The Duke Humanoid: Design and Control For Energy Efficient Bipedal Locomotion Using Passive Dynamics
作者: Boxi Xia, Bokuan Li, Jacob Lee, Michael Scutari, Boyuan Chen
分类: cs.RO
发布日期: 2024-09-29 (更新: 2025-03-14)
💡 一句话要点
提出基于被动动力学的杜克人形机器人,实现高能效双足行走
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 双足行走 强化学习 被动动力学 能量效率
📋 核心要点
- 现有双足机器人行走能效不高,难以长时间稳定运动,需要探索更节能的控制策略。
- 利用强化学习,鼓励机器人利用自身被动动力学特性,减少主动控制的能量消耗。
- 实验表明,该方法在仿真和真实机器人上均能显著降低能量消耗,提升行走效率。
📝 摘要(中文)
本文介绍了杜克人形机器人,这是一个开源的10自由度人形机器人,旨在为步态研究提供一个可扩展的平台。该设计模仿了人体生理结构,在额状面上具有对称的身体对齐,以保持膝盖伸直时的静态平衡。我们开发了一种强化学习策略,可以零样本部署在硬件上,用于速度跟踪行走任务。此外,为了提高步态的能量效率,我们提出了一种端到端的强化学习算法,鼓励机器人利用被动动力学。实验结果表明,我们的被动策略在仿真中将运输成本降低了高达50%,在实际测试中降低了31%。
🔬 方法详解
问题定义:现有双足机器人在行走过程中,过度依赖主动控制来维持平衡和运动,导致能量消耗过高,续航能力不足。如何设计一种控制策略,使机器人能够更有效地利用自身的被动动力学特性,从而降低能量消耗,是本文要解决的核心问题。
核心思路:本文的核心思路是,通过强化学习训练一个控制策略,该策略能够引导机器人利用其固有的被动动力学特性,例如重力、惯性等,来辅助行走。通过减少主动控制的干预,降低电机等执行器的能量消耗,从而提高整体的能量效率。
技术框架:该方法采用端到端的强化学习框架。首先,建立机器人运动学和动力学模型。然后,设计奖励函数,鼓励机器人实现期望的速度跟踪,并惩罚能量消耗。接着,使用强化学习算法(具体算法未知)训练控制策略。最后,将训练好的策略部署到真实的杜克人形机器人上进行测试。
关键创新:该方法最重要的创新点在于,它将强化学习与被动动力学相结合,通过奖励函数的设计,引导机器人学习如何利用自身的物理特性来辅助行走,从而实现更高的能量效率。与传统的基于模型的控制方法相比,该方法无需精确的动力学模型,具有更强的鲁棒性和适应性。
关键设计:奖励函数的设计是关键。奖励函数需要平衡速度跟踪的准确性和能量消耗的最小化。具体的奖励函数形式未知,但可能包含以下几个部分:速度跟踪误差的惩罚项、电机力矩的惩罚项、以及可能与机器人姿态相关的惩罚项,以鼓励机器人保持稳定的姿态。具体的网络结构未知,但可能采用Actor-Critic结构,Actor网络输出控制力矩,Critic网络评估当前状态的价值。
