Adaptive Compensation for Robotic Joint Failures Using Partially Observable Reinforcement Learning
作者: Tan-Hanh Pham, Godwyll Aikins, Tri Truong, Kim-Doang Nguyen
分类: cs.RO
发布日期: 2024-09-22
备注: 15 pages
💡 一句话要点
提出基于部分可观测强化学习的自适应补偿方法,解决机器人关节失效问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 机器人控制 关节失效 自适应补偿 部分可观测马尔可夫决策过程
📋 核心要点
- 现有机器人易受硬件故障影响,尤其是在关节失效时,传统控制方法难以有效应对。
- 采用强化学习框架,将问题建模为POMDP,使机器人能够在不同关节故障情况下学习自适应补偿策略。
- 实验表明,该方法在关节失效情况下仍能保持较高的任务成功率(93.6%),优于传统逆运动学方法。
📝 摘要(中文)
本研究旨在解决机器人机械臂在关节发生故障时如何继续完成任务的挑战。我们开发了一个强化学习(RL)框架,使其能够自适应地补偿非功能性关节。实验平台为具有7个自由度(DOF)的Franka机器人。我们将问题建模为部分可观测马尔可夫决策过程(POMDP),在各种关节故障条件下训练机器人,并在已见和未见场景中进行测试。考虑了关节永久性损坏和间歇性工作的情况。通过与传统的基于逆运动学的控制方法进行比较,证明了该方法的有效性。结果表明,即使在关节发生故障的情况下,RL算法也能使机器人成功完成任务,平均成功率高达93.6%,展示了其鲁棒性和适应性。研究结果突显了RL在增强机器人系统的弹性和可靠性方面的潜力,使其更适合不可预测的环境。所有相关代码和模型均已在线发布。
🔬 方法详解
问题定义:论文旨在解决机器人关节失效时,如何保证机器人仍然能够完成既定任务的问题。现有方法,如基于逆运动学的控制方法,在关节完全失效或间歇性失效的情况下,难以有效规划运动轨迹,导致任务失败。因此,需要一种能够自适应地补偿关节失效的控制策略。
核心思路:论文的核心思路是利用强化学习,让机器人通过与环境的交互,学习在关节失效的情况下如何调整其他关节的运动,从而补偿失效关节的功能,最终完成任务。这种方法不需要预先精确建模关节失效的情况,而是通过试错学习,获得一种鲁棒的控制策略。
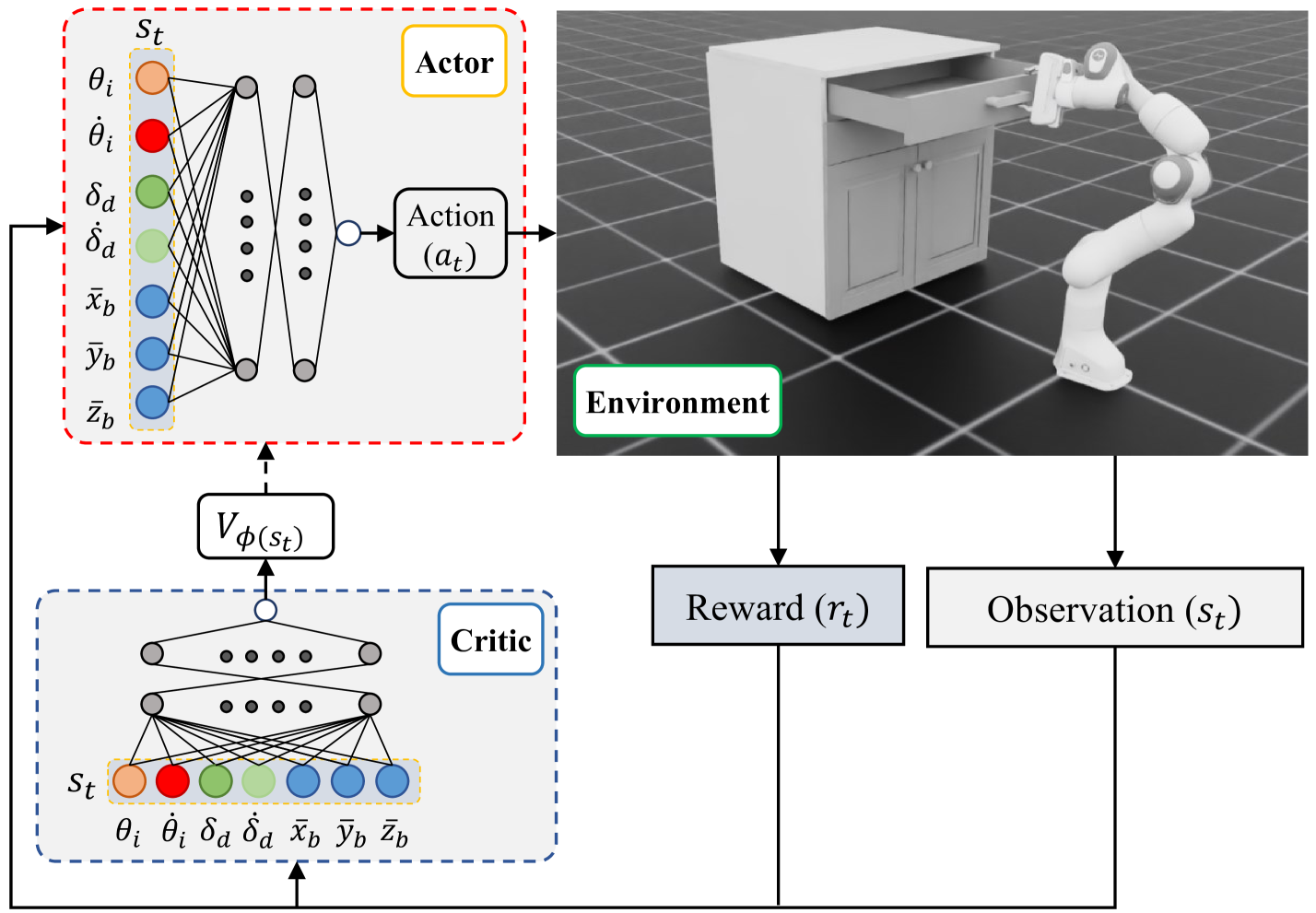
