Learning to Bridge the Gap: Efficient Novelty Recovery with Planning and Reinforcement Learning
作者: Alicia Li, Nishanth Kumar, Tomás Lozano-Pérez, Leslie Kaelbling
分类: cs.RO, cs.AI
发布日期: 2024-09-28
💡 一句话要点
提出一种基于规划和强化学习的桥接策略,用于解决机器人部署中模型未知的环境新颖性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人导航 强化学习 模型预测控制 环境新颖性 桥接策略
📋 核心要点
- 现有基于模型的规划方法在面对机器人部署中未知的环境新颖性时表现脆弱。
- 提出一种基于强化学习的“桥接策略”,通过学习何时调用规划器来适应新颖性。
- 实验表明,该方法比纯强化学习等基线方法能更有效地适应新颖性,并具有泛化能力。
📝 摘要(中文)
现实世界是不可预测的。因此,为了解决自主机器人的长时程决策问题,我们必须构建能够适应部署过程中环境变化的智能体。基于模型的规划方法可以使机器人在各种环境中解决复杂的长时程任务。然而,当部署到具有底层模型未考虑的新颖情况的环境中时,这些方法往往会变得脆弱。在这项工作中,我们提出通过强化学习(RL)学习一种“桥接策略”来适应这种新颖性。我们为这种学习引入了一个简单的公式,其中RL问题是用一个特殊的“CallPlanner”动作构建的,该动作终止桥接策略并将智能体的控制权交还给规划器。这使得RL策略能够学习查询规划器并遵循返回的计划将实现目标的那些状态集合。我们表明,这种公式能够通过利用规划器的知识来避免由稀疏奖励引起的具有挑战性的长时程探索,从而使智能体能够快速学习。在跨越三个不同复杂度的模拟领域的实验中,我们证明了我们的方法能够比包括纯RL基线在内的几种基线更有效地学习适应新颖性的策略。我们还证明了学习到的桥接策略是可泛化的,因为它可以与规划器结合使用,使智能体能够解决具有多个遇到的新颖性实例的更复杂任务。
🔬 方法详解
问题定义:论文旨在解决机器人自主导航中,当环境出现规划器模型未知的变化(新颖性)时,如何快速适应并完成任务的问题。现有基于模型的规划方法依赖于精确的环境模型,一旦出现模型未覆盖的情况,就会失效,导致任务失败。纯强化学习方法虽然可以学习适应环境,但面对长时程任务和稀疏奖励时,探索效率低下,难以快速学习。
核心思路:论文的核心思想是结合规划器和强化学习的优势。规划器负责处理已知环境,强化学习负责学习如何应对新颖性。通过学习一个“桥接策略”,智能体可以在遇到新颖性时,暂时切换到强化学习策略,学习如何克服新颖性,并在合适的时候将控制权交还给规划器。这种方式利用了规划器的先验知识,避免了纯强化学习的盲目探索。
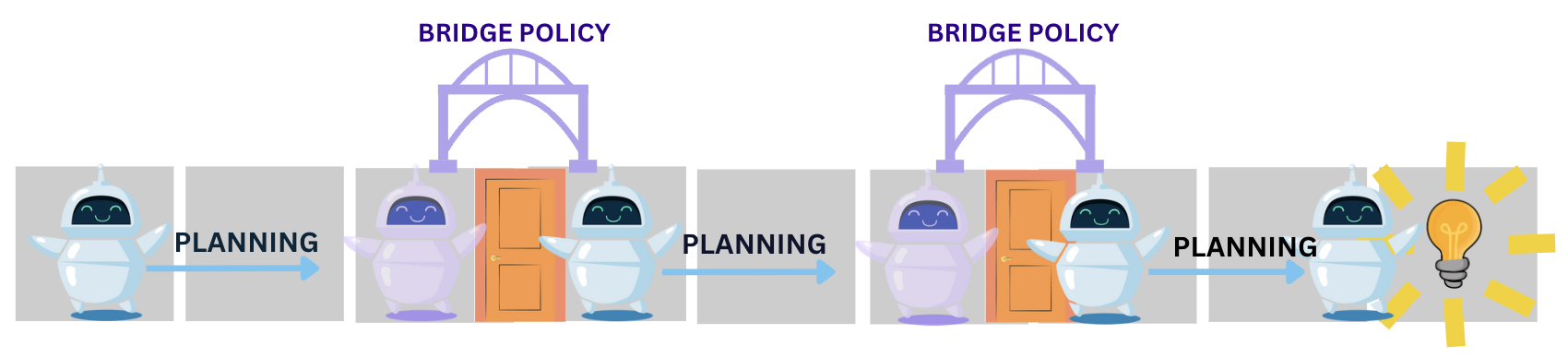
技术框架:整体框架包含两个主要部分:规划器和桥接策略。规划器使用传统的基于模型的规划算法,例如A*或RRT。桥接策略是一个强化学习策略,它接收当前状态作为输入,并输出一个动作。特别地,桥接策略包含一个特殊的“CallPlanner”动作。当桥接策略选择“CallPlanner”动作时,控制权会交还给规划器,规划器会重新规划路径。整个流程如下:智能体首先尝试使用规划器进行导航。如果遇到规划器无法处理的新颖性,则激活桥接策略。桥接策略执行动作,直到它认为规划器可以再次使用,此时它会选择“CallPlanner”动作。
关键创新:论文的关键创新在于“CallPlanner”动作的设计。这个动作将规划器和强化学习策略无缝集成在一起,允许智能体在两者之间动态切换。这种设计避免了从头开始学习整个任务的强化学习策略,而是专注于学习如何克服新颖性,从而提高了学习效率。此外,这种方法使得学习到的桥接策略具有一定的泛化能力,可以应用于不同的新颖性实例。
关键设计:桥接策略使用深度神经网络作为函数逼近器。损失函数通常是强化学习中的标准损失函数,例如Q-learning或Policy Gradient。奖励函数的设计至关重要,通常包含稀疏的目标奖励和一些中间奖励,例如鼓励探索或避免碰撞。具体参数设置(例如学习率、折扣因子、探索策略)需要根据具体任务进行调整。网络结构的选择也需要根据状态和动作空间的维度进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在三个不同的模拟环境中均优于基线方法,包括纯强化学习方法。具体来说,该方法能够更快地学习到适应新颖性的策略,并且学习到的策略具有更好的泛化能力,可以应用于多个新颖性实例。例如,在某个环境中,该方法比纯强化学习方法的学习速度提高了50%,并且能够成功解决包含多个新颖性实例的复杂任务。
