Stage-Wise Reward Shaping for Acrobatic Robots: A Constrained Multi-Objective Reinforcement Learning Approach
作者: Dohyeong Kim, Hyeokjin Kwon, Junseok Kim, Gunmin Lee, Songhwai Oh
分类: cs.RO, cs.AI
发布日期: 2024-09-24
备注: 7 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于阶段式奖励塑造的约束多目标强化学习方法,用于解决杂技机器人控制问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 约束多目标优化 奖励塑造 杂技机器人 阶段式学习
📋 核心要点
- 传统强化学习奖励函数设计复杂,难以处理复杂任务,尤其是在杂技机器人等需要精细控制的场景。
- 将任务分解为多个阶段,为每个阶段定义独立的奖励和成本函数,利用约束多目标强化学习框架优化。
- 在模拟和真实杂技机器人任务中验证了该方法的有效性,性能优于现有强化学习和约束强化学习算法。
📝 摘要(中文)
随着强化学习(RL)解决的任务复杂性增加,奖励函数的定义也变得高度复杂。本文提出了一种强化学习方法,旨在通过直观的策略简化奖励塑造过程。首先,我们没有使用由各种项组成的单一奖励函数,而是在约束多目标强化学习(CMORL)框架内定义了多个奖励和成本函数。对于涉及顺序复杂运动的任务,我们将任务分割成不同的阶段,并为每个阶段定义多个奖励和成本。最后,我们提出了一种实用的CMORL算法,该算法在满足成本定义的约束条件下,最大化基于这些奖励的目标。所提出的方法已在模拟和真实环境中的各种杂技任务中成功演示。此外,与现有的RL和约束RL算法相比,它已成功地执行了任务。我们的代码可在https://github.com/rllab-snu/Stage-Wise-CMORL上找到。
🔬 方法详解
问题定义:现有的强化学习方法在处理复杂任务时,往往需要设计复杂的奖励函数,这使得训练过程难以收敛,且对奖励函数的微小变化非常敏感。尤其是在杂技机器人控制等任务中,需要精确控制机器人的运动轨迹,单一的奖励函数难以同时兼顾多个目标,例如平衡、速度、姿态等。因此,如何设计一个简单、直观且有效的奖励函数,是解决复杂机器人控制问题的关键挑战。
