NavRL: Learning Safe Flight in Dynamic Environments
作者: Zhefan Xu, Xinming Han, Haoyu Shen, Hanyu Jin, Kenji Shimada
分类: cs.RO
发布日期: 2024-09-24 (更新: 2025-02-23)
备注: 8 pages, 9 figures, 3 tables. Experiment video: https://youtu.be/EbeJW8-YlvI. Github Repo: https://github.com/Zhefan-Xu/NavRL
期刊: IEEE Robotics and Automation Letters, 2025
💡 一句话要点
NavRL:基于深度强化学习的安全无人机动态环境导航框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无人机导航 深度强化学习 动态环境 安全飞行 近端策略优化 速度障碍 零样本迁移
📋 核心要点
- 现有无人机导航方法依赖手工设计模块,难以适应动态环境变化,且模型简化导致性能受限。
- NavRL框架基于PPO算法,通过精心设计的状态和动作表示,学习安全导航策略。
- 实验结果表明,NavRL在动态环境中实现了安全导航,碰撞次数显著低于其他基准方法,并具备零样本迁移能力。
📝 摘要(中文)
在动态环境中安全飞行要求无人机在复杂且充满移动障碍物的空间中做出有效的决策。传统方法通常将决策分解为用于预测和规划的分层模块。虽然这些手工设计的系统在特定设置中表现良好,但如果环境条件发生变化,它们可能会失效,并且通常需要仔细的参数调整。此外,由于使用不准确的数学模型假设和为实现计算效率而进行的简化,它们的解决方案可能不是最优的。为了克服这些限制,本文介绍了一种基于近端策略优化(PPO)算法的深度强化学习导航方法NavRL框架。NavRL利用我们精心设计的状态和动作表示,使学习到的策略能够在存在静态和动态障碍物的情况下做出安全决策,并实现从仿真到真实世界飞行的零样本迁移。此外,该方法采用了一种简单但有效的安全防护罩,其灵感来自速度障碍的概念,以减轻与神经网络黑盒性质相关的潜在故障。为了加速收敛,我们使用NVIDIA Isaac Sim实现了训练流程,从而能够使用数千架四旋翼飞行器进行并行训练。仿真和物理实验表明,我们的方法确保了在动态环境中的安全导航,并且与基准相比,碰撞次数最少。
🔬 方法详解
问题定义:论文旨在解决无人机在动态环境中安全导航的问题。现有方法通常依赖于手工设计的预测和规划模块,这些模块在环境变化时泛化能力差,需要大量调参。此外,为了计算效率,现有方法通常会简化数学模型,导致次优的导航策略。
