High and Low Resolution Tradeoffs in Roadside Multimodal Sensing
作者: Shaozu Ding, Yihong Tang, Marco De Vincenzi, Dajiang Suo
分类: cs.RO
发布日期: 2024-10-02 (更新: 2025-05-05)
备注: 8 pages, 7 figures
💡 一句话要点
提出路侧多模态感知评估框架,平衡高低分辨率传感器成本与性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 路侧感知 传感器布局优化 深度学习 智能交通
📋 核心要点
- 现有路侧感知方案难以在传感器成本、覆盖范围和感知性能之间取得平衡,缺乏统一的评估框架。
- 论文提出一种基于整数规划的传感器布局优化方法,并设计了多模态融合框架,模拟人类多感官集成。
- 实验表明,低分辨率激光雷达与毫米波雷达融合,在成本更低的情况下,性能优于高分辨率激光雷达。
📝 摘要(中文)
在选择高分辨率或低分辨率路侧点云传感器时,平衡成本和性能至关重要。例如,激光雷达提供密集的点云,而4D毫米波雷达虽然空间稀疏,但嵌入了速度信息,有助于区分物体,且价格更低。然而,传感器放置策略会影响覆盖区域内的点云密度和分布。此外,不同的传感器组合通常需要不同的神经网络架构,以最大限度地发挥其互补优势。为了解决这些挑战,我们提出了一个事前评估框架。首先,我们实现了一个基于整数规划的仿真工具,可以自动比较不同传感器放置策略的覆盖范围和成本。此外,受到人类多感官融合的启发,我们提出了一个模块化框架,以评估空间分辨率的降低是否可以通过信息丰富度来补偿,从而检测交通参与者。大量的实验测试表明,将速度编码的雷达与低分辨率激光雷达融合,比单独使用高分辨率激光雷达,在更低的成本下,获得了显著的增益(行人检测AP提升14%,六个类别上的mAP总体提升1.5%)。值得注意的是,这些显著的增益与框架中使用的特定深度神经模块无关。该结果挑战了高分辨率总是优于低分辨率替代方案的普遍假设。
🔬 方法详解
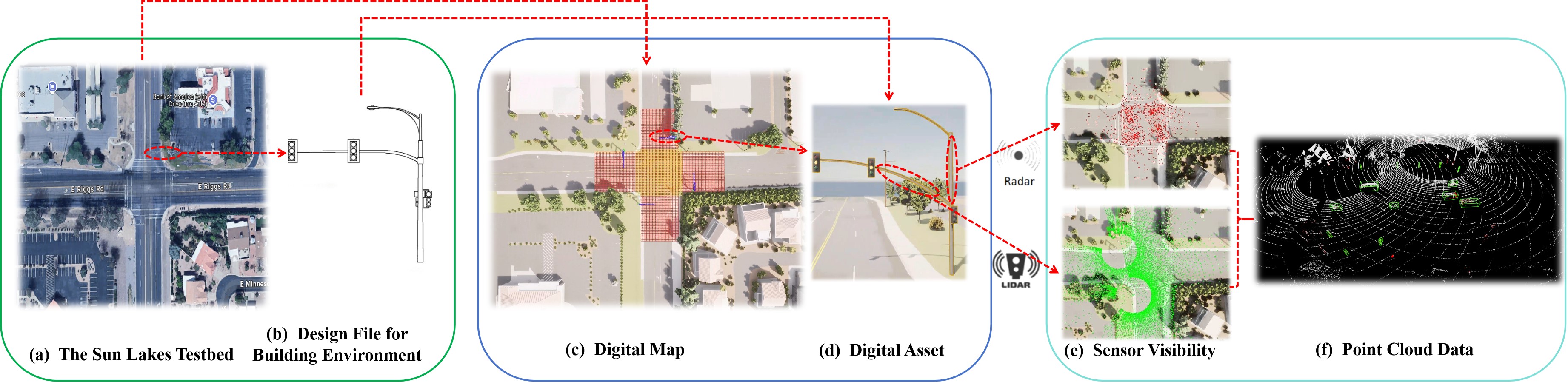
问题定义:论文旨在解决路侧多模态感知系统中,如何选择和配置不同分辨率和类型的传感器,以在成本、覆盖范围和感知性能之间取得最佳平衡的问题。现有方法通常依赖于经验或简单的规则,缺乏系统性的评估和优化,难以充分利用不同传感器的互补优势。此外,不同传感器组合需要不同的神经网络架构,增加了系统设计的复杂性。
核心思路:论文的核心思路是建立一个统一的评估框架,该框架能够量化不同传感器配置的成本、覆盖范围和感知性能,并基于此进行优化。该框架借鉴了人类多感官融合的机制,通过信息互补的方式,弥补低分辨率传感器在空间信息上的不足。
技术框架:该框架包含两个主要组成部分:1) 基于整数规划的传感器布局优化工具,用于自动比较不同传感器放置策略的覆盖范围和成本;2) 基于模块化神经网络的多模态融合框架,用于评估不同传感器组合的感知性能。该框架允许灵活地选择和组合不同的深度学习模块,以适应不同的传感器配置。
关键创新:论文的关键创新在于提出了一个综合性的评估框架,能够同时考虑传感器布局、成本和感知性能,并基于此进行优化。此外,该框架借鉴了人类多感官融合的机制,通过信息互补的方式,有效利用了低分辨率传感器的信息。
关键设计:传感器布局优化工具使用整数规划来建模传感器放置问题,目标是最大化覆盖范围,同时最小化成本。多模态融合框架采用模块化设计,允许灵活地选择和组合不同的深度学习模块,例如,可以使用不同的特征提取器和融合策略。论文没有明确给出损失函数和网络结构的具体细节,这些可以根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,将速度编码的雷达与低分辨率激光雷达融合,在行人检测任务中AP提升了14%,在六个类别上的mAP总体提升了1.5%。更重要的是,这种性能提升是在成本更低的情况下实现的,并且与所使用的具体深度学习模块无关,表明该框架具有较强的通用性。
🎯 应用场景
该研究成果可应用于智能交通系统、自动驾驶、智慧城市等领域。通过优化路侧传感器的配置,可以降低系统成本,提高感知性能,从而提升交通安全和效率。该研究也为多模态传感器融合提供了新的思路,有助于推动相关技术的发展。
