Achieving Stable High-Speed Locomotion for Humanoid Robots with Deep Reinforcement Learning
作者: Xinming Zhang, Xianghui Wang, Lerong Zhang, Guodong Guo, Xiaoyu Shen, Wei Zhang
分类: cs.RO
发布日期: 2024-09-25
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
提出基于深度强化学习与运动学先验知识的人形机器人稳定高速运动控制方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人形机器人 深度强化学习 运动控制 高速运动 运动学先验
📋 核心要点
- 人形机器人高速行走和奔跑能力仍然面临挑战,尤其是在维持稳定性的前提下。
- 该方法结合深度强化学习与运动学先验,通过协调手臂运动来抵消不稳定力,提升整体稳定性。
- 仿真结果表明,该方法能使人形机器人以3.5m/s的速度稳定运动,并在高保真环境中验证了其鲁棒性。
📝 摘要(中文)
本文提出了一种结合深度强化学习与运动学先验知识的稳定运动控制(KSLC)方法,旨在实现人形机器人的稳定高速运动。KSLC通过协调手臂运动来抵消不稳定的力,从而增强整体稳定性。与基线方法相比,KSLC能够更准确地跟踪指令速度,并在速度控制中表现出更好的泛化能力。在仿真测试中,配备KSLC的人形机器人成功地跟踪了3.5米/秒的目标速度,且波动更小。在高保真环境中的Sim-to-Sim验证进一步证实了其稳健的性能,突显了其在实际应用中的潜力。
🔬 方法详解
问题定义:人形机器人实现稳定高速运动是一个复杂的问题。现有的方法在高速运动时难以保持平衡,容易受到扰动的影响,并且在不同速度下的泛化能力有限。如何有效地控制人形机器人的运动,使其能够在高速运动的同时保持稳定,是本文要解决的核心问题。
核心思路:本文的核心思路是利用深度强化学习来学习一个运动控制器,该控制器能够根据机器人的状态和目标速度,生成合适的动作指令,从而实现稳定高速运动。同时,为了提高控制器的鲁棒性和泛化能力,引入了运动学先验知识,指导控制器的学习过程。通过协调手臂的运动,抵消不稳定的力,从而增强整体的稳定性。
技术框架:该方法的技术框架主要包括以下几个模块:1)状态观测模块:用于获取机器人的当前状态,包括位置、速度、姿态等信息。2)运动学先验模块:提供运动学约束和先验知识,例如关节角度限制、力矩限制等。3)深度强化学习模块:使用深度神经网络作为策略网络,通过强化学习算法(例如PPO)进行训练,学习最优的运动控制策略。4)动作执行模块:将策略网络输出的动作指令发送给机器人,控制其运动。
关键创新:该方法最重要的技术创新点在于将深度强化学习与运动学先验知识相结合。传统的深度强化学习方法通常需要大量的训练数据才能学习到有效的控制策略,而引入运动学先验知识可以有效地减少训练数据的需求,提高学习效率和泛化能力。此外,通过协调手臂运动来增强整体稳定性的策略也是一个重要的创新点。
