CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction
作者: Suhwan Choi, Yongjun Cho, Minchan Kim, Jaeyoon Jung, Myunchul Joe, Yubeen Park, Minseo Kim, Sungwoong Kim, Sungjae Lee, Hwiseong Park, Jiwan Chung, Youngjae Yu
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-10-02 (更新: 2025-08-08)
备注: Accepted to ICRA 2025, project page https://worv-ai.github.io/canvas
💡 一句话要点
提出CANVAS,结合视觉和语言指令,实现常识感知的直观人机交互导航。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人导航 人机交互 常识推理 模仿学习 视觉语言融合
📋 核心要点
- 现实导航需要优化运动并满足特定目标,现有方法难以处理人类抽象指令中的噪声和不确定性。
- CANVAS框架结合视觉和语言指令,通过模仿学习使机器人从人类导航行为中学习常识。
- 实验表明CANVAS优于ROS NavStack,在果园环境中成功率从0%提升到67%,并具有良好的Sim2Real迁移能力。
📝 摘要(中文)
本文提出了一种名为CANVAS的新框架,用于实现常识感知的导航,该框架结合了视觉和语言指令,旨在实现更直观的人机交互。CANVAS的核心是模仿学习,使机器人能够从人类的导航行为中学习。为了训练这种常识感知的导航系统,作者构建了一个名为COMMAND的综合数据集,该数据集包含超过48小时和219公里的带有人工标注的导航数据。实验结果表明,CANVAS在所有环境中均优于基于规则的ROS NavStack系统,尤其是在噪声指令下表现更佳。在ROS NavStack成功率为0%的果园环境中,CANVAS的成功率达到了67%。CANVAS在未见过的环境中也能与人类演示和常识约束保持一致。此外,CANVAS在真实世界中的部署也展示了令人印象深刻的Sim2Real迁移能力,总成功率达到69%,突出了从模拟环境中学习人类演示在实际应用中的潜力。
🔬 方法详解
问题定义:现有机器人导航系统难以理解和执行人类给出的抽象、不精确的指令,例如口头命令或粗略草图。这些指令通常包含噪声或缺乏细节,导致机器人无法按照人类的意图进行导航。现有方法,如ROS NavStack,依赖于精确的规则和环境建模,难以适应复杂和动态的真实世界场景,尤其是在面对模糊指令时表现不佳。
核心思路:CANVAS的核心思路是让机器人通过模仿学习人类的导航行为来获得常识。通过学习人类在各种场景下的导航策略,机器人可以更好地理解人类的意图,并能够处理不确定性和噪声。结合视觉和语言指令,CANVAS能够更全面地理解导航任务,并做出符合人类期望的决策。
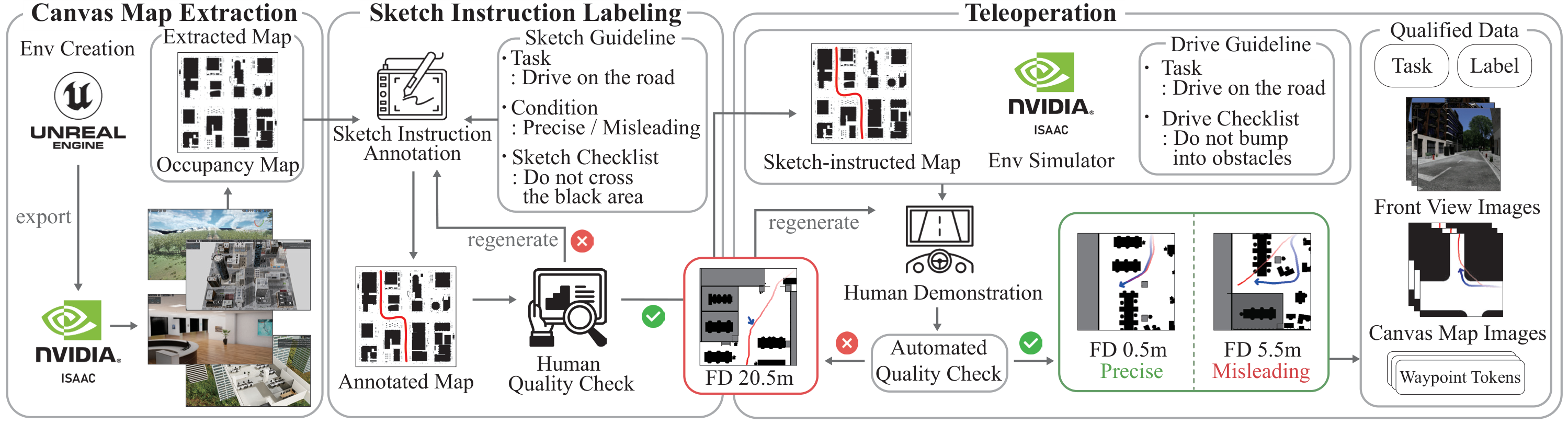
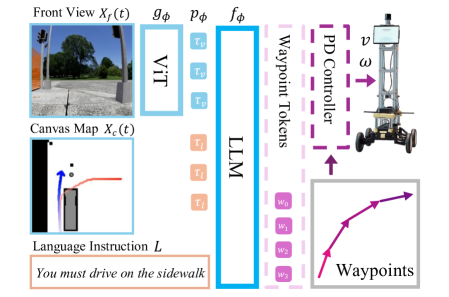
技术框架:CANVAS框架包含以下主要模块:1) 指令编码器:用于处理视觉和语言指令,提取关键信息。2) 导航策略学习器:通过模仿学习,从COMMAND数据集中学习人类的导航策略。3) 运动规划器:根据学习到的策略和当前环境信息,生成机器人的运动轨迹。整个流程是,首先接收人类的视觉或语言指令,经过指令编码器处理后,输入到导航策略学习器中,学习器根据学习到的知识生成导航策略,最后由运动规划器执行。
关键创新:CANVAS的关键创新在于其常识感知的导航能力,这得益于模仿学习和对视觉、语言指令的综合利用。与传统的基于规则的导航系统相比,CANVAS能够更好地理解人类的意图,并能够处理不确定性和噪声。此外,COMMAND数据集的构建也为训练常识感知的导航系统提供了重要的数据支持。
关键设计:CANVAS使用了Transformer网络来编码视觉和语言指令,提取特征。导航策略学习器采用行为克隆(Behavior Cloning)算法,直接从人类的导航轨迹中学习。损失函数主要包括模仿损失(Imitation Loss),用于衡量机器人导航轨迹与人类轨迹的相似度,以及辅助损失,用于约束机器人的行为符合常识。具体的网络结构和参数设置在论文中有详细描述,例如Transformer的层数、隐藏层大小,以及学习率等。
🖼️ 关键图片

📊 实验亮点