📄 摘要(原文)
Balancing cost and performance is crucial when choosing high- versus low-resolution point-cloud roadside sensors. For example, LiDAR delivers dense point cloud, while 4D millimeter-wave radar, though spatially sparser, embeds velocity cues that help distinguish objects and come at a lower price. Unfortunately, the sensor placement strategies will influence point cloud density and distribution across the coverage area. Compounding the first challenge is the fact that different sensor mixtures often demand distinct neural network architectures to maximize their complementary strengths. Without an evaluation framework that establishes a benchmark for comparison, it is imprudent to make claims regarding whether marginal gains result from higher resolution and new sensing modalities or from the algorithms. We present an ex-ante evaluation that addresses the two challenges. First, we realized a simulation tool that builds on integer programming to automatically compare different sensor placement strategies against coverage and cost jointly. Additionally, inspired by human multi-sensory integration, we propose a modular framework to assess whether reductions in spatial resolution can be compensated by informational richness in detecting traffic participants. Extensive experimental testing on the proposed framework shows that fusing velocity-encoded radar with low-resolution LiDAR yields marked gains (14 percent AP for pedestrians and an overall mAP improvement of 1.5 percent across six categories) at lower cost than high-resolution LiDAR alone. Notably, these marked gains hold regardless of the specific deep neural modules employed in our frame. The result challenges the prevailing assumption that high resolution are always superior to low-resolution alternatives.