关键设计:在深度强化学习模块中,使用了PPO算法进行训练。策略网络采用多层感知机(MLP)结构,输入是机器人的状态信息和目标速度,输出是机器人的关节力矩。损失函数包括奖励函数和正则化项,奖励函数用于鼓励机器人跟踪目标速度并保持稳定,正则化项用于约束关节力矩的大小。运动学先验知识通过约束关节角度和力矩的范围来实现。
🖼️ 关键图片
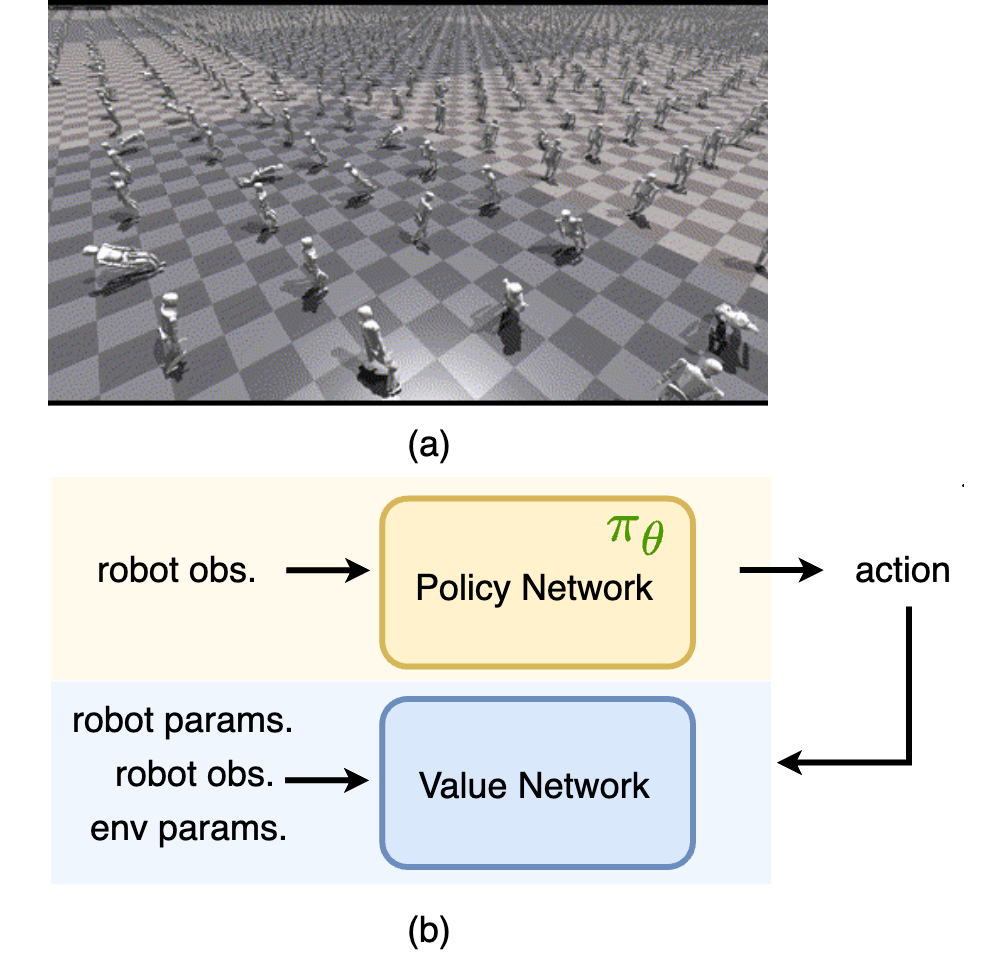


📊 实验亮点
在仿真实验中,该方法成功地使人形机器人以3.5米/秒的速度稳定运动,与基线方法相比,速度跟踪误差显著降低,波动更小。在高保真仿真环境中进行的Sim-to-Sim验证表明,该方法具有良好的鲁棒性和泛化能力,能够适应不同的环境和任务。
🎯 应用场景
该研究成果可应用于人形机器人在复杂环境下的搜索救援、物流运输、以及需要高机动性的工业场景。通过提升人形机器人的运动能力,可以使其在更多领域替代人类完成危险或重复性工作,具有重要的实际应用价值和广阔的发展前景。未来,该技术有望进一步推广到其他类型的机器人,例如四足机器人和轮式机器人。
📄 摘要(原文)
Humanoid robots offer significant versatility for performing a wide range of tasks, yet their basic ability to walk and run, especially at high velocities, remains a challenge. This letter presents a novel method that combines deep reinforcement learning with kinodynamic priors to achieve stable locomotion control (KSLC). KSLC promotes coordinated arm movements to counteract destabilizing forces, enhancing overall stability. Compared to the baseline method, KSLC provides more accurate tracking of commanded velocities and better generalization in velocity control. In simulation tests, the KSLC-enabled humanoid robot successfully tracked a target velocity of 3.5 m/s with reduced fluctuations. Sim-to-sim validation in a high-fidelity environment further confirmed its robust performance, highlighting its potential for real-world applications.