RACER: Rich Language-Guided Failure Recovery Policies for Imitation Learning
作者: Yinpei Dai, Jayjun Lee, Nima Fazeli, Joyce Chai
分类: cs.RO, cs.CL, cs.CV
发布日期: 2024-09-23
备注: Project Website: https://rich-language-failure-recovery.github.io
💡 一句话要点
提出RACER,利用富语言指导的模仿学习策略提升机器人操作的容错性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 模仿学习 视觉-语言模型 失败恢复 语言指导
📋 核心要点
- 现有机器人操作策略缺乏从失败中恢复的能力,且简单的语言指令难以有效指导复杂动作。
- RACER框架利用视觉-语言模型作为在线监督者,提供详细的语言指导,结合失败恢复数据提升控制。
- 实验表明,RACER在长时程任务、动态目标变化和零样本任务中均优于RVT,并在真实世界中有效。
📝 摘要(中文)
针对机器人操作中缺乏从失败中自我恢复机制以及简单语言指令在指导机器人行为方面的局限性,本文提出了一种可扩展的数据生成流程,该流程自动增强专家演示数据,包括失败恢复轨迹和细粒度的语言标注,用于训练。进一步,本文提出了富语言指导的失败恢复(RACER)框架,这是一个监督者-执行者框架,它结合失败恢复数据和丰富的语言描述来增强机器人控制。RACER采用视觉-语言模型(VLM)作为在线监督者,为错误纠正和任务执行提供详细的语言指导,并使用语言条件化的视觉运动策略作为执行者来预测下一步动作。实验结果表明,在各种评估设置下,包括标准长时程任务、动态目标变化任务和零样本未见任务,RACER在RLbench上优于最先进的机器人视角转换器(RVT),并在模拟和真实世界环境中都取得了优异的性能。相关视频和代码可在https://rich-language-failure-recovery.github.io 找到。
🔬 方法详解
问题定义:机器人操作任务,尤其是在复杂环境中,容易出现失败。现有的模仿学习方法通常依赖于完美的演示数据,缺乏从失败中恢复的能力。简单的语言指令不足以提供足够的上下文信息来指导机器人进行纠错和适应。
核心思路:RACER的核心思路是利用视觉-语言模型(VLM)作为在线监督者,为机器人提供丰富的语言指导,从而增强其从失败中恢复的能力。通过结合失败恢复数据和细粒度的语言描述,RACER能够学习到更鲁棒和可纠正的策略。