技术框架:整体框架是一个基于部分可观测马尔可夫决策过程(POMDP)的强化学习系统。主要包含以下几个模块:1) 环境模型:模拟Franka机器人的运动学和动力学,以及各种关节失效的情况。2) 状态表示:由于关节失效状态可能无法直接观测,因此需要设计合适的状态表示,例如使用关节角度、速度和力矩等信息。3) 策略网络:使用深度神经网络学习从状态到动作的映射,即控制策略。4) 奖励函数:设计合适的奖励函数,鼓励机器人完成任务,并惩罚不期望的行为,例如碰撞。5) 强化学习算法:使用合适的强化学习算法,例如PPO或SAC,训练策略网络。
关键创新:该论文的关键创新在于将强化学习应用于机器人关节失效的自适应补偿问题,并将其建模为POMDP。这种建模方式能够处理关节失效状态的不确定性,使机器人能够在部分观测的情况下学习有效的控制策略。此外,该方法不需要预先精确建模关节失效的情况,具有较强的鲁棒性和适应性。
关键设计:论文中一些关键的设计包括:1) 状态表示:选择合适的关节角度、速度和力矩信息作为状态表示,以便能够较好地反映机器人的状态和关节失效的情况。2) 奖励函数:设计稀疏奖励,只有当机器人成功完成任务时才给予奖励,以鼓励机器人学习高效的策略。3) 策略网络结构:使用多层感知机或循环神经网络作为策略网络,以便能够学习复杂的非线性控制策略。4) 强化学习算法:采用PPO算法进行训练,并调整相关超参数,以获得较好的训练效果。
🖼️ 关键图片
📊 实验亮点
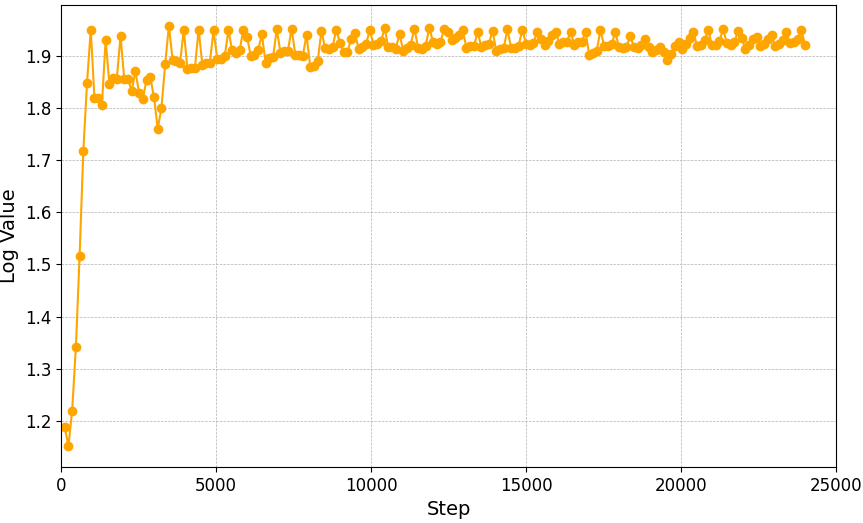
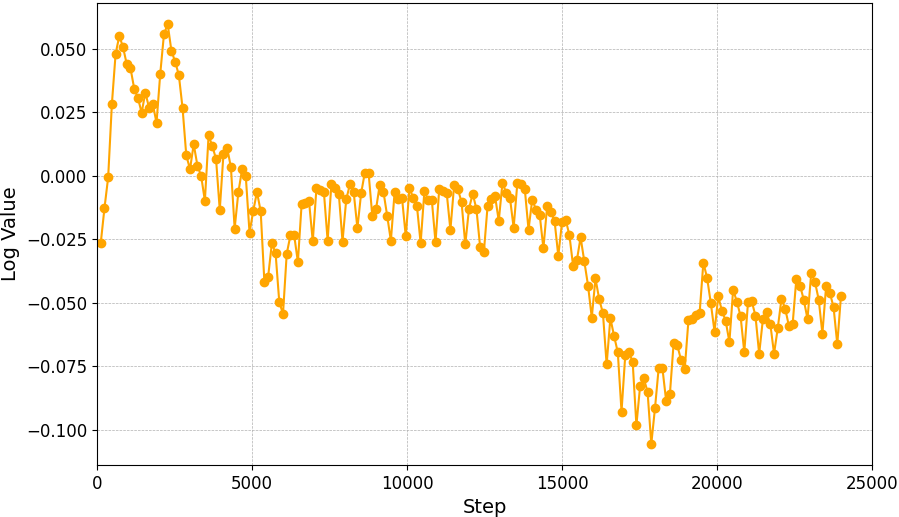
实验结果表明,该方法在多种关节失效情况下均能取得较高的任务成功率,平均成功率达到93.6%。与传统的基于逆运动学的控制方法相比,该方法在关节失效情况下的性能显著提升。此外,该方法还能够在未见过的关节失效场景中泛化,表明其具有较强的鲁棒性和适应性。
🎯 应用场景
该研究成果可应用于各种工业机器人和自动化系统中,提高机器人在恶劣或不可预测环境下的可靠性和鲁棒性。例如,在太空探索、深海作业或核电站维护等场景中,机器人可能面临硬件故障的风险,该方法可以帮助机器人继续执行任务,减少损失。此外,该方法还可以用于康复机器人和外骨骼等领域,帮助残疾人或老年人完成日常活动。
📄 摘要(原文)
Robotic manipulators are widely used in various industries for complex and repetitive tasks. However, they remain vulnerable to unexpected hardware failures. In this study, we address the challenge of enabling a robotic manipulator to complete tasks despite joint malfunctions. Specifically, we develop a reinforcement learning (RL) framework to adaptively compensate for a non-functional joint during task execution. Our experimental platform is the Franka robot with 7 degrees of freedom (DOFs). We formulate the problem as a partially observable Markov decision process (POMDP), where the robot is trained under various joint failure conditions and tested in both seen and unseen scenarios. We consider scenarios where a joint is permanently broken and where it functions intermittently. Additionally, we demonstrate the effectiveness of our approach by comparing it with traditional inverse kinematics-based control methods. The results show that the RL algorithm enables the robot to successfully complete tasks even with joint failures, achieving a high success rate with an average rate of 93.6%. This showcases its robustness and adaptability. Our findings highlight the potential of RL to enhance the resilience and reliability of robotic systems, making them better suited for unpredictable environments. All related codes and models are published online.