One-Shot Robust Imitation Learning for Long-Horizon Visuomotor Tasks from Unsegmented Demonstrations
作者: Shaokang Wu, Yijin Wang, Yanlong Huang
分类: cs.RO
发布日期: 2024-10-02
备注: 15 pages, 6 figures
💡 一句话要点
提出MiLa框架,通过元学习和自适应动态原语实现长时程无分割示教学习,并增强鲁棒性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 元学习 动态运动原语 长时程任务 机器人 视觉运动 鲁棒性
📋 核心要点
- 传统模仿学习在长时程任务中需要大量分割好的演示数据,且对外部扰动和视觉遮挡敏感。
- MiLa框架结合动态运动原语和元学习,仅需少量未分割的演示即可学习长时程任务,并具备一定的鲁棒性。
- 真实机器人实验验证了MiLa的有效性,即使在视觉遮挡和随机扰动下也能表现出良好的性能。
📝 摘要(中文)
本文提出了一种新的模仿学习框架,称为基于自适应动态原语的元模仿学习(MiLa),用于学习未分割的长时程视觉运动技能。与单技能任务不同,长时程任务在日常生活中至关重要,例如倒水任务需要到达、抓取和倒水等子任务的适当连接。模仿学习作为一种将人类技能转移到机器人的有效解决方案,在过去二十年中取得了显著进展。然而,在学习长时程视觉运动技能时,模仿学习通常需要大量语义分割的演示。此外,模仿学习的性能可能容易受到外部扰动和视觉遮挡的影响。MiLa利用动态运动原语和元学习,允许从单个演示中学习未分割的长时程演示并适应未见过的任务。MiLa还可以在任务执行期间抵抗外部干扰和视觉遮挡。真实世界的机器人实验证明了MiLa的优越性,不受视觉遮挡和机器人随机扰动的影响。
🔬 方法详解
问题定义:论文旨在解决长时程视觉运动任务中,模仿学习对大量分割演示数据的依赖性问题,以及对外部扰动和视觉遮挡的脆弱性。现有方法通常需要人工分割的演示数据,这既耗时又费力。此外,这些方法在面对真实世界中常见的扰动和遮挡时,性能会显著下降。
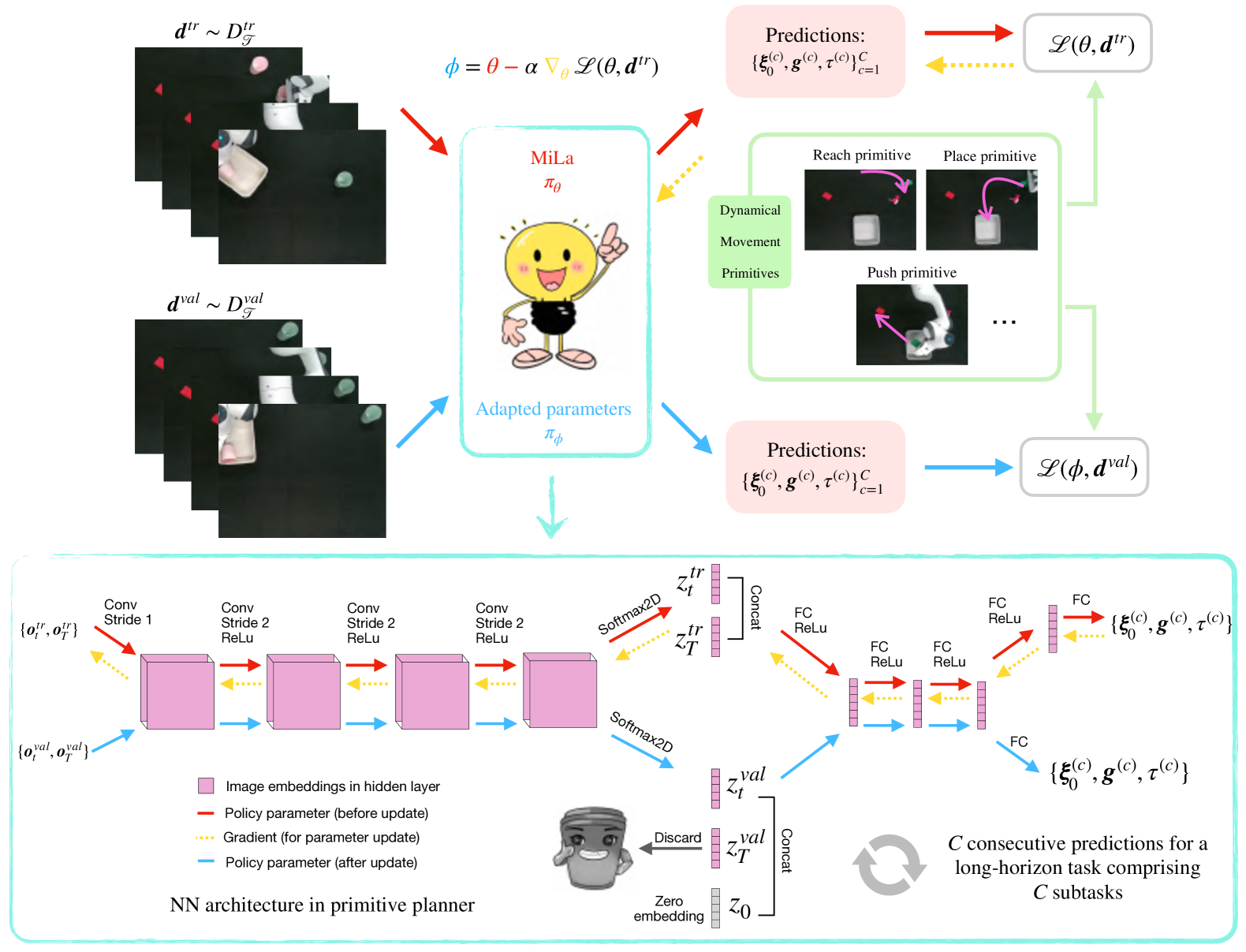
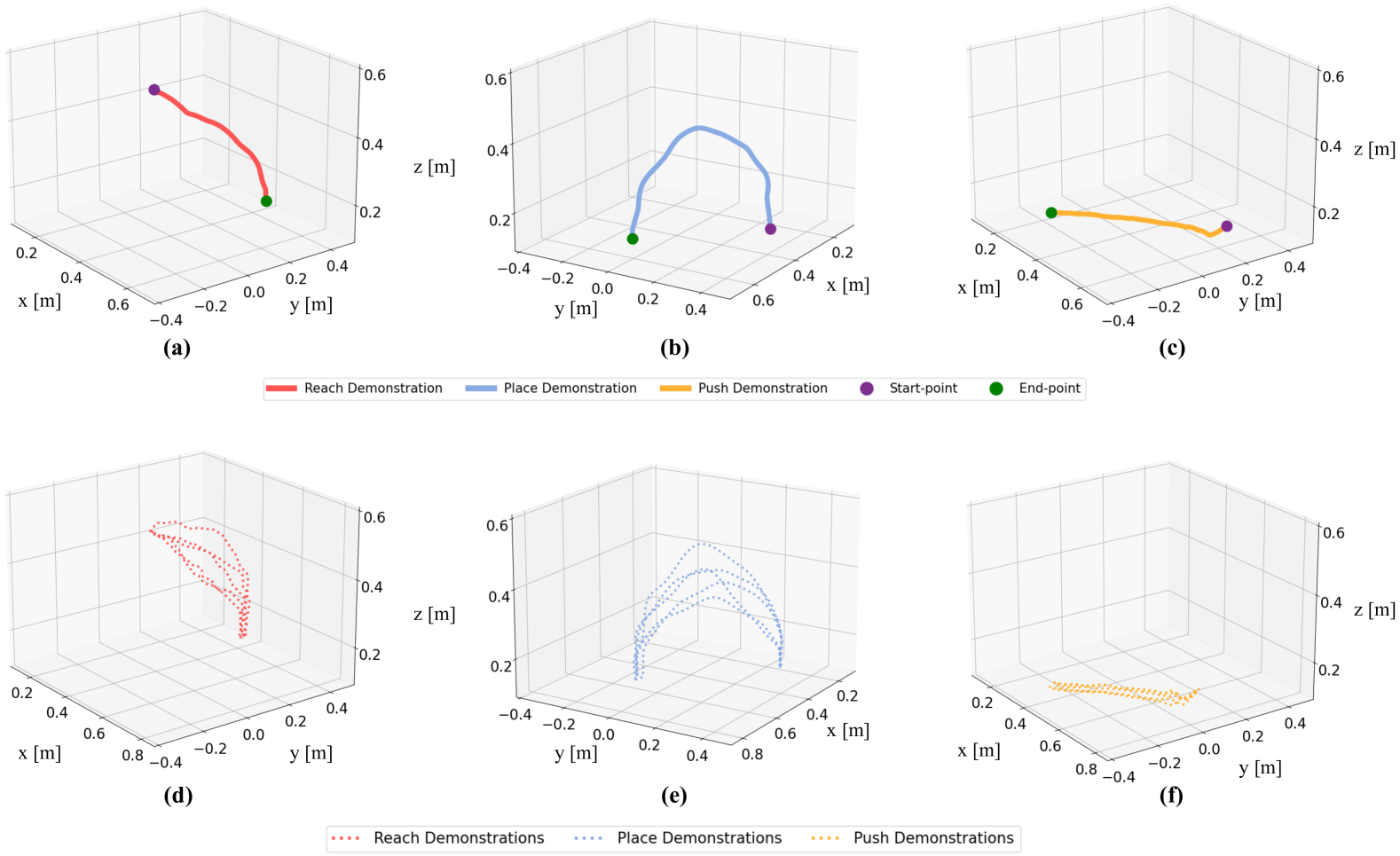