🖼️ 关键图片

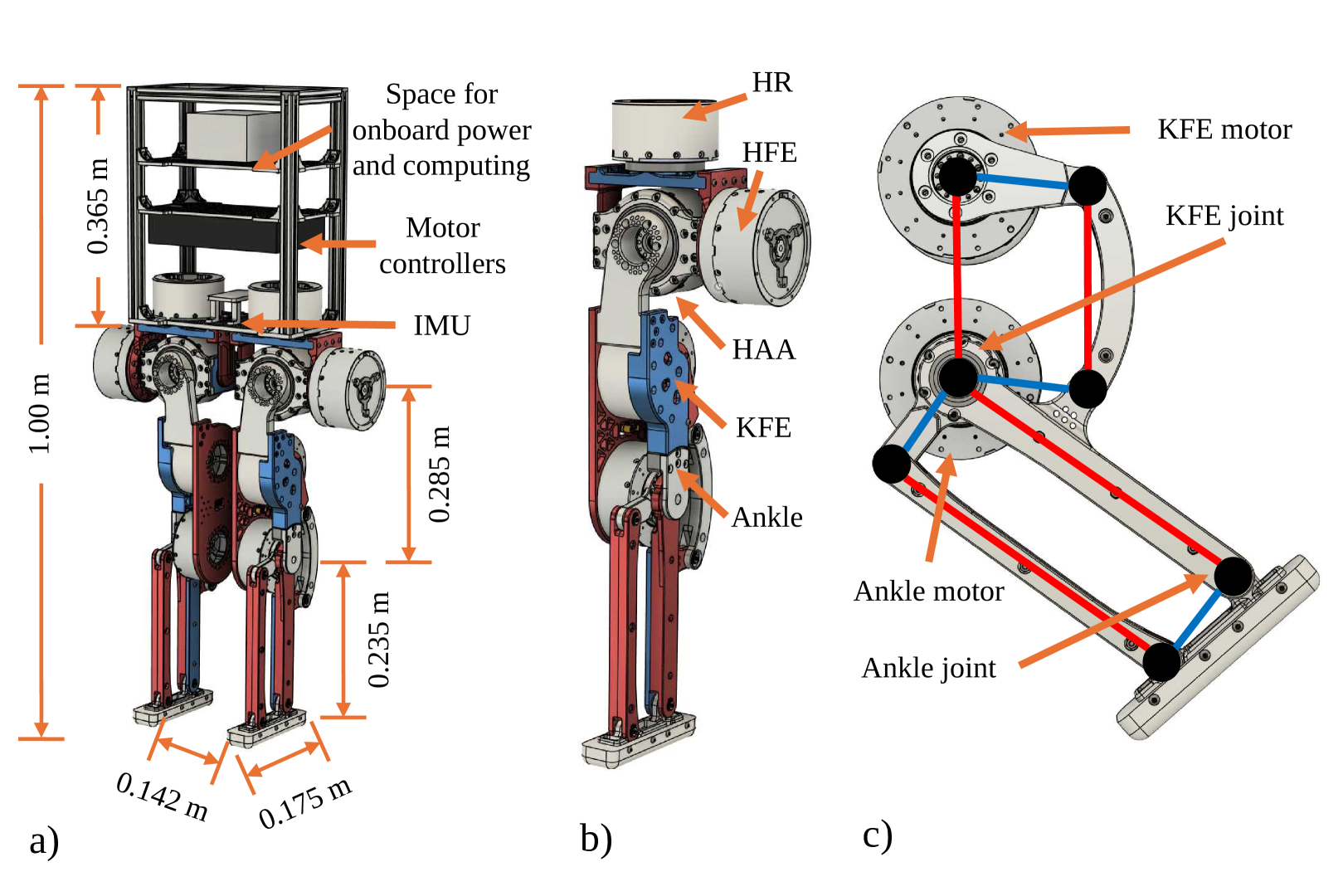

📊 实验亮点
实验结果表明,所提出的基于被动动力学的强化学习控制策略,在仿真环境中能够将运输成本(Cost of Transport, COT)降低高达50%,在真实机器人测试中降低31%。这表明该方法能够有效地提高双足机器人的能量效率,并具有良好的实际应用潜力。具体的对比基线未知,但推测是传统的基于模型的控制方法或不考虑被动动力学的强化学习方法。
🎯 应用场景
该研究成果可应用于人形机器人、外骨骼机器人等领域,尤其是在需要长时间自主运动的场景下,如搜救、巡检、物流等。通过降低能量消耗,可以延长机器人的续航时间,提高其工作效率和实用性。此外,该研究思路也可以推广到其他类型的机器人,例如四足机器人、轮式机器人等,以提高它们的能量效率。
📄 摘要(原文)
We present the Duke Humanoid, an open-source 10-degrees-of-freedom humanoid, as an extensible platform for locomotion research. The design mimics human physiology, with symmetrical body alignment in the frontal plane to maintain static balance with straight knees. We develop a reinforcement learning policy that can be deployed zero-shot on the hardware for velocity-tracking walking tasks. Additionally, to enhance energy efficiency in locomotion, we propose an end-to-end reinforcement learning algorithm that encourages the robot to leverage passive dynamics. Our experimental results show that our passive policy reduces the cost of transport by up to $50\%$ in simulation and $31\%$ in real-world tests. Our website is http://generalroboticslab.com/DukeHumanoidv1/ .