RoboNurse-VLA: Robotic Scrub Nurse System based on Vision-Language-Action Model
作者: Shunlei Li, Jin Wang, Rui Dai, Wanyu Ma, Wing Yin Ng, Yingbai Hu, Zheng Li
分类: cs.RO
发布日期: 2024-09-29
💡 一句话要点
提出基于视觉-语言-动作模型的RoboNurse-VLA机器人手术助手系统,提升手术效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人手术助手 视觉-语言-动作模型 手术器械递送 SAM 2 Llama 2 自主手术辅助 医疗机器人 语音控制
📋 核心要点
- 现有机器人手术助手在复杂动态环境中精确抓取和递送手术器械方面存在挑战。
- RoboNurse-VLA通过集成SAM 2和Llama 2,构建视觉-语言-动作模型,实现语音控制下的精准器械操作。
- 实验表明,RoboNurse-VLA在手术器械递送方面优于现有模型,即使面对未知工具也能保持高成功率。
📝 摘要(中文)
本文介绍了一种新型机器人手术助手系统RoboNurse-VLA,该系统基于视觉-语言-动作(VLA)模型,集成了Segment Anything Model 2(SAM 2)和Llama 2语言模型。RoboNurse-VLA能够根据外科医生的语音指令,实时、高精度地抓取和递送手术器械。通过利用最先进的视觉和语言模型,该系统可以解决物体检测、姿态优化以及处理复杂和难以抓取的器械等关键挑战。广泛的评估表明,RoboNurse-VLA相比现有模型表现出卓越的性能,即使在处理未见过的工具和具有挑战性的物品时,也能实现很高的手术器械递送成功率。这项工作代表了自主手术辅助领域的重要一步,展示了集成VLA模型在现实医疗应用中的潜力。
🔬 方法详解
问题定义:现有机器人手术助手在手术室环境中,尤其是在处理复杂或难以抓取的器械时,难以准确地抓取和递送手术器械。这主要是由于物体检测精度不足、姿态优化困难以及对动态环境的适应性较差等问题,导致手术效率降低,甚至可能增加手术风险。
核心思路:RoboNurse-VLA的核心思路是利用视觉-语言-动作(VLA)模型,将外科医生的语音指令与机器人的视觉感知和动作执行相结合。通过这种方式,机器人能够理解医生的意图,并根据视觉信息精确地定位和操作手术器械。这种设计旨在提高手术效率,减少人为错误,并最终改善患者的治疗效果。
技术框架:RoboNurse-VLA系统主要包含三个模块:视觉感知模块、语言理解模块和动作执行模块。视觉感知模块使用Segment Anything Model 2 (SAM 2)进行物体分割和识别,提取手术器械的精确位置和姿态信息。语言理解模块使用Llama 2语言模型解析外科医生的语音指令,提取所需操作的语义信息。动作执行模块根据视觉感知和语言理解的结果,规划并执行机器人的抓取和递送动作。
关键创新:RoboNurse-VLA的关键创新在于将SAM 2和Llama 2集成到机器人手术助手系统中,构建了一个完整的VLA模型。与传统的基于规则或预编程的机器人系统相比,RoboNurse-VLA能够更好地理解医生的意图,并适应动态的手术环境。此外,SAM 2的强大分割能力和Llama 2的语言理解能力也显著提高了系统的鲁棒性和泛化能力。
关键设计:在视觉感知模块中,SAM 2被用于分割手术器械,并提取其精确的3D姿态信息。为了提高分割精度,系统可能采用了数据增强和微调等技术。在语言理解模块中,Llama 2被用于解析外科医生的语音指令,并将其转换为机器人可以理解的动作指令。为了提高语言理解的准确性,系统可能采用了领域自适应训练和上下文理解等技术。在动作执行模块中,系统可能采用了基于强化学习的动作规划算法,以优化机器人的抓取和递送动作。
🖼️ 关键图片


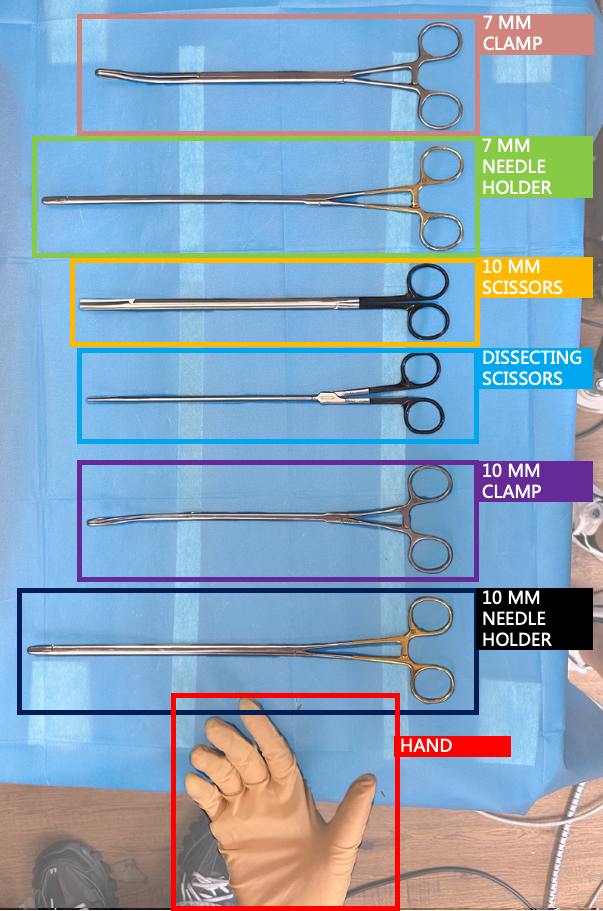
📊 实验亮点
RoboNurse-VLA在手术器械递送任务中表现出卓越的性能,相较于现有模型,即使在处理未见过的工具和具有挑战性的物品时,也能实现更高的成功率。具体性能数据和对比基线信息可在项目网站https://robonurse-vla.github.io 上找到,展示了VLA模型在自主手术辅助方面的巨大潜力。
🎯 应用场景
RoboNurse-VLA系统具有广泛的应用前景,可应用于各类外科手术中,尤其是在需要高精度和高效率的微创手术和复杂手术中。该系统能够减轻外科医生的工作负担,提高手术效率,减少人为错误,并最终改善患者的治疗效果。未来,该技术还可扩展到其他医疗领域,如康复护理和远程医疗等。
📄 摘要(原文)
In modern healthcare, the demand for autonomous robotic assistants has grown significantly, particularly in the operating room, where surgical tasks require precision and reliability. Robotic scrub nurses have emerged as a promising solution to improve efficiency and reduce human error during surgery. However, challenges remain in terms of accurately grasping and handing over surgical instruments, especially when dealing with complex or difficult objects in dynamic environments. In this work, we introduce a novel robotic scrub nurse system, RoboNurse-VLA, built on a Vision-Language-Action (VLA) model by integrating the Segment Anything Model 2 (SAM 2) and the Llama 2 language model. The proposed RoboNurse-VLA system enables highly precise grasping and handover of surgical instruments in real-time based on voice commands from the surgeon. Leveraging state-of-the-art vision and language models, the system can address key challenges for object detection, pose optimization, and the handling of complex and difficult-to-grasp instruments. Through extensive evaluations, RoboNurse-VLA demonstrates superior performance compared to existing models, achieving high success rates in surgical instrument handovers, even with unseen tools and challenging items. This work presents a significant step forward in autonomous surgical assistance, showcasing the potential of integrating VLA models for real-world medical applications. More details can be found at https://robonurse-vla.github.io.