SurgIRL: Towards Life-Long Learning for Surgical Automation by Incremental Reinforcement Learning
作者: Yun-Jie Ho, Zih-Yun Chiu, Yuheng Zhi, Michael C. Yip
分类: cs.RO, cs.LG
发布日期: 2024-09-24
💡 一句话要点
SurgIRL:基于增量强化学习的手术自动化终身学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 手术自动化 增量强化学习 终身学习 知识迁移 机器人学习
📋 核心要点
- 现有手术自动化策略独立开发,任务变更时重用性差,导致机器人学习多任务耗时。
- SurgIRL通过知识参考和增量学习,使机器人能够像外科医生一样逐步积累和复用手术技能。
- 实验表明,SurgIRL在仿真和真实机器人平台上均能有效学习和迁移手术自动化策略。
📝 摘要(中文)
本研究提出Surgical Incremental Reinforcement Learning (SurgIRL),旨在通过增量强化学习实现手术自动化的终身学习。SurgIRL模拟人类外科医生积累经验的方式,通过参考外部策略(知识)来获取新技能,并累积和重用这些技能来逐步解决多个未见过的任务。SurgIRL框架包含三个主要组成部分:首先,定义一个可扩展的知识集,其中包含对手术任务有帮助的异构策略;其次,提出Knowledge Inclusive Attention Network with mAximum Coverage Exploration (KIAN-ACE),通过最大化探索过程中知识集的覆盖率来提高学习效率;最后,开发基于KIAN-ACE的增量学习流程,以累积和重用学习到的知识,并按顺序解决多个手术任务。仿真实验表明,KIAN-ACE能够高效地单独或增量地学习自动化十个手术任务。此外,在达芬奇研究套件(dVRK)上评估了学习到的策略,并展示了成功的sim-to-real迁移。
🔬 方法详解
问题定义:现有手术自动化方法通常针对特定任务进行独立训练,缺乏通用性和可扩展性。当需要机器人执行新的手术任务时,往往需要从头开始训练新的策略,效率低下。此外,如何有效地利用已有的手术知识来加速新任务的学习也是一个挑战。
核心思路:SurgIRL的核心思路是借鉴人类外科医生学习的方式,通过增量学习和知识迁移,使机器人能够逐步掌握各种手术技能。具体来说,SurgIRL维护一个知识库,其中包含各种手术任务的策略。在学习新任务时,机器人会参考知识库中的相关策略,并利用增量学习的方法,逐步优化策略,最终完成任务。
技术框架:SurgIRL框架主要包含三个模块:1) 可扩展的知识集:存储异构的手术策略,作为学习新任务的知识来源。2) KIAN-ACE (Knowledge Inclusive Attention Network with mAximum Coverage Exploration):利用注意力机制选择合适的知识,并通过最大化知识覆盖率来提高探索效率。3) 增量学习流程:按顺序学习多个手术任务,并将学习到的知识添加到知识集中,实现知识的积累和复用。
关键创新:SurgIRL的关键创新在于KIAN-ACE,它能够有效地利用知识集中的信息来指导探索过程。传统的探索方法往往是随机的,效率较低。KIAN-ACE通过注意力机制选择与当前任务相关的知识,并利用这些知识来指导探索,从而提高了学习效率。此外,最大化知识覆盖率的设计也保证了探索的多样性,避免了陷入局部最优解。
关键设计:KIAN-ACE包含一个注意力网络,用于计算知识集中每个策略的权重。该网络以当前状态作为输入,输出每个策略的注意力权重。在探索过程中,机器人会根据注意力权重选择策略,并执行相应的动作。损失函数的设计目标是最大化知识集的覆盖率,即尽可能多地利用知识集中的策略。具体的网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片


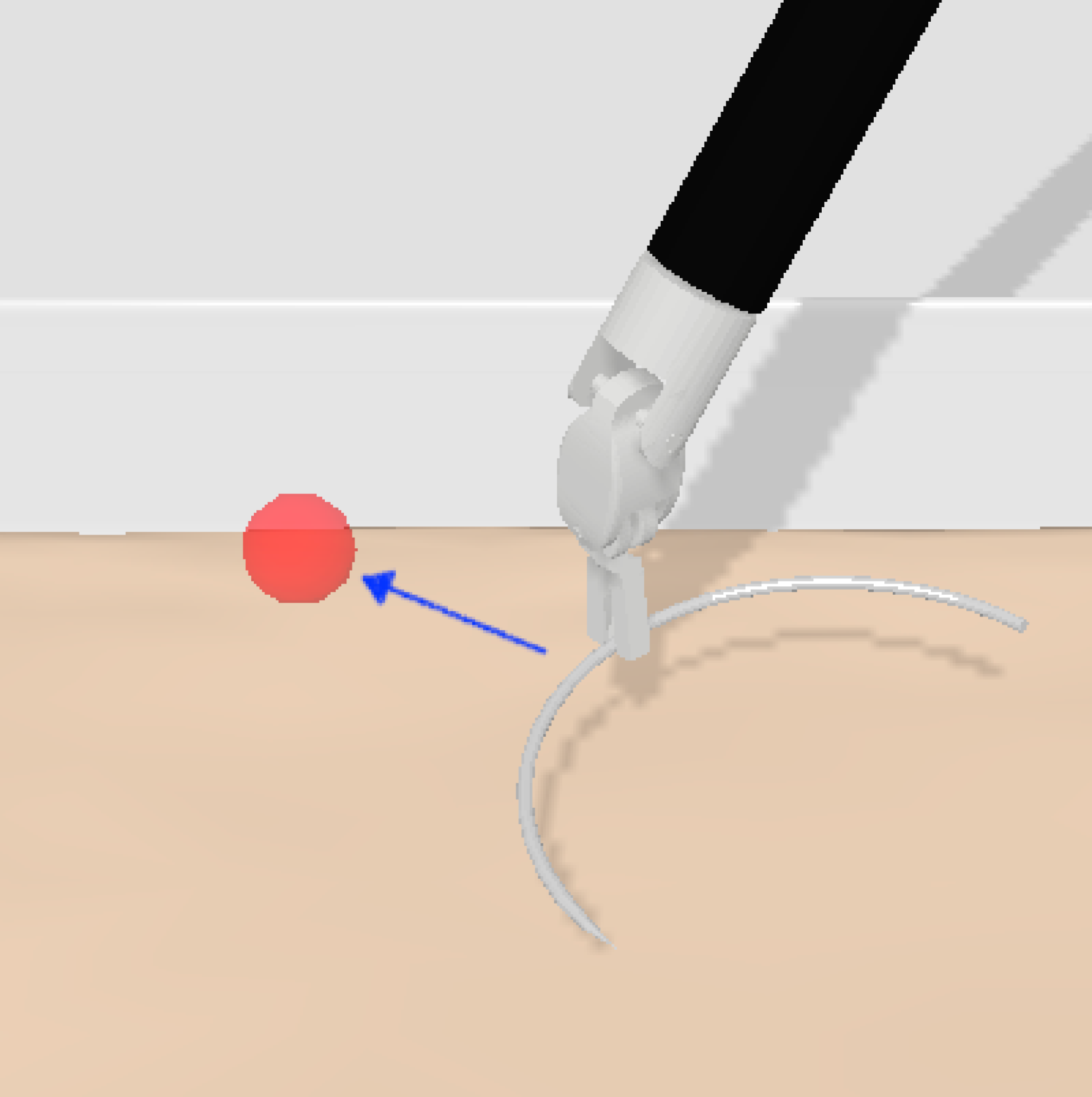
📊 实验亮点