CANVAS在模拟环境和真实环境中都取得了显著的成果。在模拟环境中,CANVAS在所有测试环境中均优于ROS NavStack,尤其是在果园环境中,CANVAS的成功率达到了67%,而ROS NavStack的成功率为0%。在真实世界中,CANVAS的Sim2Real迁移成功率达到了69%,证明了其在实际应用中的潜力。这些结果表明,通过模仿学习人类的导航行为,机器人可以获得常识感知的导航能力,从而实现更智能、更可靠的导航。
🎯 应用场景
CANVAS具有广泛的应用前景,例如在家庭服务机器人、物流机器人、医疗机器人等领域。它可以使机器人更容易地理解人类的指令,从而实现更自然、更高效的人机交互。此外,CANVAS还可以应用于自动驾驶领域,提高自动驾驶系统的安全性和可靠性。未来,CANVAS有望成为人机协作的重要组成部分,促进人工智能技术在各个领域的应用。
📄 摘要(原文)
Real-life robot navigation involves more than just reaching a destination; it requires optimizing movements while addressing scenario-specific goals. An intuitive way for humans to express these goals is through abstract cues like verbal commands or rough sketches. Such human guidance may lack details or be noisy. Nonetheless, we expect robots to navigate as intended. For robots to interpret and execute these abstract instructions in line with human expectations, they must share a common understanding of basic navigation concepts with humans. To this end, we introduce CANVAS, a novel framework that combines visual and linguistic instructions for commonsense-aware navigation. Its success is driven by imitation learning, enabling the robot to learn from human navigation behavior. We present COMMAND, a comprehensive dataset with human-annotated navigation results, spanning over 48 hours and 219 km, designed to train commonsense-aware navigation systems in simulated environments. Our experiments show that CANVAS outperforms the strong rule-based system ROS NavStack across all environments, demonstrating superior performance with noisy instructions. Notably, in the orchard environment, where ROS NavStack records a 0% total success rate, CANVAS achieves a total success rate of 67%. CANVAS also closely aligns with human demonstrations and commonsense constraints, even in unseen environments. Furthermore, real-world deployment of CANVAS showcases impressive Sim2Real transfer with a total success rate of 69%, highlighting the potential of learning from human demonstrations in simulated environments for real-world applications.