技术框架:RACER是一个监督者-执行者框架。监督者是一个视觉-语言模型(VLM),它接收当前状态的视觉信息和任务相关的语言指令,并输出详细的语言指导。执行者是一个语言条件化的视觉运动策略,它接收当前状态的视觉信息和监督者提供的语言指导,并预测下一步的动作。该框架通过模仿学习进行训练,利用增强的专家演示数据,包括失败恢复轨迹和语言标注。
关键创新:RACER的关键创新在于将视觉-语言模型(VLM)引入到机器人控制中,作为在线监督者,提供细粒度的语言指导。这种方法允许机器人利用丰富的语言信息来理解任务目标、识别错误并采取相应的纠正措施。与传统的模仿学习方法相比,RACER能够更好地处理不确定性和失败情况。
关键设计:数据生成流程自动增强专家演示数据,包括失败恢复轨迹和细粒度的语言标注。视觉-语言模型(VLM)使用预训练的视觉和语言编码器,并通过微调来适应特定的机器人操作任务。语言条件化的视觉运动策略使用Transformer网络结构,接收视觉和语言输入,并预测下一步的动作。损失函数包括模仿学习损失和语言指导损失,用于训练执行者模仿专家行为并遵循监督者的指导。
🖼️ 关键图片

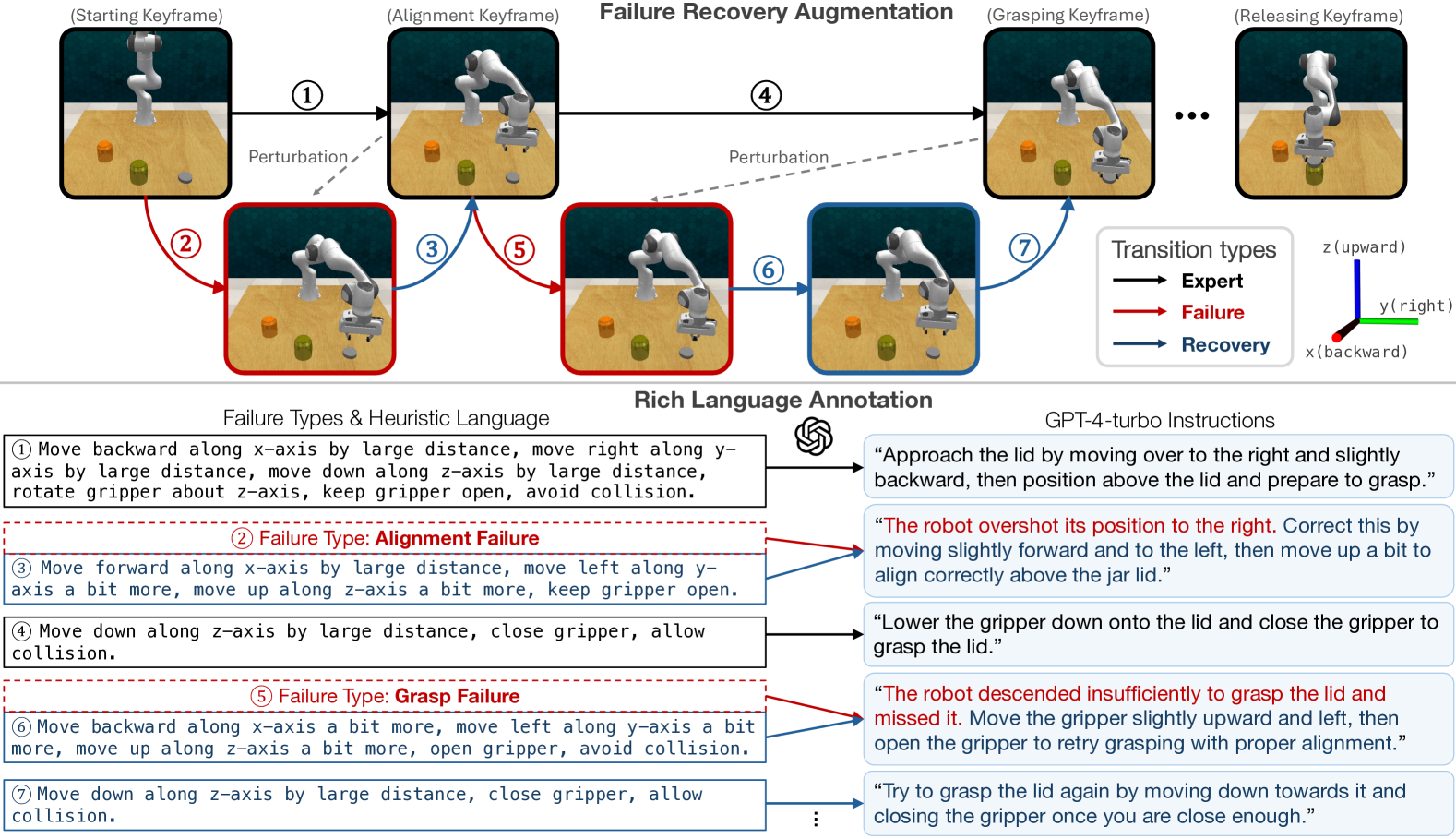
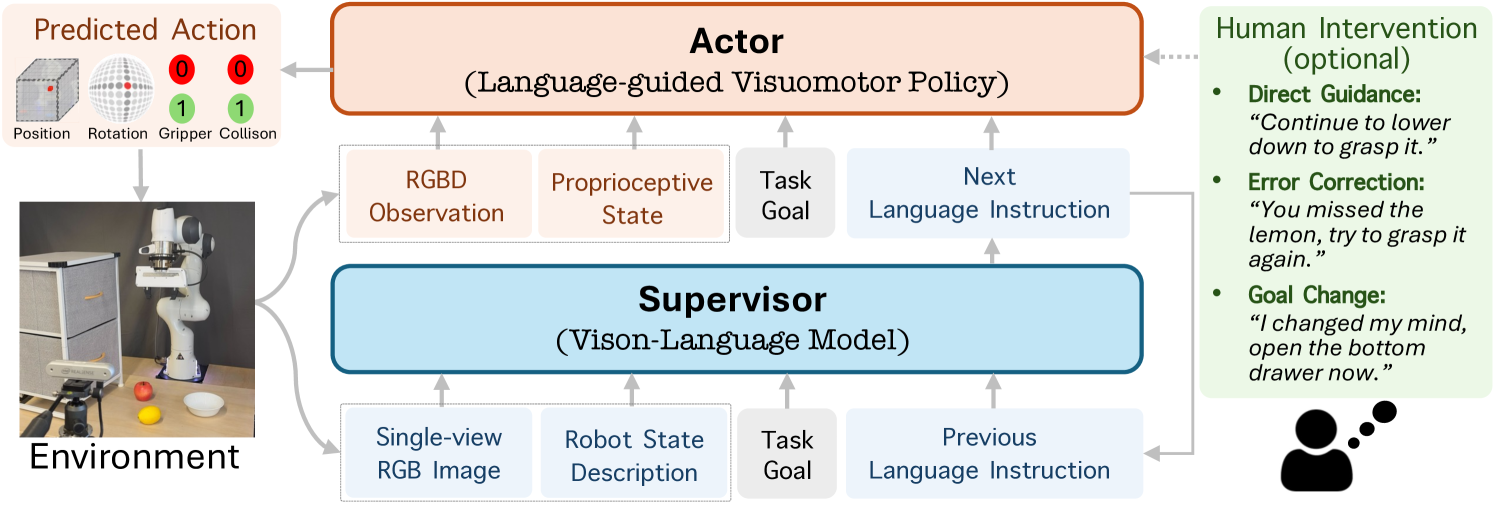
📊 实验亮点
RACER在RLbench基准测试中取得了显著的性能提升,在标准长时程任务、动态目标变化任务和零样本未见任务中均优于最先进的RVT模型。具体而言,在真实世界实验中,RACER也表现出良好的泛化能力,证明了其在实际应用中的潜力。性能提升主要归功于其利用VLM进行在线语言指导的能力。
🎯 应用场景
RACER框架具有广泛的应用前景,可用于提升各种机器人操作任务的鲁棒性和可靠性,例如家庭服务机器人、工业自动化机器人和医疗机器人。通过提供丰富的语言指导,RACER可以使机器人更好地理解任务目标并适应不同的环境和情况,从而实现更安全、更高效的人机协作。
📄 摘要(原文)
Developing robust and correctable visuomotor policies for robotic manipulation is challenging due to the lack of self-recovery mechanisms from failures and the limitations of simple language instructions in guiding robot actions. To address these issues, we propose a scalable data generation pipeline that automatically augments expert demonstrations with failure recovery trajectories and fine-grained language annotations for training. We then introduce Rich languAge-guided failure reCovERy (RACER), a supervisor-actor framework, which combines failure recovery data with rich language descriptions to enhance robot control. RACER features a vision-language model (VLM) that acts as an online supervisor, providing detailed language guidance for error correction and task execution, and a language-conditioned visuomotor policy as an actor to predict the next actions. Our experimental results show that RACER outperforms the state-of-the-art Robotic View Transformer (RVT) on RLbench across various evaluation settings, including standard long-horizon tasks, dynamic goal-change tasks and zero-shot unseen tasks, achieving superior performance in both simulated and real world environments. Videos and code are available at: https://rich-language-failure-recovery.github.io.