Cat-and-Mouse Satellite Dynamics: Divergent Adversarial Reinforcement Learning for Contested Multi-Agent Space Operations
作者: Cameron Mehlman, Joseph Abramov, Gregory Falco
分类: cs.RO
发布日期: 2024-09-26
💡 一句话要点
提出Divergent Adversarial RL,解决复杂对抗环境下卫星自主规避问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 对抗学习 卫星规避 空间安全 自主导航
📋 核心要点
- 现有太空自主系统在对抗环境中表现不足,尤其是在卫星追逐等场景下,缺乏有效的规避策略。
- DARL通过两阶段MARL,鼓励对抗策略的多样性,从而提升规避模型的鲁棒性和适应性。
- 实验表明,DARL在猫捉老鼠卫星场景中优于基于优化的路径规划器,验证了其有效性。
📝 摘要(中文)
随着太空环境日益拥挤和竞争激烈,多智能体环境下鲁棒的自主能力变得至关重要。目前太空自主系统主要依赖于基于优化的路径规划或远距离轨道机动,但尚未证明在卫星主动追逐的对抗场景中有效。我们提出了一种两阶段的多智能体强化学习方法,即Divergent Adversarial Reinforcement Learning (DARL),旨在训练卫星在与多个对抗航天器交战时的自主规避策略。我们的方法通过促进多样化的对抗策略来增强训练期间的探索,从而产生更鲁棒和适应性更强的规避模型。我们通过一个猫捉老鼠的卫星场景验证了DARL,该场景被建模为一个部分可观察的多智能体夺旗游戏,其中两个对抗性的“猫”航天器追逐一个“老鼠”规避者。DARL的性能与包括基于优化的卫星路径规划器在内的多个基准进行了比较,证明了其为对抗性多智能体空间环境生成高度鲁棒模型的能力。
🔬 方法详解
问题定义:论文旨在解决在复杂对抗性空间环境中,单个卫星如何有效地规避多个敌对卫星的追捕。现有方法,如基于优化的路径规划,在面对主动对抗时,难以保证规避策略的鲁棒性和适应性。这些方法通常依赖于预先设定的规则或假设,无法充分应对敌方策略的多样性。
核心思路:论文的核心思路是利用多智能体强化学习(MARL),通过训练多个具有不同策略的“猫”卫星,来提高“老鼠”卫星规避策略的鲁棒性。通过鼓励“猫”卫星策略的多样性,可以使“老鼠”卫星接触到更广泛的对抗场景,从而学习到更有效的规避策略。这种对抗训练的方式能够提升模型在未知环境下的泛化能力。
技术框架:DARL是一个两阶段的MARL框架。第一阶段,训练多个“猫”卫星,并鼓励它们发展出不同的追捕策略。这通常通过引入策略多样性奖励或惩罚机制来实现。第二阶段,使用训练好的“猫”卫星作为对手,训练“老鼠”卫星的规避策略。整个框架可以看作是一个对抗生成网络(GAN)的变体,其中“猫”卫星生成对抗样本,“老鼠”卫星学习防御这些样本。
关键创新:DARL的关键创新在于其对对抗策略多样性的强调。传统的对抗训练方法通常只关注于生成最强的对抗样本,而忽略了对抗样本的多样性。DARL通过鼓励对抗策略的多样性,使得训练出的规避模型能够更好地适应各种未知的对抗场景。这种方法可以显著提高模型的鲁棒性和泛化能力。
关键设计:在具体实现上,论文可能采用了以下关键设计:1) 使用不同的奖励函数来鼓励“猫”卫星发展不同的追捕策略。例如,可以对策略相似的“猫”卫星进行惩罚。2) 使用不同的网络结构或参数初始化来增加“猫”卫星策略的多样性。3) 使用经验回放池来存储“猫”卫星的策略,并从中采样不同的策略来训练“老鼠”卫星。4) 损失函数可能包含对抗损失和规避损失,以平衡规避的成功率和规避的代价。
🖼️ 关键图片

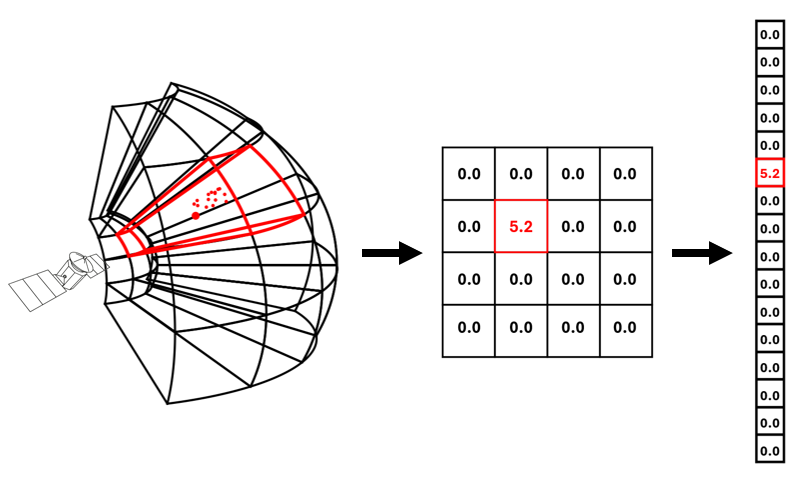
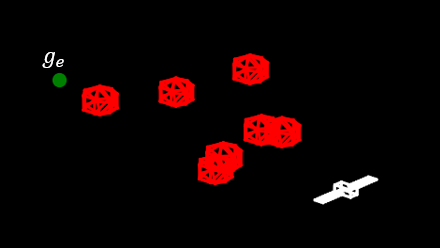
📊 实验亮点
DARL在猫捉老鼠卫星场景中,与基于优化的卫星路径规划器相比,展现出更强的规避能力和鲁棒性。具体性能数据未知,但论文强调DARL能够生成高度鲁棒的模型,表明其在对抗环境下的性能优于传统方法。通过促进多样化的对抗策略,DARL显著提升了规避模型的适应性。
🎯 应用场景
该研究成果可应用于提升卫星在轨安全,尤其是在日益拥挤和竞争激烈的太空环境中。通过自主规避敌对卫星的威胁,可以保护重要空间资产,维护国家安全。此外,该方法还可以推广到其他多智能体对抗场景,如无人机集群防御、网络安全等领域,具有广泛的应用前景。
📄 摘要(原文)
As space becomes increasingly crowded and contested, robust autonomous capabilities for multi-agent environments are gaining critical importance. Current autonomous systems in space primarily rely on optimization-based path planning or long-range orbital maneuvers, which have not yet proven effective in adversarial scenarios where one satellite is actively pursuing another. We introduce Divergent Adversarial Reinforcement Learning (DARL), a two-stage Multi-Agent Reinforcement Learning (MARL) approach designed to train autonomous evasion strategies for satellites engaged with multiple adversarial spacecraft. Our method enhances exploration during training by promoting diverse adversarial strategies, leading to more robust and adaptable evader models. We validate DARL through a cat-and-mouse satellite scenario, modeled as a partially observable multi-agent capture the flag game where two adversarial
cat' spacecraft pursue a singlemouse' evader. DARL's performance is compared against several benchmarks, including an optimization-based satellite path planner, demonstrating its ability to produce highly robust models for adversarial multi-agent space environments.