Robo-MUTUAL: Robotic Multimodal Task Specification via Unimodal Learning
作者: Jianxiong Li, Zhihao Wang, Jinliang Zheng, Xiaoai Zhou, Guanming Wang, Guanglu Song, Yu Liu, Jingjing Liu, Ya-Qin Zhang, Junzhi Yu, Xianyuan Zhan
分类: cs.RO, cs.CV
发布日期: 2024-10-02
备注: preprint
💡 一句话要点
Robo-MUTUAL:利用单模态学习实现机器人多模态任务规范
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人学习 多模态融合 跨模态对齐 单模态学习 任务规范
📋 核心要点
- 现有机器人学习方法难以获取充足的配对多模态数据,限制了机器人对复杂任务指令的理解。
- Robo-MUTUAL通过预训练多模态编码器和Collapse/Corrupt操作,实现跨模态对齐,使机器人能利用单模态数据学习多模态任务。
- 在模拟和真实机器人平台上的大量实验表明,该框架在数据约束下表现出色,显著提升了机器人任务完成能力。
📝 摘要(中文)
多模态任务规范对于提升机器人性能至关重要,其中跨模态对齐使机器人能够全面理解复杂的任务指令。直接标注多模态指令进行模型训练是不切实际的,因为配对的多模态数据稀疏。本研究表明,通过利用真实数据中丰富的单模态指令,我们可以有效地教导机器人学习多模态任务规范。首先,通过使用大量的领域外数据预训练机器人多模态编码器,赋予机器人强大的跨模态对齐能力。然后,我们采用两种Collapse和Corrupt操作,进一步弥合学习到的多模态表示中剩余的模态差距。这种方法将相同任务目标的不同模态投影为可互换的表示,从而在良好对齐的多模态潜在空间内实现精确的机器人操作。在模拟LIBERO基准和真实机器人平台上的超过130个任务和4000次评估中,我们的框架表现出卓越的性能,证明了其在克服机器人学习中的数据约束方面的显著优势。