核心思路:本文的核心思路是将复杂的任务分解为多个阶段,每个阶段都有其特定的目标和约束。针对每个阶段,设计独立的奖励函数和成本函数,奖励函数用于鼓励agent完成该阶段的目标,成本函数用于约束agent的行为,避免出现不期望的动作。通过约束多目标强化学习(CMORL)框架,同时优化多个阶段的奖励,并满足成本约束,从而实现对复杂任务的有效控制。
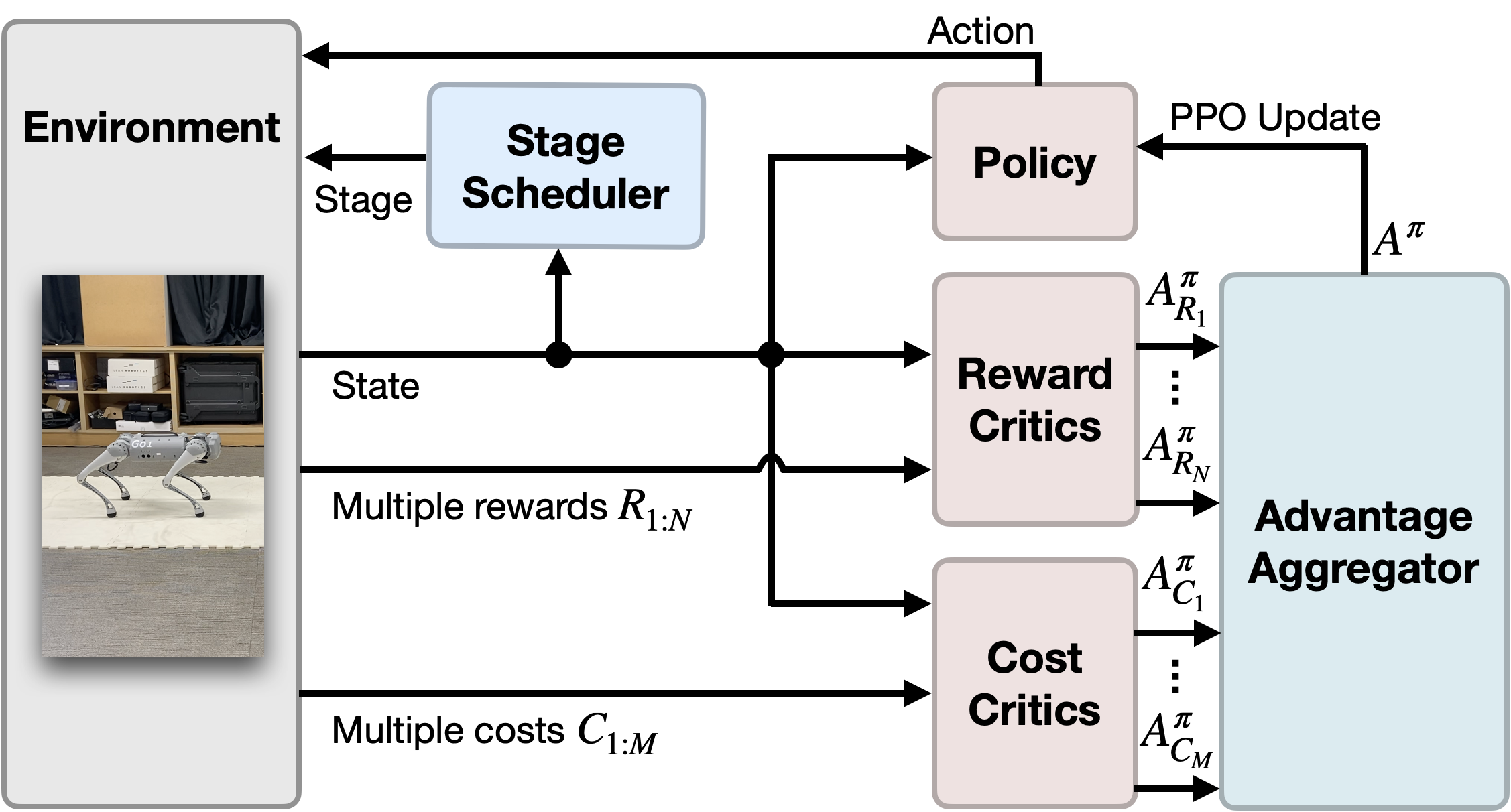
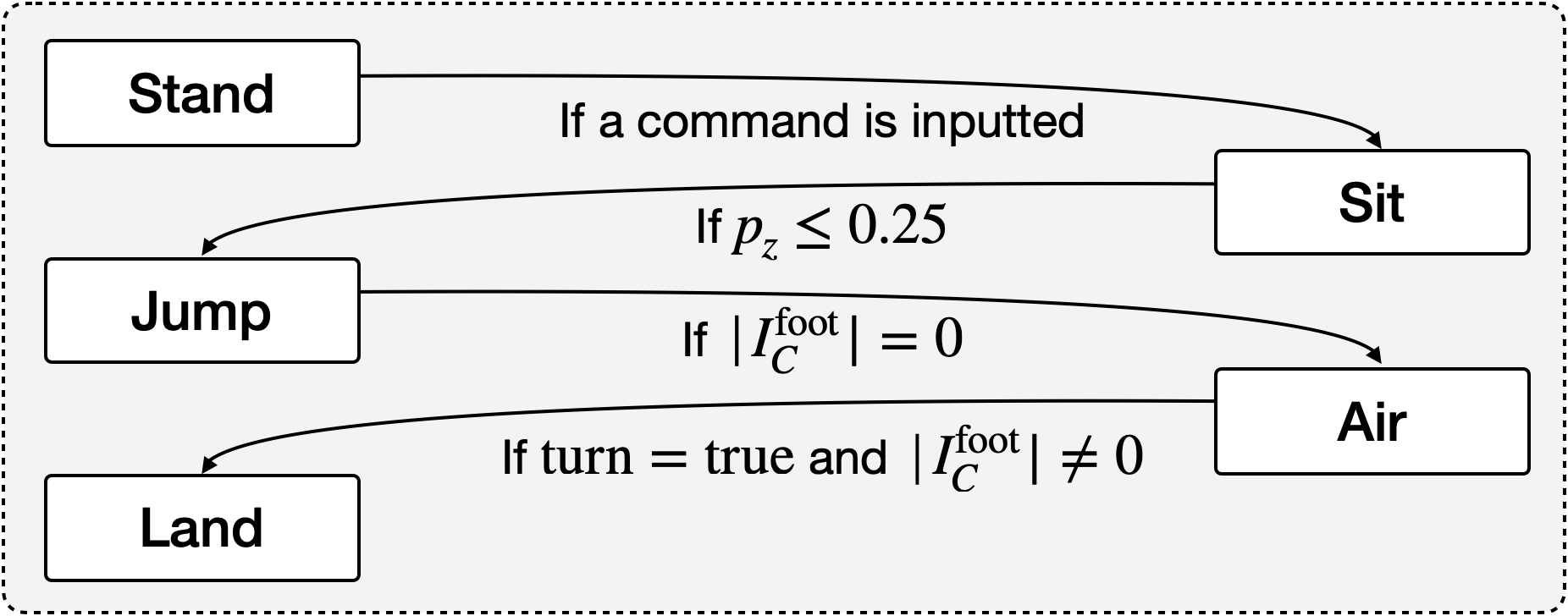
技术框架:该方法采用阶段式约束多目标强化学习(Stage-Wise CMORL)框架。首先,将任务分解为多个阶段。然后,为每个阶段定义奖励函数和成本函数。接着,使用CMORL算法训练agent,使其在满足成本约束的条件下,最大化每个阶段的奖励。最后,将各个阶段的策略组合起来,形成完整的控制策略。整体流程包括任务分解、奖励/成本函数设计、CMORL训练和策略组合四个主要步骤。
关键创新:该方法最重要的技术创新点在于将任务分解为多个阶段,并为每个阶段设计独立的奖励和成本函数。这种阶段式的奖励塑造方法,使得奖励函数的设计更加直观和简单,同时也更容易引导agent学习到期望的行为。与传统的单一奖励函数方法相比,该方法能够更好地处理复杂任务,并提高训练的稳定性和效率。
关键设计:在奖励函数设计方面,针对每个阶段的目标,设计相应的奖励项,例如,对于平衡阶段,可以设计与机器人姿态相关的奖励项。在成本函数设计方面,可以设计与机器人关节力矩相关的成本项,以避免机器人出现过大的力矩。在CMORL算法方面,可以使用现有的CMORL算法,例如基于拉格朗日乘子的CMORL算法。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片

📊 实验亮点
该方法在模拟和真实杂技机器人任务中进行了验证,实验结果表明,该方法能够有效地控制机器人完成各种复杂的杂技动作,例如翻滚、跳跃等。与现有的强化学习和约束强化学习算法相比,该方法在性能和鲁棒性方面均有显著提升。具体性能数据未知,但论文强调了成功执行任务并优于现有算法。
🎯 应用场景
该研究成果可应用于各种复杂机器人控制任务,例如人形机器人运动控制、无人机编队飞行、自动驾驶等。通过将复杂任务分解为多个阶段,并为每个阶段设计独立的奖励和成本函数,可以有效地提高控制策略的性能和鲁棒性。此外,该方法还可以应用于游戏AI、金融交易等领域,具有广泛的应用前景。
📄 摘要(原文)
As the complexity of tasks addressed through reinforcement learning (RL) increases, the definition of reward functions also has become highly complicated. We introduce an RL method aimed at simplifying the reward-shaping process through intuitive strategies. Initially, instead of a single reward function composed of various terms, we define multiple reward and cost functions within a constrained multi-objective RL (CMORL) framework. For tasks involving sequential complex movements, we segment the task into distinct stages and define multiple rewards and costs for each stage. Finally, we introduce a practical CMORL algorithm that maximizes objectives based on these rewards while satisfying constraints defined by the costs. The proposed method has been successfully demonstrated across a variety of acrobatic tasks in both simulation and real-world environments. Additionally, it has been shown to successfully perform tasks compared to existing RL and constrained RL algorithms. Our code is available at https://github.com/rllab-snu/Stage-Wise-CMORL.