Guiding Long-Horizon Task and Motion Planning with Vision Language Models
作者: Zhutian Yang, Caelan Garrett, Dieter Fox, Tomás Lozano-Pérez, Leslie Pack Kaelbling
分类: cs.RO
发布日期: 2024-10-03
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VLM-TAMP:利用视觉语言模型引导长时程任务与运动规划
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 任务与运动规划 机器人规划 分层规划 长时程任务 厨房环境 语义理解
📋 核心要点
- 现有方法难以兼顾长时程任务规划的语义理解和机器人运动规划的几何可行性,导致规划结果不切实际或无法完成复杂任务。
- VLM-TAMP利用视觉语言模型生成中间子目标,缩小规划范围,并指导任务和运动规划器,实现语义和几何可行性的结合。
- 实验表明,VLM-TAMP在厨房烹饪任务中显著优于基线方法,成功率和任务完成度均大幅提升。
📝 摘要(中文)
视觉语言模型(VLM)在给定目标、上下文、场景图像和规划约束时,能够生成看似合理的高级规划。然而,这些预测的动作并不能保证在几何和运动学上对特定机器人是可行的。因此,许多先决步骤,如打开抽屉以获取物体,经常在计划中被省略。机器人任务和运动规划器可以生成符合动作几何可行性的运动轨迹,并插入物理上必要的动作,但无法扩展到需要常识知识并涉及包含许多变量的大型状态空间的日常问题。我们提出了VLM-TAMP,一种分层规划算法,它利用VLM生成具有语义意义并减少规划范围的中间子目标,以指导任务和运动规划器。当子目标或动作无法细化时,VLM会被再次查询以进行重新规划。我们在厨房任务上评估了VLM-TAMP,其中机器人必须完成需要按顺序执行30-50个动作并与多达21个物体交互的烹饪目标。VLM-TAMP在成功率(50%到100% vs 0%)和平均任务完成百分比(72%到100% vs 15%到45%)方面,显著优于刚性且独立执行VLM生成动作序列的基线。
🔬 方法详解
问题定义:论文旨在解决机器人长时程任务与运动规划问题,现有方法要么依赖视觉语言模型生成高级规划但忽略几何可行性,要么依赖任务和运动规划器保证可行性但无法处理复杂、大规模状态空间的问题。痛点在于无法兼顾语义理解和几何可行性,导致机器人难以完成需要常识知识的复杂任务。
核心思路:核心思路是利用视觉语言模型(VLM)生成具有语义意义的中间子目标,这些子目标可以缩小规划范围,并作为任务和运动规划器(TAMP)的指导。通过分层规划,VLM负责生成高级语义规划,TAMP负责生成底层的几何可行运动轨迹,从而实现语义理解和几何可行性的结合。当TAMP无法实现某个子目标时,VLM会重新规划,实现动态调整。
技术框架:VLM-TAMP的整体架构是一个分层规划框架,包含以下主要模块:1) 视觉语言模型(VLM):用于生成高级语义规划和中间子目标。2) 任务和运动规划器(TAMP):用于生成几何可行的运动轨迹,并尝试实现VLM提供的子目标。3) 重新规划机制:当TAMP无法实现某个子目标时,VLM会被再次查询以进行重新规划。整个流程是一个迭代的过程,VLM生成子目标,TAMP尝试实现,如果失败则VLM重新规划,直到任务完成。
关键创新:最重要的技术创新点在于将视觉语言模型和任务运动规划器结合起来,形成一个分层规划框架。VLM负责高级语义规划,TAMP负责底层几何可行性,两者协同工作,克服了各自的局限性。与现有方法相比,VLM-TAMP能够更好地处理需要常识知识和大规模状态空间的复杂任务。
关键设计:VLM使用预训练的视觉语言模型,通过prompt工程来引导其生成合适的子目标。TAMP使用现有的任务和运动规划算法,例如RRT-Connect等。关键在于如何设计prompt,使得VLM能够生成既具有语义意义,又能被TAMP有效利用的子目标。此外,重新规划机制的设计也很重要,需要判断何时需要重新规划,以及如何重新prompt VLM。
🖼️ 关键图片

