Flat'n'Fold: A Diverse Multi-Modal Dataset for Garment Perception and Manipulation
作者: Lipeng Zhuang, Shiyu Fan, Yingdong Ru, Florent Audonnet, Paul Henderson, Gerardo Aragon-Camarasa
分类: cs.RO, cs.AI, cs.CV
发布日期: 2024-09-26
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
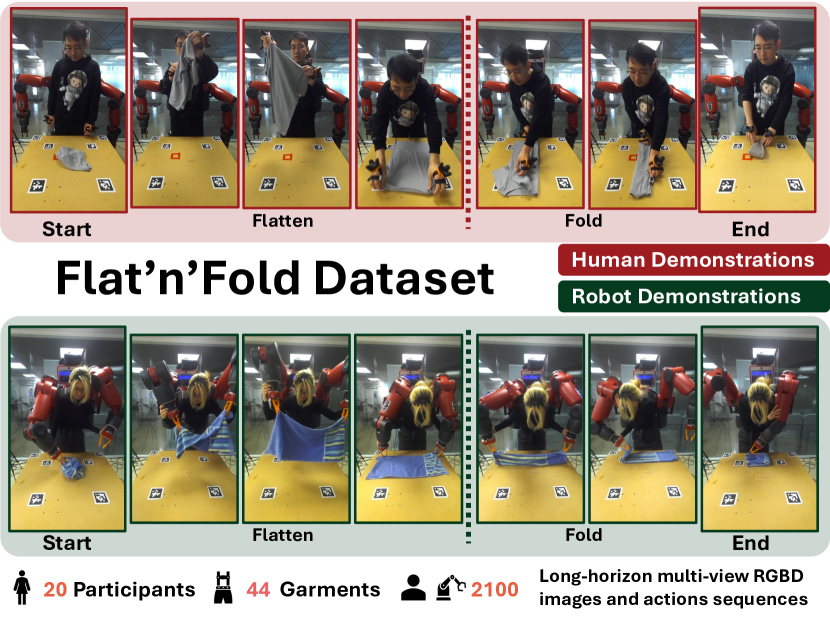
Flat'n'Fold:用于服装感知与操作的多模态数据集
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 服装操作 机器人感知 多模态数据集 抓取点预测 子任务分解 RGB-D图像 点云 数据集
📋 核心要点
- 现有服装操作数据集在规模、多样性和完整性方面存在不足,难以支持复杂操作任务的学习。
- Flat'n'Fold数据集通过收集大量人类和机器人演示,提供多视角RGB-D图像、点云和动作数据,全面捕捉服装操作过程。
- 实验表明,基于Flat'n'Fold数据集建立的抓取点预测和子任务分解基准,为未来研究提供了有价值的参考。
📝 摘要(中文)
本文提出了Flat'n'Fold,一个用于服装操作的大规模数据集,旨在弥补现有数据集的关键不足。该数据集包含1212个人类和887个机器人演示,涵盖8个类别共44种独特的服装的展平和折叠过程。Flat'n'Fold在规模、范围和多样性上均超越了以往的数据集。该数据集独特地捕捉了从褶皱到折叠状态的整个操作过程,提供了同步的多视角RGB-D图像、点云和动作数据,包括手或夹具的位置和旋转。我们量化了数据集的多样性和复杂性,并表明我们的数据集在视觉和动作信息方面具有真实世界演示的自然和多样性。为了展示Flat'n'Fold的效用,我们为抓取点预测和子任务分解建立了新的基准。我们对最先进模型在这些任务上的评估表明仍有很大的改进空间。这突显了Flat'n'Fold在推动可变形物体的机器人感知和操作方面取得进展的潜力。我们的数据集可在https://cvas-ug.github.io/flat-n-fold 下载。
🔬 方法详解
问题定义:现有服装操作数据集规模较小,缺乏多样性,难以覆盖真实场景中复杂的服装类型和操作方式。此外,现有数据集通常只关注操作的某个阶段,缺乏从初始状态到最终状态的完整过程记录,限制了对整个操作流程的理解和学习。
核心思路:Flat'n'Fold数据集的核心思路是通过收集大量真实世界的人类和机器人演示,构建一个大规模、多样化且完整的服装操作数据集。通过提供多视角RGB-D图像、点云和动作数据,全面捕捉服装操作过程,为机器人感知和操作算法的研究提供丰富的数据支持。
技术框架:Flat'n'Fold数据集的构建流程主要包括以下几个阶段:1) 服装选择:选择具有代表性的服装类型,涵盖不同的材质、形状和尺寸。2) 数据采集:通过人类和机器人演示,记录服装的展平和折叠过程。3) 数据标注:对采集到的数据进行标注,包括服装的类别、关键点位置、操作步骤等。4) 数据处理:对数据进行清洗、对齐和格式转换,生成多视角RGB-D图像、点云和动作数据。
关键创新:Flat'n'Fold数据集的关键创新在于其规模、多样性和完整性。相比于以往的数据集,Flat'n'Fold包含更多种类的服装、更丰富的操作方式和更完整的操作过程记录。此外,Flat'n'Fold还提供了同步的多视角RGB-D图像、点云和动作数据,为多模态感知和操作算法的研究提供了便利。
关键设计:在数据采集方面,Flat'n'Fold采用了多种视角和光照条件,以增加数据的多样性。在数据标注方面,Flat'n'Fold采用了人工标注和自动标注相结合的方式,以提高标注的准确性和效率。在数据处理方面,Flat'n'Fold采用了多种数据增强技术,以增加数据的泛化能力。
🖼️ 关键图片


📊 实验亮点
Flat'n'Fold数据集在抓取点预测和子任务分解任务上建立了新的基准。实验结果表明,现有最先进的模型在这些任务上仍有很大的改进空间,例如在抓取点预测任务上,模型的准确率还有显著提升空间。这表明Flat'n'Fold数据集具有挑战性,能够有效地推动相关算法的发展。
🎯 应用场景
Flat'n'Fold数据集可广泛应用于服装行业的自动化和智能化。例如,可用于开发智能服装折叠机器人,提高服装生产和仓储的效率。此外,还可用于开发虚拟试衣系统,为消费者提供更便捷的购物体验。该数据集的发布将促进机器人感知和操作算法的发展,推动服装行业的智能化转型。
📄 摘要(原文)
We present Flat'n'Fold, a novel large-scale dataset for garment manipulation that addresses critical gaps in existing datasets. Comprising 1,212 human and 887 robot demonstrations of flattening and folding 44 unique garments across 8 categories, Flat'n'Fold surpasses prior datasets in size, scope, and diversity. Our dataset uniquely captures the entire manipulation process from crumpled to folded states, providing synchronized multi-view RGB-D images, point clouds, and action data, including hand or gripper positions and rotations. We quantify the dataset's diversity and complexity compared to existing benchmarks and show that our dataset features natural and diverse manipulations of real-world demonstrations of human and robot demonstrations in terms of visual and action information. To showcase Flat'n'Fold's utility, we establish new benchmarks for grasping point prediction and subtask decomposition. Our evaluation of state-of-the-art models on these tasks reveals significant room for improvement. This underscores Flat'n'Fold's potential to drive advances in robotic perception and manipulation of deformable objects. Our dataset can be downloaded at https://cvas-ug.github.io/flat-n-fold