核心思路:MiLa的核心思路是利用元学习来学习一个能够快速适应新任务的策略,并结合动态运动原语(DMP)来表示和生成运动轨迹。通过元学习,模型可以从少量演示中学习到任务的通用结构,从而减少对大量数据的依赖。DMP则提供了一种灵活且鲁棒的运动表示方法,可以有效地处理扰动和遮挡。
技术框架:MiLa的整体框架包括以下几个主要模块:1) 演示数据收集模块:收集少量未分割的长时程任务演示数据。2) 元学习训练模块:使用收集到的数据训练一个元学习模型,该模型能够学习到任务的通用结构和适应新任务的能力。3) 动态运动原语生成模块:使用DMP来表示和生成运动轨迹,DMP的参数由元学习模型预测。4) 任务执行模块:在真实机器人上执行学习到的策略,并评估其性能。
关键创新:MiLa的关键创新在于将元学习和动态运动原语结合起来,从而实现了从少量未分割演示中学习长时程任务,并具备一定的鲁棒性。与传统的模仿学习方法相比,MiLa不需要大量分割的数据,并且能够更好地处理扰动和遮挡。
关键设计:MiLa的具体设计细节包括:1) 使用LSTM网络作为元学习模型,学习任务的通用结构。2) 使用高斯混合模型(GMM)来初始化DMP的参数。3) 使用强化学习来微调DMP的参数,以进一步提高性能。4) 使用视觉伺服控制来处理视觉遮挡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MiLa在真实机器人平台上能够成功学习各种长时程任务,例如倒水、堆叠积木等。与传统的模仿学习方法相比,MiLa在数据效率和鲁棒性方面都表现出显著的优势。即使在视觉遮挡和随机扰动的情况下,MiLa仍然能够稳定地完成任务,并且只需要少量演示数据即可达到良好的性能。
🎯 应用场景
MiLa框架可应用于各种需要机器人执行复杂操作的场景,例如:家庭服务机器人可以学习完成烹饪、清洁等任务;工业机器人可以学习完成装配、搬运等任务;医疗机器人可以学习辅助医生进行手术等。该研究有助于降低机器人学习复杂任务的门槛,提高机器人的智能化水平。
📄 摘要(原文)
In contrast to single-skill tasks, long-horizon tasks play a crucial role in our daily life, e.g., a pouring task requires a proper concatenation of reaching, grasping and pouring subtasks. As an efficient solution for transferring human skills to robots, imitation learning has achieved great progress over the last two decades. However, when learning long-horizon visuomotor skills, imitation learning often demands a large amount of semantically segmented demonstrations. Moreover, the performance of imitation learning could be susceptible to external perturbation and visual occlusion. In this paper, we exploit dynamical movement primitives and meta-learning to provide a new framework for imitation learning, called Meta-Imitation Learning with Adaptive Dynamical Primitives (MiLa). MiLa allows for learning unsegmented long-horizon demonstrations and adapting to unseen tasks with a single demonstration. MiLa can also resist external disturbances and visual occlusion during task execution. Real-world robotic experiments demonstrate the superiority of MiLa, irrespective of visual occlusion and random perturbations on robots.