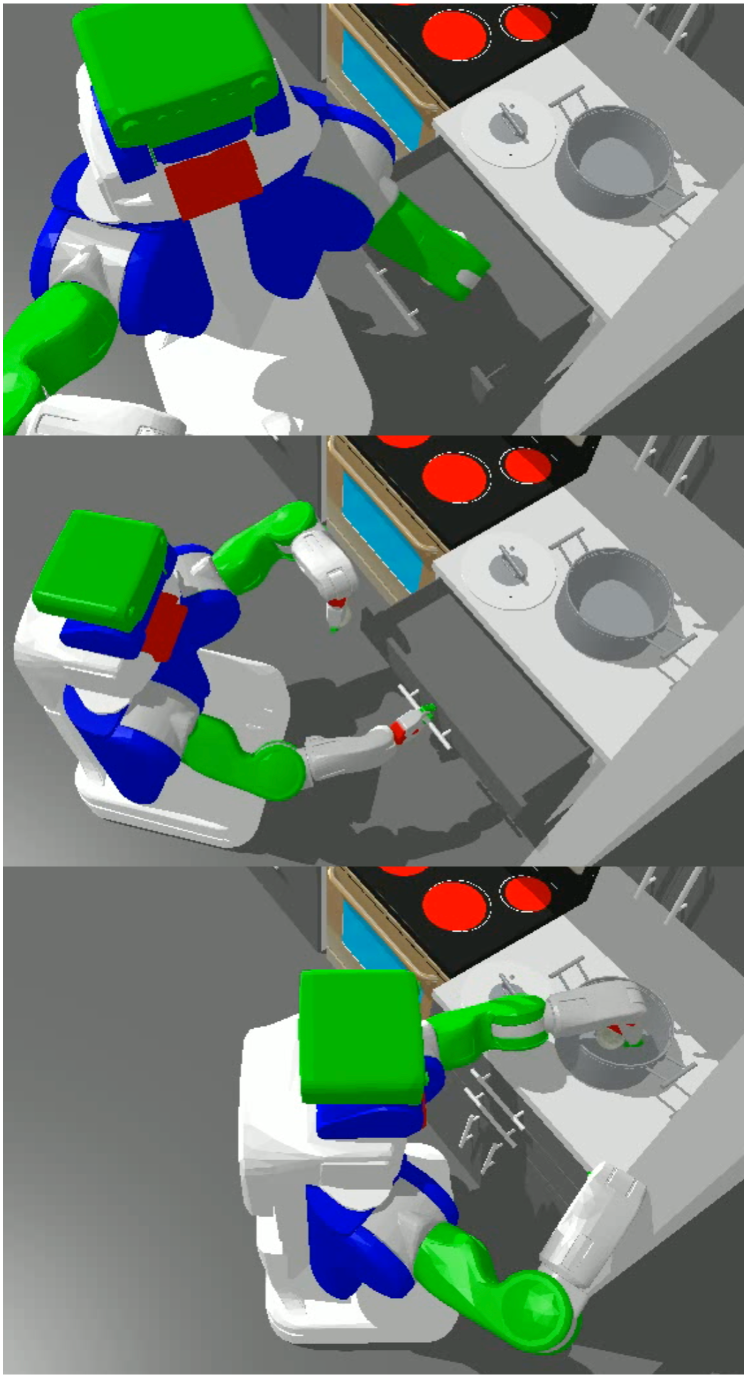

📊 实验亮点
实验结果表明,VLM-TAMP在厨房烹饪任务中表现出色,成功率从基线的0%提升到50%-100%,平均任务完成百分比从基线的15%-45%提升到72%-100%。这些数据表明,VLM-TAMP能够显著提高机器人完成复杂任务的能力,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂操作的场景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。通过结合视觉语言模型的语义理解能力和任务运动规划器的几何可行性,可以使机器人更好地理解人类指令,并完成复杂的任务,提高机器人的智能化水平和应用范围。
📄 摘要(原文)
Vision-Language Models (VLM) can generate plausible high-level plans when prompted with a goal, the context, an image of the scene, and any planning constraints. However, there is no guarantee that the predicted actions are geometrically and kinematically feasible for a particular robot embodiment. As a result, many prerequisite steps such as opening drawers to access objects are often omitted in their plans. Robot task and motion planners can generate motion trajectories that respect the geometric feasibility of actions and insert physically necessary actions, but do not scale to everyday problems that require common-sense knowledge and involve large state spaces comprised of many variables. We propose VLM-TAMP, a hierarchical planning algorithm that leverages a VLM to generate goth semantically-meaningful and horizon-reducing intermediate subgoals that guide a task and motion planner. When a subgoal or action cannot be refined, the VLM is queried again for replanning. We evaluate VLM- TAMP on kitchen tasks where a robot must accomplish cooking goals that require performing 30-50 actions in sequence and interacting with up to 21 objects. VLM-TAMP substantially outperforms baselines that rigidly and independently execute VLM-generated action sequences, both in terms of success rates (50 to 100% versus 0%) and average task completion percentage (72 to 100% versus 15 to 45%). See project site https://zt-yang.github.io/vlm-tamp-robot/ for more information.