XMoP: Whole-Body Control Policy for Zero-shot Cross-Embodiment Neural Motion Planning
作者: Prabin Kumar Rath, Nakul Gopalan
分类: cs.RO
发布日期: 2024-09-23 (更新: 2025-07-13)
备注: Website at https://prabinrath.github.io/xmop Paper has 17 pages, 13 figures, 5 tables
💡 一句话要点
提出XMoP,实现零样本跨机械臂神经运动规划的全身控制策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting)
关键词: 神经运动规划 跨机械臂 零样本学习 全身控制 机器人运动规划
📋 核心要点
- 现有运动规划器难以扩展到未见过的动态环境,且缺乏跨不同机器人形态的泛化能力。
- XMoP通过学习全身控制策略,隐式地学习满足一系列机器人的运动学约束,实现零样本迁移。
- XMoP在多个商业机械臂上取得了70%的平均成功率,并在真实环境中展现了强大的sim-to-real泛化能力。
📝 摘要(中文)
本文提出了一种跨机械臂运动策略(XMoP),用于学习规划一系列机械臂的运动。XMoP隐式地学习满足一系列机器人的运动学约束,并将规划行为零样本迁移到该分布中未见过的机器人机械臂。通过在一个包含超过三百万个程序化采样的机器人机械臂的模拟环境中进行训练,XMoP学习了一种全身控制策略。尽管完全在合成的机器人和环境中训练,但该策略在具有不同运动学变化和自由度的机械臂上表现出强大的sim-to-real泛化能力,且仅使用一组固定的策略参数。在7个商业机械臂上评估XMoP,并在基准测试中实现了平均70%的成功率,展示了成功的跨机械臂运动规划。此外,还在两个未见过的机械臂上进行了sim-to-real实验,解决了三个真实世界领域中的新规划问题,即使存在动态障碍物。
🔬 方法详解
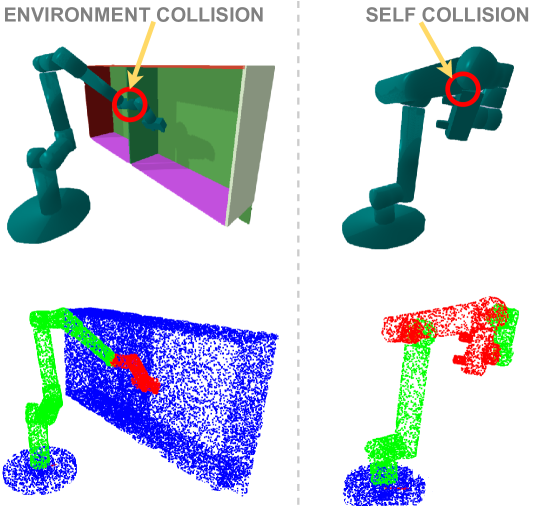
问题定义:现有机械臂运动规划器要么依赖于预先指定的静态环境表示,难以适应动态环境;要么无法在不同的机器人形态之间泛化。神经运动规划器(NMPs)虽然可以在不同环境中规划,但无法跨机器人形态泛化。因此,需要一种能够处理动态环境,并且能够零样本迁移到不同机器人形态的运动规划方法。
核心思路:XMoP的核心思路是学习一个通用的全身控制策略,该策略能够隐式地学习一系列机器人的运动学约束。通过在大量程序化生成的机器人和环境中进行训练,XMoP能够学习到一种对机器人形态不敏感的规划策略,从而实现零样本跨机械臂的运动规划。
技术框架:XMoP的整体框架包括以下几个关键部分:首先,使用程序化生成的方法创建大量的机器人和环境样本。然后,使用这些样本训练一个全身控制策略,该策略以原始传感器观测作为输入,输出机器人的控制指令。最后,将训练好的策略部署到真实的机器人上,进行运动规划。
关键创新:XMoP最重要的创新点在于其能够实现零样本跨机械臂的运动规划。这得益于其全身控制策略的设计,以及在大量程序化生成的机器人和环境中进行训练。与现有的NMPs相比,XMoP不再局限于特定的机器人形态,而是能够泛化到一系列不同的机器人上。
关键设计:XMoP的关键设计包括:1) 使用程序化生成的方法创建多样化的机器人和环境样本,以提高策略的泛化能力;2) 设计一个全身控制策略,该策略能够直接从原始传感器观测中学习;3) 使用大量的训练数据,以确保策略能够学习到对机器人形态不敏感的规划策略。
🖼️ 关键图片


📊 实验亮点
XMoP在7个商业机械臂上进行了评估,平均成功率达到70%,证明了其跨机械臂运动规划的有效性。此外,在两个未见过的机械臂上进行了sim-to-real实验,成功解决了三个真实世界领域中的新规划问题,即使存在动态障碍物,也展现了强大的sim-to-real泛化能力。
🎯 应用场景
XMoP具有广泛的应用前景,例如在柔性制造、自动化装配、以及服务机器人等领域。它可以帮助机器人更好地适应不同的工作环境和任务需求,提高机器人的灵活性和智能化水平。未来,XMoP有望应用于更复杂的机器人系统,例如多机器人协作系统,从而实现更高级的自动化任务。
📄 摘要(原文)
Classical manipulator motion planners work across different robot embodiments. However they plan on a pre-specified static environment representation, and are not scalable to unseen dynamic environments. Neural Motion Planners (NMPs) are an appealing alternative to conventional planners as they incorporate different environmental constraints to learn motion policies directly from raw sensor observations. Contemporary state-of-the-art NMPs can successfully plan across different environments. However none of the existing NMPs generalize across robot embodiments. In this paper we propose Cross-Embodiment Motion Policy (XMoP), a neural policy for learning to plan over a distribution of manipulators. XMoP implicitly learns to satisfy kinematic constraints for a distribution of robots and $\textit{zero-shot}$ transfers the planning behavior to unseen robotic manipulators within this distribution. We achieve this generalization by formulating a whole-body control policy that is trained on planning demonstrations from over three million procedurally sampled robotic manipulators in different simulated environments. Despite being completely trained on synthetic embodiments and environments, our policy exhibits strong sim-to-real generalization across manipulators with different kinematic variations and degrees of freedom with a single set of frozen policy parameters. We evaluate XMoP on $7$ commercial manipulators and show successful cross-embodiment motion planning, achieving an average $70\%$ success rate on baseline benchmarks. Furthermore, we demonstrate our policy sim-to-real on two unseen manipulators solving novel planning problems across three real-world domains even with dynamic obstacles.