🔬 方法详解
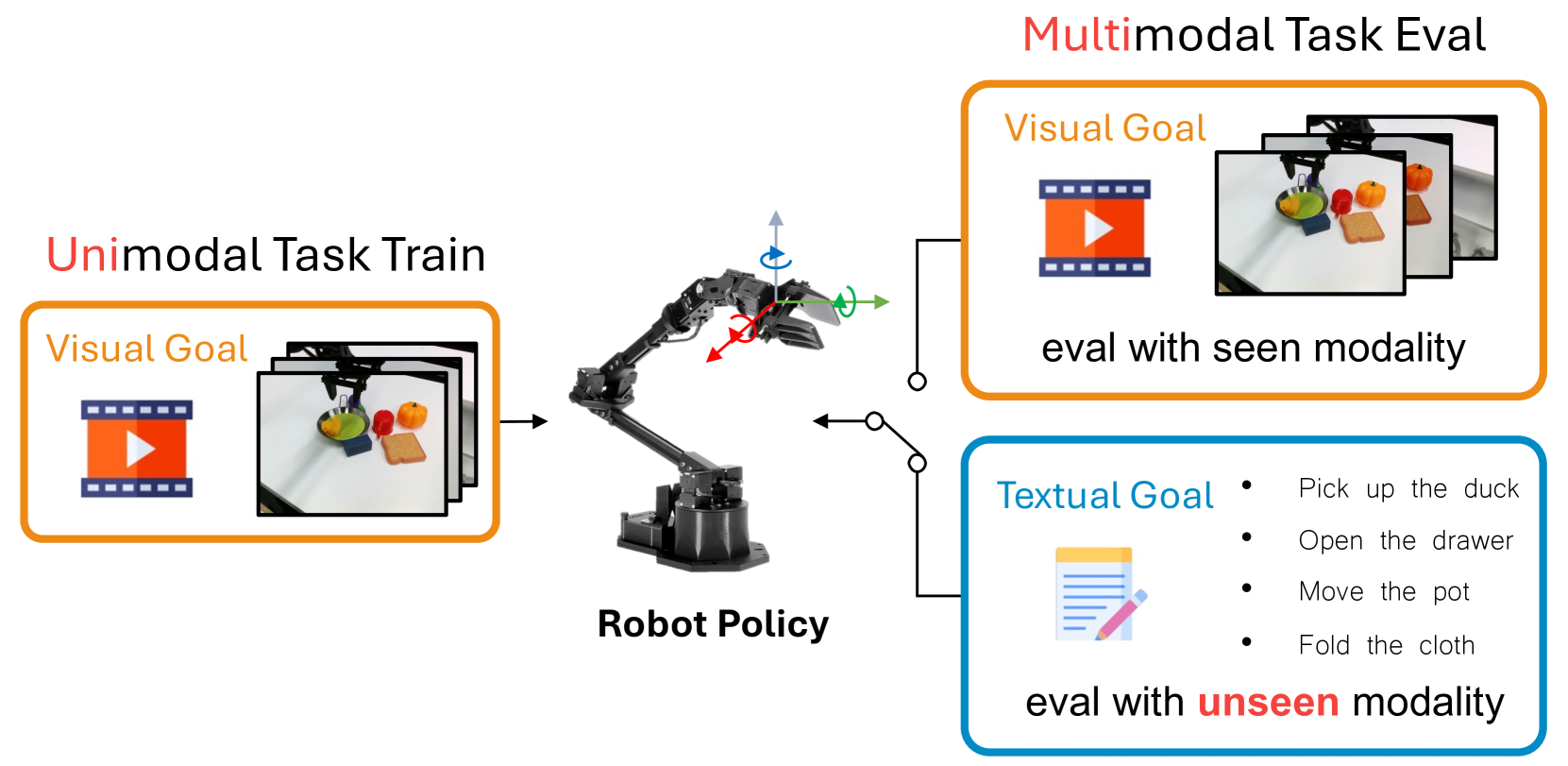
问题定义:论文旨在解决机器人学习中多模态任务规范的数据稀疏问题。现有方法依赖于大量的配对多模态数据,但实际应用中,获取这些数据成本高昂且效率低下,导致机器人难以理解和执行复杂的多模态指令。
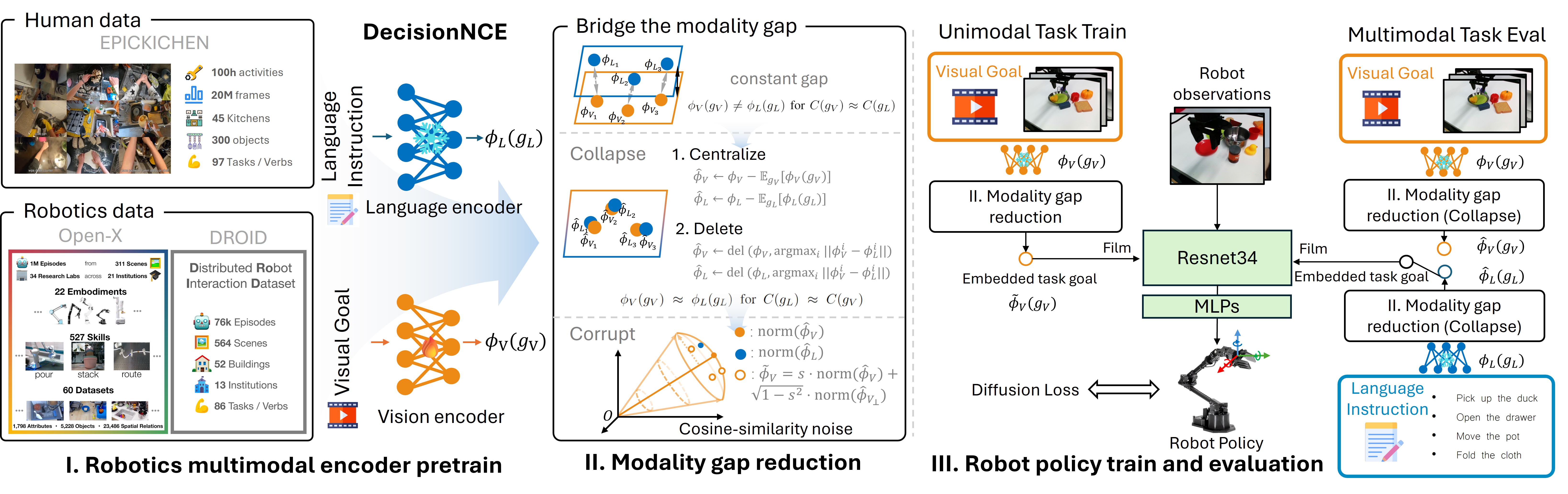
核心思路:论文的核心思路是利用易于获取的单模态数据,通过跨模态对齐,使机器人能够学习多模态任务规范。通过预训练和特定的数据增强策略,将不同模态的相同任务目标映射到统一的潜在空间,实现模态间的互换性和通用性。
技术框架:Robo-MUTUAL框架主要包含以下几个阶段:1) 使用大量领域外数据预训练机器人多模态编码器,使其具备初步的跨模态对齐能力。2) 采用Collapse操作,将多模态输入坍缩为单模态,迫使模型学习模态不变的表示。3) 采用Corrupt操作,随机破坏部分模态信息,增强模型的鲁棒性。4) 在对齐的多模态潜在空间中,机器人可以根据任务指令执行相应的操作。
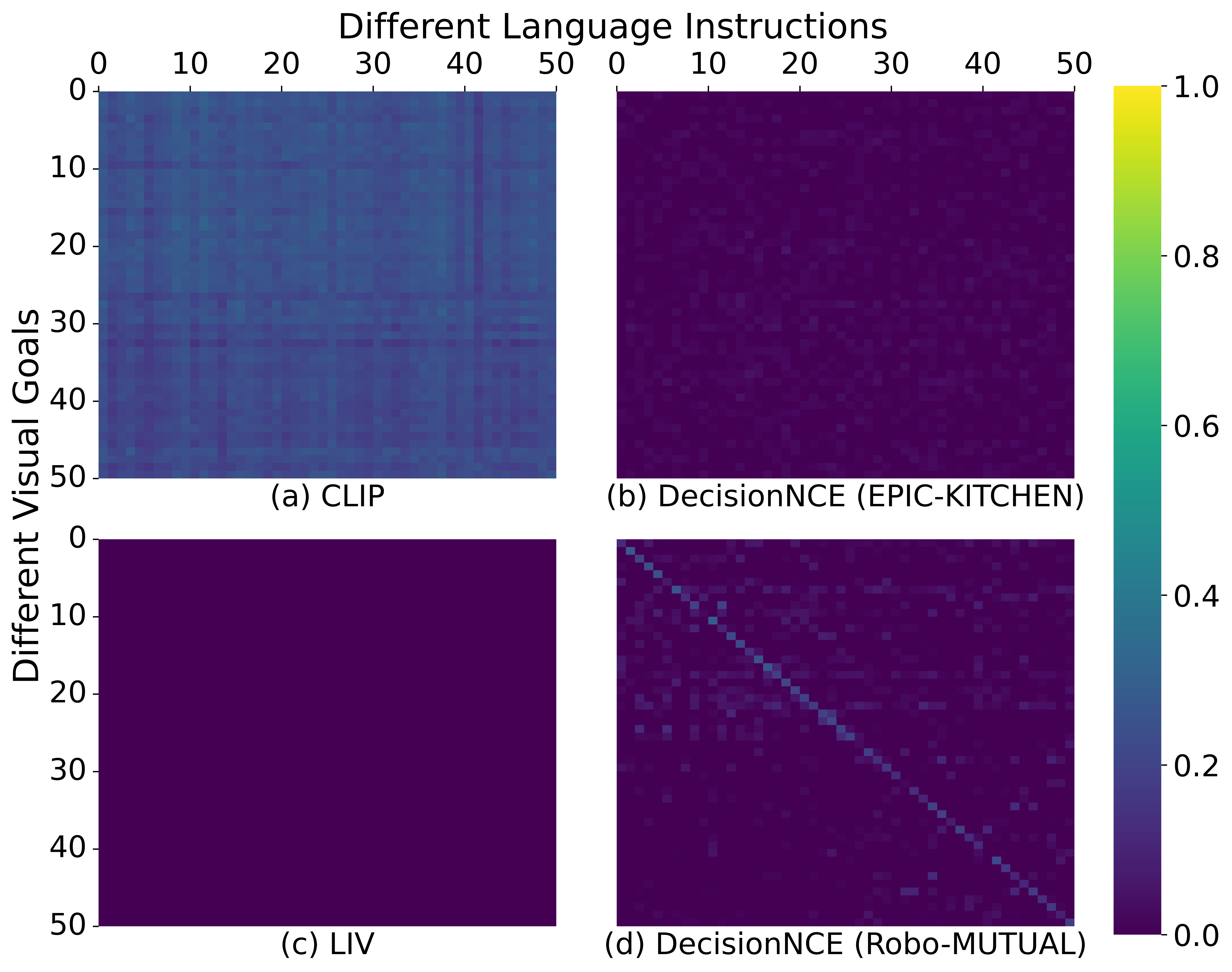
关键创新:该论文的关键创新在于利用单模态数据进行多模态任务学习。与传统方法依赖配对的多模态数据不同,Robo-MUTUAL通过预训练和数据增强,实现了跨模态知识迁移,有效解决了数据稀疏问题。Collapse和Corrupt操作是弥合模态差距的关键技术。
关键设计:论文中,预训练的多模态编码器采用Transformer结构,能够有效捕捉不同模态之间的关系。Collapse操作通过随机mask掉部分模态的输入实现。Corrupt操作则通过随机替换或噪声注入破坏模态信息。损失函数的设计旨在鼓励模型学习模态不变的表示,例如对比学习损失或三元组损失。
