单基线策略的残差来引导策略搜索。对于四足运动,我们发现FoPG RPL的主要作用是提高渐近奖励,而不是提高无模型强化学习的样本效率。此外,我们还提供了将FoPG应用于基于像素的局部导航的见解,在几秒钟内训练一个质点机器人收敛。最后,我们展示了FoPG RPL的多功能性,通过使用它在几分钟内端到端地训练四足机器人的运动和感知导航。
🔬 方法详解
问题定义:现有的基于一阶策略梯度(FoPG)的强化学习方法在四足机器人等接触丰富的运动控制任务中,学习动态较差,难以获得理想的控制策略。虽然可以通过改进算法或仿真来缓解接触动力学问题,但这些方法可能不够通用或高效。
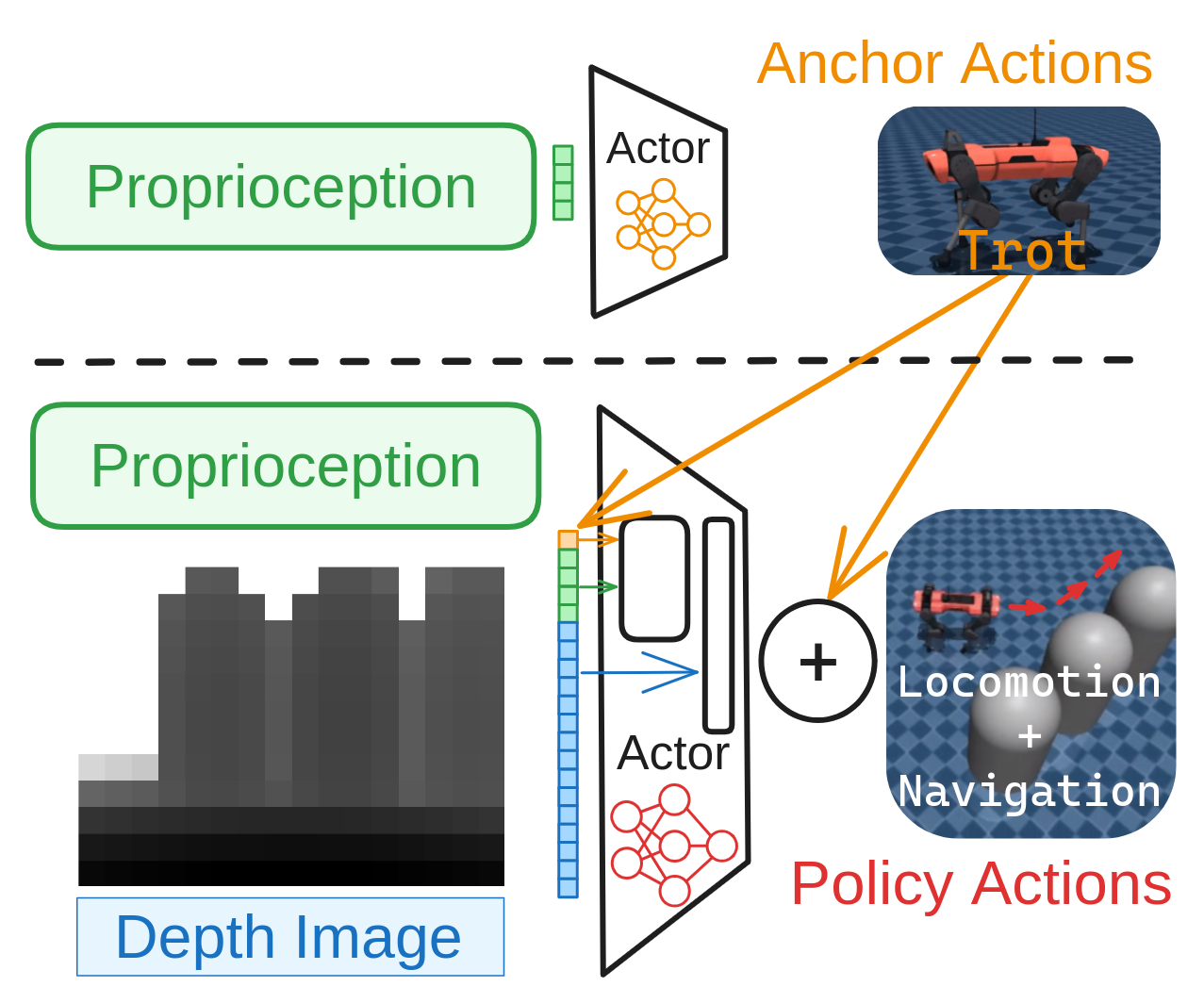
核心思路:本文的核心思路是利用残差策略学习(RPL)来引导策略搜索。具体来说,不是直接学习完整的控制策略,而是学习一个作用于简单基线策略之上的残差策略。这样可以利用基线策略的先验知识,简化学习过程,并提高学习效率。
技术框架:整体框架包括以下几个主要部分:1) 一个简单的基线策略,例如预定义的步态或简单的导航策略。2) 一个残差策略网络,用于学习对基线策略的修正。3) 一个可微的物理仿真器,用于评估策略的性能并计算梯度。4) 一个优化器,用于更新残差策略网络的参数。整个训练过程通过可微仿真进行端到端优化。
关键创新:最重要的创新点在于将残差策略学习与一阶策略梯度方法相结合。与直接学习策略相比,残差策略学习可以更有效地利用先验知识,并简化学习过程。此外,通过可微仿真进行端到端训练,可以充分利用梯度信息,提高学习效率。
关键设计:基线策略的选择至关重要,需要根据具体任务进行设计。残差策略网络可以使用各种神经网络结构,例如多层感知机或循环神经网络。损失函数通常包括奖励函数和正则化项,用于鼓励策略的平滑性和稳定性。一阶策略梯度算法,如时间反向传播(BPTT)或解析策略梯度(APG),用于计算梯度并更新网络参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的FoPG RPL方法可以显著提高四足机器人的运动控制性能。例如,在四足运动任务中,FoPG RPL能够获得更高的渐近奖励,表明其学习到的策略更优。此外,该方法还可以在几分钟内端到端地训练四足机器人完成运动和感知导航任务,展示了其高效性和多功能性。在基于像素的局部导航任务中,质点机器人可以在几秒内训练至收敛。
🎯 应用场景
该研究成果可应用于各种四足机器人的运动控制和导航任务,例如搜索救援、物流运输、巡检等。通过快速训练和部署,可以使四足机器人适应不同的地形和环境,提高其自主性和适应性。此外,该方法还可以推广到其他类型的机器人和控制任务中。
📄 摘要(原文)
First-order Policy Gradient (FoPG) algorithms such as Backpropagation through Time and Analytical Policy Gradients leverage local simulation physics to accelerate policy search, significantly improving sample efficiency in robot control compared to standard model-free reinforcement learning. However, FoPG algorithms can exhibit poor learning dynamics in contact-rich tasks like locomotion. Previous approaches address this issue by alleviating contact dynamics via algorithmic or simulation innovations. In contrast, we propose guiding the policy search by learning a residual over a simple baseline policy. For quadruped locomotion, we find that the role of residual policy learning in FoPG-based training (FoPG RPL) is primarily to improve asymptotic rewards, compared to improving sample efficiency for model-free RL. Additionally, we provide insights on applying FoPG's to pixel-based local navigation, training a point-mass robot to convergence within seconds. Finally, we showcase the versatility of FoPG RPL by using it to train locomotion and perceptive navigation end-to-end on a quadruped in minutes.