🎯 应用场景
该研究成果可应用于各种自主机器人导航场景,尤其是在环境复杂、动态变化或存在未知因素的情况下。例如,在仓库机器人、家庭服务机器人、自动驾驶汽车等领域,该方法可以提高机器人在面对突发情况时的适应性和鲁棒性,从而提升整体性能和安全性。未来,该方法可以进一步扩展到更复杂的任务和环境,例如搜索救援、太空探索等。
📄 摘要(原文)
The real world is unpredictable. Therefore, to solve long-horizon decision-making problems with autonomous robots, we must construct agents that are capable of adapting to changes in the environment during deployment. Model-based planning approaches can enable robots to solve complex, long-horizon tasks in a variety of environments. However, such approaches tend to be brittle when deployed into an environment featuring a novel situation that their underlying model does not account for. In this work, we propose to learn a
bridge policy'' via Reinforcement Learning (RL) to adapt to such novelties. We introduce a simple formulation for such learning, where the RL problem is constructed with a specialCallPlanner'' action that terminates the bridge policy and hands control of the agent back to the planner. This allows the RL policy to learn the set of states in which querying the planner and following the returned plan will achieve the goal. We show that this formulation enables the agent to rapidly learn by leveraging the planner's knowledge to avoid challenging long-horizon exploration caused by sparse reward. In experiments across three different simulated domains of varying complexity, we demonstrate that our approach is able to learn policies that adapt to novelty more efficiently than several baselines, including a pure RL baseline. We also demonstrate that the learned bridge policy is generalizable in that it can be combined with the planner to enable the agent to solve more complex tasks with multiple instances of the encountered novelty.