Generalizability of Graph Neural Networks for Decentralized Unlabeled Motion Planning
作者: Shreyas Muthusamy, Damian Owerko, Charilaos I. Kanatsoulis, Saurav Agarwal, Alejandro Ribeiro
分类: cs.RO, cs.AI, eess.SY
发布日期: 2024-09-29
备注: 6 pages, 6 figures, submitted to ICRA 2025
💡 一句话要点
提出基于图神经网络的去中心化无标签运动规划方法,提升多机器人系统的可扩展性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图神经网络 去中心化控制 运动规划 多机器人系统 模仿学习
📋 核心要点
- 传统集中式运动规划方法在机器人数量增加时面临可扩展性挑战,难以应用于大规模多机器人系统。
- 利用图神经网络学习去中心化策略,使每个机器人能够根据局部信息自主决策,实现高效的运动规划。
- 实验结果表明,该方法在可扩展性和性能方面均优于现有方法,尤其是在大规模机器人场景下。
📝 摘要(中文)
本文提出了一种基于图神经网络(GNN)的去中心化策略,用于解决无标签运动规划问题。该问题旨在为一组机器人分配目标位置,同时避免碰撞,并最小化总行程距离。在去中心化环境中,每个机器人仅知道其k近邻机器人和k近邻目标的位置。这种场景结合了组合分配和连续空间运动规划的元素,对传统集中式方法提出了巨大的可扩展性挑战。所提出的GNN使机器人能够确定(1)要与邻居通信的信息,以及(2)如何将接收到的信息与本地观察结果相结合以进行决策。使用集中式匈牙利算法作为专家策略,通过模仿学习训练GNN,并使用强化学习对其进行微调,以避免碰撞并提高性能。大量的实验评估表明了该方法的可扩展性和有效性。在100个机器人上训练的GNN策略可以推广到最多500个机器人的场景,平均优于最先进的解决方案8.6%,并且大大超过了贪婪的去中心化方法。这项工作为解决可扩展性至关重要的多机器人协调问题奠定了基础。
🔬 方法详解
问题定义:论文旨在解决去中心化无标签运动规划问题,即在每个机器人仅知晓其k近邻机器人和目标位置的情况下,为一组机器人分配目标位置,同时避免碰撞并最小化总行程距离。现有集中式方法在机器人数量增加时计算复杂度急剧上升,难以扩展到大规模场景;而简单的去中心化方法,如贪婪算法,容易陷入局部最优,性能较差。
核心思路:论文的核心思路是利用图神经网络(GNN)学习一种去中心化的策略,使每个机器人能够根据局部观测信息(自身位置、邻居机器人和目标位置)自主决策。GNN能够学习机器人之间如何通信以及如何整合接收到的信息,从而实现协同运动规划。通过模仿学习和强化学习相结合的方式训练GNN,使其既能模仿集中式最优解,又能避免碰撞并优化性能。
技术框架:整体框架包含以下几个主要阶段:1) 图构建:每个机器人构建一个包含其k近邻机器人和k近邻目标的局部图。2) GNN推理:GNN接收局部图作为输入,输出每个机器人的动作(例如,速度或目标选择)。3) 运动执行:机器人根据GNN输出的动作执行运动。4) 策略训练:使用模仿学习初始化GNN,然后使用强化学习进行微调。
关键创新:最重要的技术创新点在于使用GNN学习去中心化的运动规划策略。与传统的基于规则或优化的去中心化方法相比,GNN能够学习更复杂的机器人间交互模式,从而实现更好的协同效果。此外,通过模仿学习和强化学习相结合的训练方式,可以有效地利用集中式最优解的知识,并克服强化学习训练不稳定和探索效率低下的问题。
关键设计:GNN的网络结构包括消息传递层和聚合层。消息传递层用于机器人之间交换信息,聚合层用于整合接收到的信息。损失函数包括模仿学习损失和强化学习奖励函数。模仿学习损失用于衡量GNN输出与集中式最优解之间的差异。强化学习奖励函数用于鼓励机器人避免碰撞并最小化总行程距离。具体参数设置(如k近邻数量、GNN层数、学习率等)通过实验进行调整。
🖼️ 关键图片
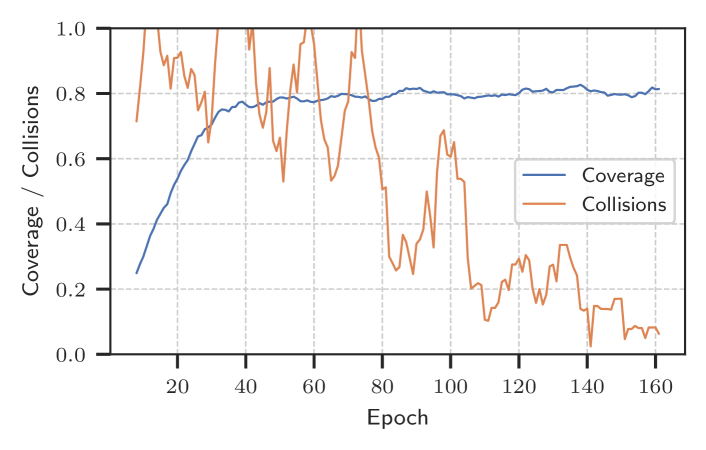

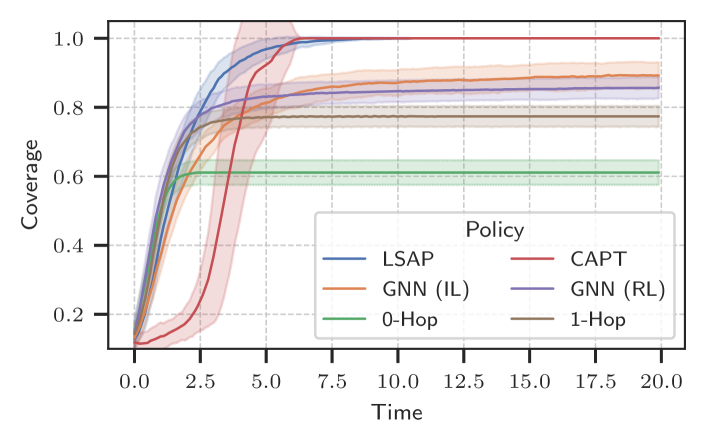
