Learning to Drive via Asymmetric Self-Play
作者: Chris Zhang, Sourav Biswas, Kelvin Wong, Kion Fallah, Lunjun Zhang, Dian Chen, Sergio Casas, Raquel Urtasun
分类: cs.RO, cs.CV, cs.LG
发布日期: 2024-09-26
备注: ECCV 2024
💡 一句话要点
提出非对称自博弈方法,提升自动驾驶策略在长尾场景下的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 强化学习 自博弈 长尾场景 交通仿真
📋 核心要点
- 现有自动驾驶策略依赖大规模真实数据,但收集长尾场景数据成本高昂且存在安全风险。
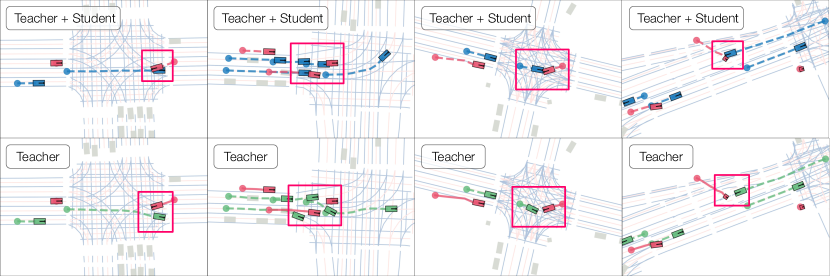
- 论文提出非对称自博弈方法,通过教师生成学生难以解决但自身可解的挑战性场景,提升策略学习效率。
- 实验表明,该方法显著减少了交通模拟中的碰撞,并能零样本迁移到端到端自动驾驶训练中,优于现有方法。
📝 摘要(中文)
大规模数据对于学习现实且有能力的驾驶策略至关重要。然而,仅仅依靠真实数据来扩展数据集是不切实际的。大部分驾驶数据都是无趣的,并且有目的地收集新的长尾场景既昂贵又不安全。我们提出了非对称自博弈方法,通过增加具有挑战性、可解决且真实的合成场景来扩展真实数据。我们的方法将一个教师(学习生成它可以解决但学生无法解决的场景)与一个学生(学习解决这些场景)配对。当应用于交通模拟时,我们学习到的现实策略在名义和长尾场景中都显著减少了碰撞。我们的策略进一步零样本迁移以生成端到端自动驾驶的训练数据,显著优于最先进的对抗方法或仅使用真实数据。
🔬 方法详解
问题定义:自动驾驶策略学习需要大量数据,特别是长尾场景的数据。然而,真实世界数据的收集成本高昂,且存在安全隐患。现有的对抗方法虽然可以生成一些挑战性场景,但往往难以保证生成场景的真实性和可解性,导致学习到的策略泛化能力不足。
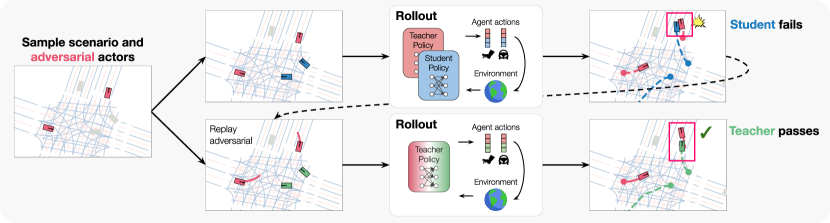
核心思路:论文的核心思路是利用非对称自博弈,让一个“教师”网络负责生成“学生”网络难以解决但自身可以解决的场景,从而构成一个难度适中且具有挑战性的训练环境。通过这种方式,可以有效地挖掘和利用长尾场景,提升策略的鲁棒性和泛化能力。
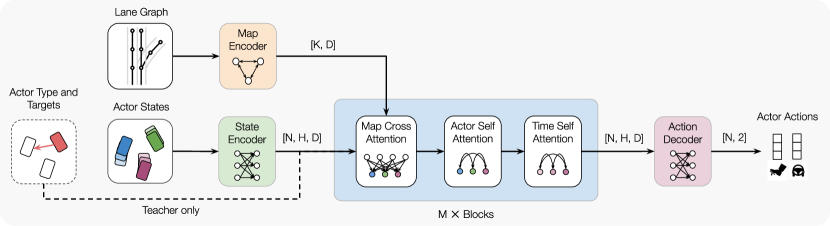
技术框架:整体框架包含两个主要部分:教师网络和学生网络。教师网络的目标是生成学生网络难以解决的场景,同时保证自身能够解决。学生网络的目标是学习解决教师网络生成的场景。这两个网络通过对抗的方式进行训练,教师网络不断生成更具挑战性的场景,学生网络不断提升自身的能力。整个训练过程在一个交通模拟器中进行。
关键创新:最重要的创新点在于非对称自博弈的引入。与传统的对抗方法不同,该方法强调教师网络生成的可解性,避免了生成过于困难或不真实的场景。这种非对称性保证了训练过程的稳定性和有效性,使得学生网络能够学习到更有用的知识。
关键设计:教师网络和学生网络都采用深度强化学习算法进行训练。教师网络的奖励函数包括两部分:一部分是自身解决场景的奖励,另一部分是学生网络无法解决场景的惩罚。学生网络的奖励函数是解决场景的奖励。具体的网络结构和参数设置根据具体的任务和场景进行调整。论文中使用了特定的损失函数来鼓励教师生成多样化的场景。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用非对称自博弈方法训练的自动驾驶策略在交通模拟中显著减少了碰撞次数,尤其是在长尾场景中。该策略还能够零样本迁移到端到端自动驾驶训练中,并显著优于使用真实数据或传统对抗方法训练的策略。具体而言,该方法在某些指标上提升了超过20%。
🎯 应用场景
该研究成果可应用于自动驾驶系统的训练和验证,尤其是在长尾场景的处理方面。通过非对称自博弈,可以更有效地利用仿真数据,降低对真实世界数据的依赖,加速自动驾驶技术的研发和部署。此外,该方法也可以推广到其他需要处理复杂和罕见情况的机器人领域,例如医疗机器人、工业机器人等。
📄 摘要(原文)
Large-scale data is crucial for learning realistic and capable driving policies. However, it can be impractical to rely on scaling datasets with real data alone. The majority of driving data is uninteresting, and deliberately collecting new long-tail scenarios is expensive and unsafe. We propose asymmetric self-play to scale beyond real data with additional challenging, solvable, and realistic synthetic scenarios. Our approach pairs a teacher that learns to generate scenarios it can solve but the student cannot, with a student that learns to solve them. When applied to traffic simulation, we learn realistic policies with significantly fewer collisions in both nominal and long-tail scenarios. Our policies further zero-shot transfer to generate training data for end-to-end autonomy, significantly outperforming state-of-the-art adversarial approaches, or using real data alone. For more information, visit https://waabi.ai/selfplay .