Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
作者: Fukang Liu, Zhaoyuan Gu, Yilin Cai, Ziyi Zhou, Hyunyoung Jung, Jaehwi Jang, Shijie Zhao, Sehoon Ha, Yue Chen, Danfei Xu, Ye Zhao
分类: cs.RO
发布日期: 2024-09-30 (更新: 2025-10-01)
💡 一句话要点
Opt2Skill:结合轨迹优化与强化学习,实现通用人形机器人灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 灵巧操作 轨迹优化 强化学习 微分动态规划 接触力控制 模拟到真实
📋 核心要点
- 人形机器人灵巧操作面临高维度动力学、不稳定性和复杂接触的挑战,现有方法难以兼顾运动自然性和鲁棒性。
- Opt2Skill结合轨迹优化与强化学习,利用DDP生成动态可行参考轨迹,并训练RL策略跟踪,实现鲁棒的全身灵巧操作。
- 实验表明,Opt2Skill在运动跟踪和任务成功率上优于现有方法,并成功迁移到真实机器人上,提升了接触力跟踪性能。
📝 摘要(中文)
人形机器人旨在执行多样化的灵巧操作任务,但面临高维度、不稳定动力学以及复杂接触等挑战。基于模型的优化控制方法虽然能灵活定义精确运动,但计算复杂度高且依赖精确的接触感知。强化学习(RL)虽然能处理高维空间并具有较强的鲁棒性,但学习效率低、运动不自然且存在模拟到真实的差距。为了解决这些问题,我们提出了Opt2Skill,一个端到端的流程,结合了基于模型的轨迹优化与RL,以实现鲁棒的全身灵巧操作。Opt2Skill使用微分动态规划(DDP)为Digit人形机器人生成动态可行且接触一致的参考运动,并训练RL策略来跟踪这些最优轨迹。结果表明,Opt2Skill在运动跟踪和任务成功率方面均优于依赖人类演示和基于逆运动学的参考轨迹的基线方法。此外,我们还表明,结合扭矩信息的轨迹可以改善接触相关任务(如擦桌子)中的接触力跟踪。我们的方法已成功应用于真实世界的应用。
🔬 方法详解
问题定义:人形机器人进行灵巧操作时,需要在高维空间中控制全身运动,同时保证动力学可行性和与环境的稳定接触。现有方法,如纯粹的优化控制,计算量大且对环境感知精度要求高;而纯粹的强化学习,学习效率低,难以生成自然的运动,且存在模拟到真实的迁移问题。因此,需要一种方法,既能生成动力学可行的参考轨迹,又能通过强化学习提高鲁棒性,并最终实现真实世界的应用。
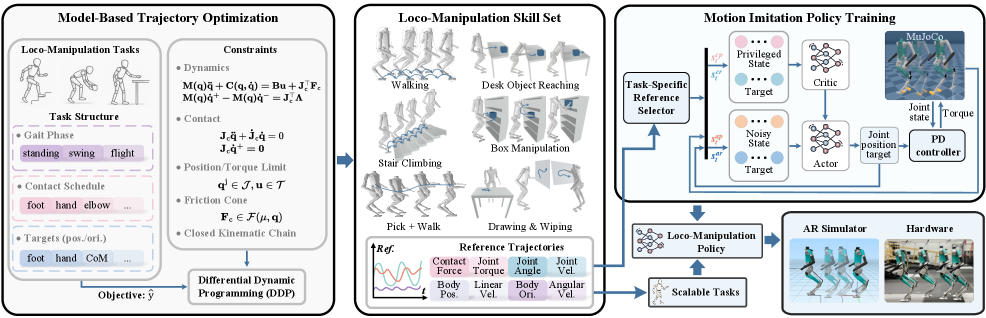
核心思路:Opt2Skill的核心思路是将基于模型的轨迹优化和强化学习相结合。首先,使用微分动态规划(DDP)生成动态可行和接触一致的参考轨迹,这些轨迹包含了位置、速度、力和扭矩等信息。然后,训练强化学习策略来跟踪这些参考轨迹。这样,既利用了优化控制生成高质量参考轨迹的优点,又利用了强化学习的鲁棒性和适应性。
技术框架:Opt2Skill包含两个主要阶段:轨迹优化阶段和强化学习阶段。在轨迹优化阶段,使用DDP算法,根据任务目标和机器人动力学模型,生成最优的参考轨迹。在强化学习阶段,使用PPO等算法,训练一个策略网络,该网络以机器人的状态(例如关节角度、速度)作为输入,输出控制指令,使得机器人能够尽可能地跟踪参考轨迹。整个流程是端到端的,可以根据任务需求进行调整。
关键创新:Opt2Skill的关键创新在于将轨迹优化和强化学习紧密结合,并利用轨迹优化生成的扭矩信息来提高接触力跟踪的性能。与传统的先生成参考轨迹再进行跟踪的方法不同,Opt2Skill通过强化学习来学习如何更好地跟踪轨迹,从而提高了鲁棒性和适应性。此外,利用扭矩信息可以更好地控制机器人与环境的接触力,从而实现更复杂的灵巧操作。
关键设计:在轨迹优化阶段,需要仔细设计任务目标和约束条件,以生成合理的参考轨迹。在强化学习阶段,需要选择合适的奖励函数,鼓励机器人跟踪参考轨迹,并惩罚偏离轨迹的行为。论文中使用了PPO算法,并对奖励函数进行了精细的调整,例如,使用了位置误差、速度误差、力和扭矩误差等作为奖励函数的组成部分。此外,还使用了课程学习等技巧,逐步增加任务的难度,以提高学习效率。
🖼️ 关键图片


📊 实验亮点
Opt2Skill在运动跟踪和任务成功率方面均优于基线方法。例如,在擦桌子任务中,Opt2Skill能够生成更稳定的接触力,并成功完成任务。与依赖人类演示和基于逆运动学的参考轨迹的基线方法相比,Opt2Skill在模拟环境中取得了显著的性能提升,并且成功地将学习到的策略迁移到了真实的Digit人形机器人上。
🎯 应用场景
Opt2Skill具有广泛的应用前景,例如在家庭服务、工业制造、医疗康复等领域。它可以用于控制人形机器人执行各种灵巧操作任务,如擦桌子、组装零件、搬运物品等。通过结合视觉感知等技术,Opt2Skill还可以应用于更复杂的场景,例如在未知环境中进行导航和操作。该研究的成果有助于推动人形机器人在实际生活中的应用。
📄 摘要(原文)
Humanoid robots are designed to perform diverse loco-manipulation tasks. However, they face challenges due to their high-dimensional and unstable dynamics, as well as the complex contact-rich nature of the tasks. Model-based optimal control methods offer flexibility to define precise motion but are limited by high computational complexity and accurate contact sensing. On the other hand, reinforcement learning (RL) handles high-dimensional spaces with strong robustness but suffers from inefficient learning, unnatural motion, and sim-to-real gaps. To address these challenges, we introduce Opt2Skill, an end-to-end pipeline that combines model-based trajectory optimization with RL to achieve robust whole-body loco-manipulation. Opt2Skill generates dynamic feasible and contact-consistent reference motions for the Digit humanoid robot using differential dynamic programming (DDP) and trains RL policies to track these optimal trajectories. Our results demonstrate that Opt2Skill outperforms baselines that rely on human demonstrations and inverse kinematics-based references, both in motion tracking and task success rates. Furthermore, we show that incorporating trajectories with torque information improves contact force tracking in contact-involved tasks, such as wiping a table. We have successfully transferred our approach to real-world applications.