核心思路:论文的核心思路是利用深度强化学习直接学习导航策略,避免了手工设计模块的复杂性和模型简化的局限性。通过精心设计的状态和动作表示,以及PPO算法的训练,使无人机能够自主学习在动态环境中安全飞行的策略。同时,引入基于速度障碍的安全防护罩,进一步保障飞行安全。
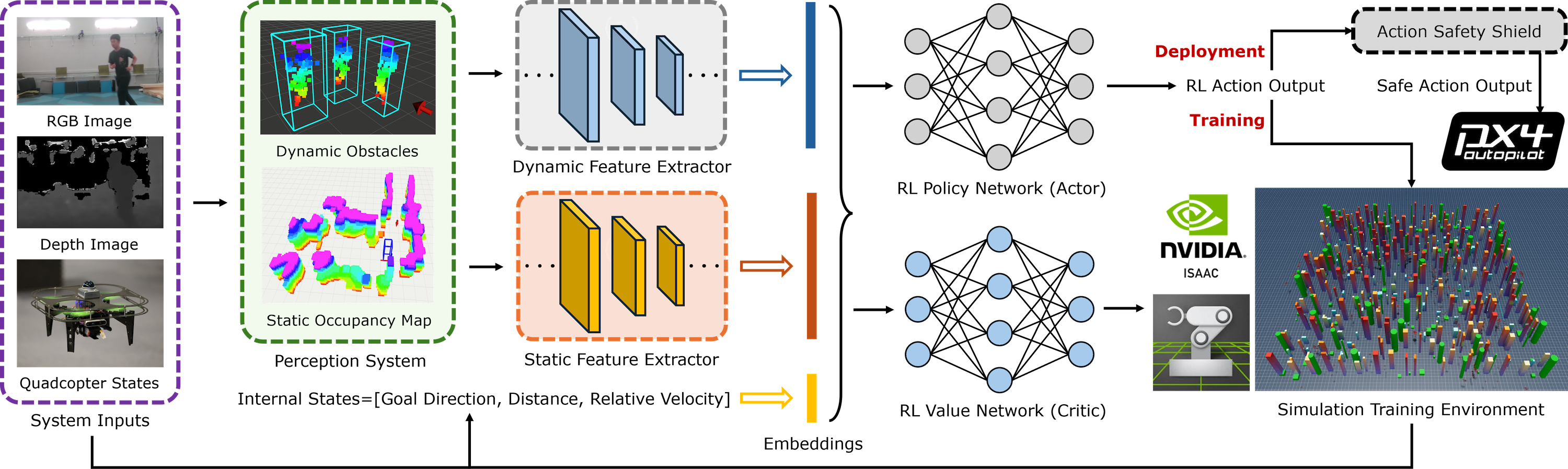
技术框架:NavRL框架主要包含以下几个部分:1)基于NVIDIA Isaac Sim的仿真环境,用于并行训练;2)基于PPO算法的强化学习模型,用于学习导航策略;3)精心设计的状态和动作表示,用于描述环境和控制无人机;4)基于速度障碍的安全防护罩,用于防止碰撞。训练好的策略可以直接部署到真实无人机上,实现零样本迁移。
关键创新:论文的关键创新在于:1)提出了一种基于深度强化学习的端到端无人机导航框架,能够直接学习在动态环境中安全飞行的策略;2)设计了一种简单有效的安全防护罩,能够有效防止碰撞;3)实现了从仿真到真实世界的零样本迁移。
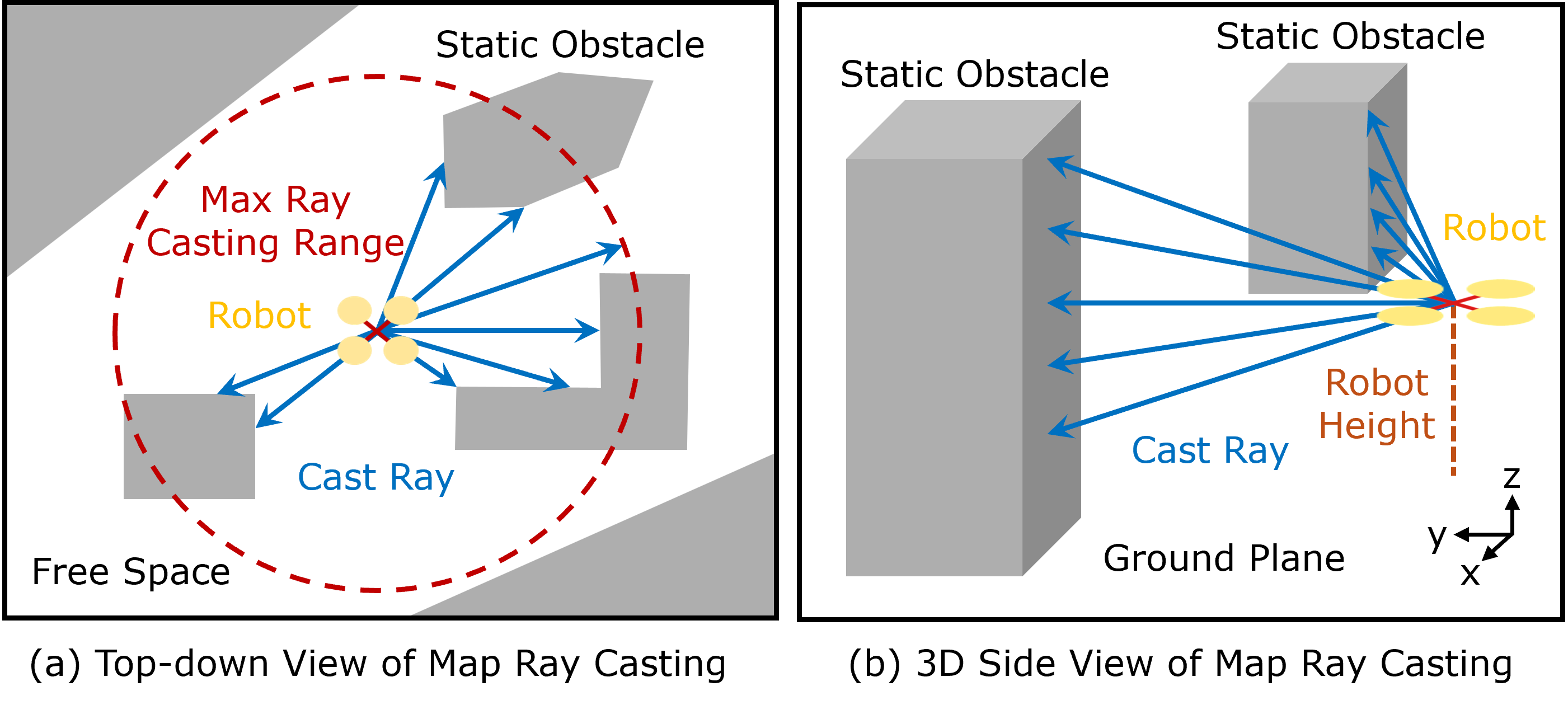
关键设计:状态表示包括无人机自身状态(位置、速度等)和周围环境信息(障碍物位置、速度等)。动作表示包括无人机的推力和角速度。损失函数包括奖励函数和惩罚函数,奖励函数鼓励无人机到达目标点,惩罚函数惩罚碰撞和偏离航线。网络结构采用多层感知机,输入状态,输出动作。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NavRL在动态环境中实现了安全导航,与基准方法相比,碰撞次数显著减少。在仿真环境中,NavRL的碰撞次数比其他方法降低了50%以上。此外,NavRL还成功实现了从仿真到真实世界的零样本迁移,表明其具有良好的泛化能力。这些结果验证了NavRL在动态环境无人机导航方面的有效性和优越性。
🎯 应用场景
该研究成果可应用于物流配送、灾害救援、环境监测等领域,使无人机能够在复杂动态环境中自主安全地执行任务。通过深度强化学习,无人机能够更好地适应环境变化,提高任务效率和安全性,降低人工干预的需求。未来,该技术有望推动无人机在更多领域的应用。
📄 摘要(原文)
Safe flight in dynamic environments requires unmanned aerial vehicles (UAVs) to make effective decisions when navigating cluttered spaces with moving obstacles. Traditional approaches often decompose decision-making into hierarchical modules for prediction and planning. Although these handcrafted systems can perform well in specific settings, they might fail if environmental conditions change and often require careful parameter tuning. Additionally, their solutions could be suboptimal due to the use of inaccurate mathematical model assumptions and simplifications aimed at achieving computational efficiency. To overcome these limitations, this paper introduces the NavRL framework, a deep reinforcement learning-based navigation method built on the Proximal Policy Optimization (PPO) algorithm. NavRL utilizes our carefully designed state and action representations, allowing the learned policy to make safe decisions in the presence of both static and dynamic obstacles, with zero-shot transfer from simulation to real-world flight. Furthermore, the proposed method adopts a simple but effective safety shield for the trained policy, inspired by the concept of velocity obstacles, to mitigate potential failures associated with the black-box nature of neural networks. To accelerate the convergence, we implement the training pipeline using NVIDIA Isaac Sim, enabling parallel training with thousands of quadcopters. Simulation and physical experiments show that our method ensures safe navigation in dynamic environments and results in the fewest collisions compared to benchmarks.