实验结果表明,KIAN-ACE在仿真环境中能够高效地学习自动化十个手术任务,并且在单独学习和增量学习两种模式下均表现良好。此外,通过sim-to-real迁移实验,验证了学习到的策略在真实达芬奇研究套件(dVRK)上的有效性,证明了SurgIRL具有良好的泛化能力。
🎯 应用场景
SurgIRL有望应用于各种手术机器人系统,提高手术自动化水平,降低手术成本,并提高手术的可及性。通过终身学习,手术机器人可以不断积累经验,适应不同的手术场景和患者需求,最终实现更安全、更高效的手术操作。该技术还可用于培训新的外科医生,提供个性化的指导和反馈。
📄 摘要(原文)
Surgical automation holds immense potential to improve the outcome and accessibility of surgery. Recent studies use reinforcement learning to learn policies that automate different surgical tasks. However, these policies are developed independently and are limited in their reusability when the task changes, making it more time-consuming when robots learn to solve multiple tasks. Inspired by how human surgeons build their expertise, we train surgical automation policies through Surgical Incremental Reinforcement Learning (SurgIRL). SurgIRL aims to (1) acquire new skills by referring to external policies (knowledge) and (2) accumulate and reuse these skills to solve multiple unseen tasks incrementally (incremental learning). Our SurgIRL framework includes three major components. We first define an expandable knowledge set containing heterogeneous policies that can be helpful for surgical tasks. Then, we propose Knowledge Inclusive Attention Network with mAximum Coverage Exploration (KIAN-ACE), which improves learning efficiency by maximizing the coverage of the knowledge set during the exploration process. Finally, we develop incremental learning pipelines based on KIAN-ACE to accumulate and reuse learned knowledge and solve multiple surgical tasks sequentially. Our simulation experiments show that KIAN-ACE efficiently learns to automate ten surgical tasks separately or incrementally. We also evaluate our learned policies on the da Vinci Research Kit (dVRK) and demonstrate successful sim-to-real transfers.