📊 实验亮点
实验结果表明,在100个机器人上训练的GNN策略可以推广到最多500个机器人的场景,平均优于最先进的解决方案8.6%。与贪婪的去中心化方法相比,GNN策略在避免碰撞和最小化总行程距离方面表现出显著优势。这些结果验证了该方法的可扩展性和有效性,表明其在大规模多机器人系统中的应用潜力。
🎯 应用场景
该研究成果可应用于各种多机器人系统,例如:仓库自动化、物流配送、环境探索、灾难救援和农业自动化等。通过去中心化的运动规划,可以实现大规模机器人集群的高效协同,提高任务完成效率,降低运营成本,并增强系统的鲁棒性和灵活性。未来,该方法有望推广到更复杂的机器人任务和环境。
📄 摘要(原文)
Unlabeled motion planning involves assigning a set of robots to target locations while ensuring collision avoidance, aiming to minimize the total distance traveled. The problem forms an essential building block for multi-robot systems in applications such as exploration, surveillance, and transportation. We address this problem in a decentralized setting where each robot knows only the positions of its $k$-nearest robots and $k$-nearest targets. This scenario combines elements of combinatorial assignment and continuous-space motion planning, posing significant scalability challenges for traditional centralized approaches. To overcome these challenges, we propose a decentralized policy learned via a Graph Neural Network (GNN). The GNN enables robots to determine (1) what information to communicate to neighbors and (2) how to integrate received information with local observations for decision-making. We train the GNN using imitation learning with the centralized Hungarian algorithm as the expert policy, and further fine-tune it using reinforcement learning to avoid collisions and enhance performance. Extensive empirical evaluations demonstrate the scalability and effectiveness of our approach. The GNN policy trained on 100 robots generalizes to scenarios with up to 500 robots, outperforming state-of-the-art solutions by 8.6\% on average and significantly surpassing greedy decentralized methods. This work lays the foundation for solving multi-robot coordination problems in settings where scalability is important.