🖼️ 关键图片
📊 实验亮点
Robo-MUTUAL在模拟LIBERO基准和真实机器人平台上进行了广泛的实验评估,涵盖超过130个任务和4000次评估。实验结果表明,该框架在多模态任务规范学习方面表现出显著优势,尤其是在数据稀疏的情况下,性能优于现有方法。具体提升幅度未知,但摘要强调了其“superior capabilities”和“significant advantage”。
🎯 应用场景
Robo-MUTUAL框架可应用于各种需要多模态交互的机器人任务,例如家庭服务机器人、工业机器人和医疗机器人。该方法降低了对大量配对多模态数据的依赖,使得机器人能够更好地理解人类指令,执行更复杂的任务,并提高人机协作效率。未来,该技术有望推动机器人智能化发展,使其在更多领域发挥作用。
📄 摘要(原文)
Multimodal task specification is essential for enhanced robotic performance, where \textit{Cross-modality Alignment} enables the robot to holistically understand complex task instructions. Directly annotating multimodal instructions for model training proves impractical, due to the sparsity of paired multimodal data. In this study, we demonstrate that by leveraging unimodal instructions abundant in real data, we can effectively teach robots to learn multimodal task specifications. First, we endow the robot with strong \textit{Cross-modality Alignment} capabilities, by pretraining a robotic multimodal encoder using extensive out-of-domain data. Then, we employ two Collapse and Corrupt operations to further bridge the remaining modality gap in the learned multimodal representation. This approach projects different modalities of identical task goal as interchangeable representations, thus enabling accurate robotic operations within a well-aligned multimodal latent space. Evaluation across more than 130 tasks and 4000 evaluations on both simulated LIBERO benchmark and real robot platforms showcases the superior capabilities of our proposed framework, demonstrating significant advantage in overcoming data constraints in robotic learning. Website: zh1hao.wang/Robo_MUTUAL