Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation
作者: Minjie Zhu, Yichen Zhu, Jinming Li, Junjie Wen, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, Jian Tang
分类: cs.RO
发布日期: 2024-09-22 (更新: 2024-11-14)
💡 一句话要点
提出ScaleDP:通过可扩展的Diffusion Transformer策略提升机器人操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Diffusion Policy 机器人操作 Transformer 视觉运动学习 模型扩展 非因果注意力 特征嵌入分解
📋 核心要点
- 现有Diffusion Policy在Transformer架构下难以有效扩展,增加模型层数反而可能导致训练效果下降。
- ScaleDP通过分解特征嵌入和引入非因果注意力,改善训练动态,使网络更好地处理多模态动作分布。
- 实验表明,ScaleDP成功将模型扩展到10亿参数,并在MetaWorld和真实机器人任务中显著提升了性能。
📝 摘要(中文)
Diffusion Policy是一种强大的端到端视觉运动机器人控制学习技术。人们期望Diffusion Policy具有深度神经网络的关键属性——可扩展性,即增大模型尺寸能够提升性能。然而,我们的观察表明,Transformer架构中的Diffusion Policy (DP)难以有效扩展;即使少量增加层数也会恶化训练结果。为了解决这个问题,我们提出了用于视觉运动学习的可扩展Diffusion Transformer策略(ScaleDP)。我们提出的方法引入了两个模块,改善了Diffusion Policy的训练动态,并使网络能够更好地处理多模态动作分布。首先,我们发现DP存在梯度过大的问题,导致Diffusion Policy的优化不稳定。为了解决这个问题,我们将观察的特征嵌入分解为多个仿射层,并将其集成到Transformer块中。此外,我们利用非因果注意力,允许策略网络在预测期间“看到”未来的动作,从而有助于减少累积误差。我们证明了我们提出的方法成功地将Diffusion Policy从1000万个参数扩展到10亿个参数。这个名为ScaleDP的新模型可以有效地扩展模型尺寸,同时提高性能和泛化能力。我们在MetaWorld的50个不同任务上对ScaleDP进行了基准测试,发现我们最大的ScaleDP的性能比DP平均提高了21.6%。在7个真实世界的机器人任务中,我们的ScaleDP在四个单臂任务上的性能比DP-T平均提高了36.25%,在三个双臂任务上的性能提高了75%。我们相信我们的工作为扩大视觉运动学习的模型规模铺平了道路。
🔬 方法详解
问题定义:论文旨在解决Diffusion Policy在Transformer架构下难以有效扩展的问题。现有方法在模型增大时,训练不稳定,性能提升不明显,甚至出现性能下降,限制了Diffusion Policy在复杂机器人任务中的应用潜力。
核心思路:论文的核心思路是通过改进Diffusion Policy的训练动态,使其能够更好地处理多模态动作分布,从而实现模型的可扩展性。具体来说,通过分解特征嵌入来解决梯度过大的问题,并利用非因果注意力来减少累积误差。
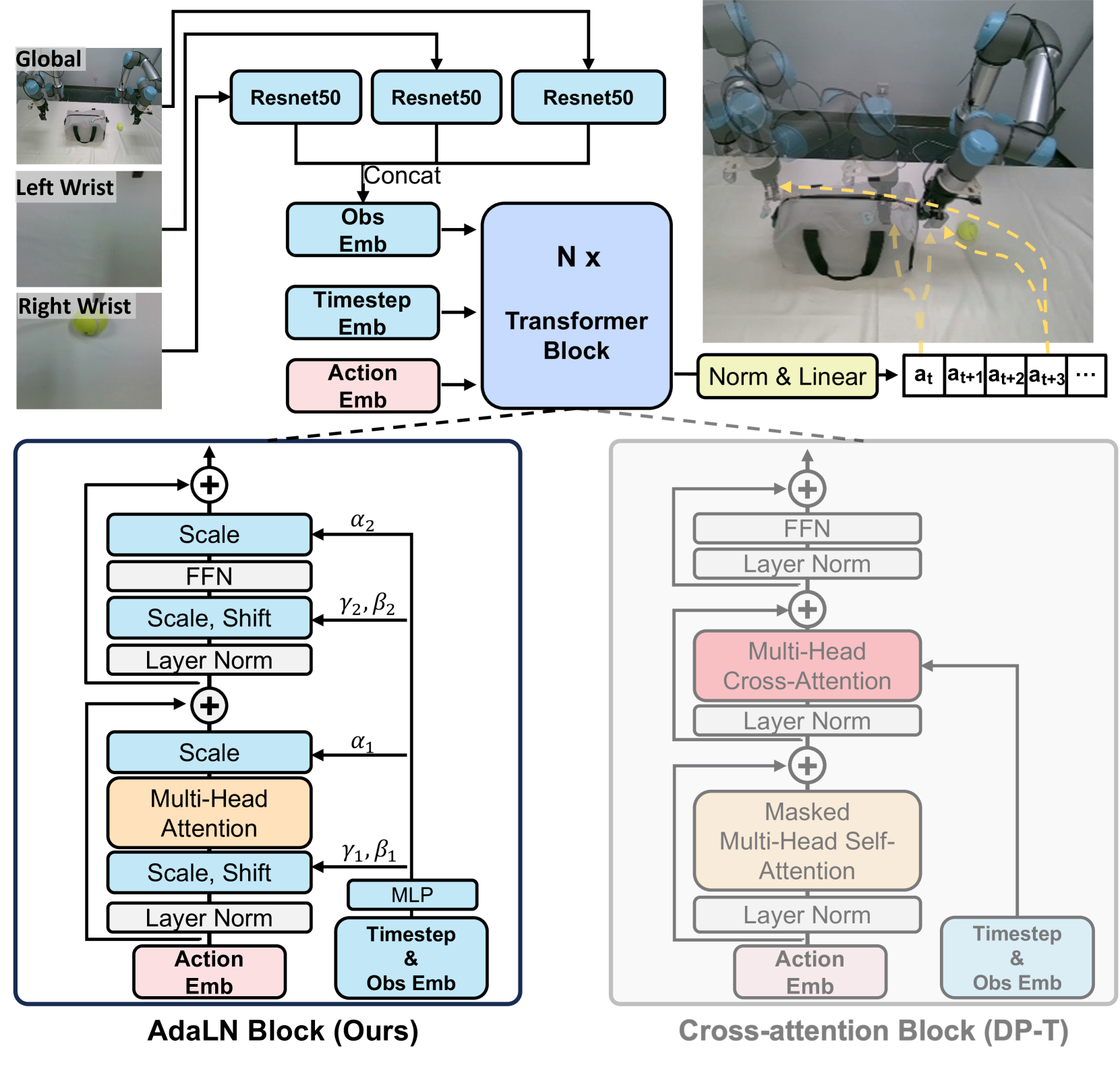
技术框架:ScaleDP的整体框架仍然基于Diffusion Policy,但对其Transformer架构进行了改进。主要包含以下模块:1) 特征嵌入分解模块:将观察的特征嵌入分解为多个仿射层。2) Transformer块:集成了分解后的特征嵌入。3) 非因果注意力模块:允许策略网络在预测期间访问未来的动作信息。训练过程仍然是标准的Diffusion Policy训练流程,包括前向扩散过程和反向去噪过程。
关键创新:论文的关键创新在于两个方面:1) 特征嵌入分解:通过将特征嵌入分解为多个仿射层,有效地缓解了梯度过大的问题,提高了训练的稳定性。2) 非因果注意力:通过允许策略网络“看到”未来的动作,减少了累积误差,提高了预测的准确性。与现有方法相比,ScaleDP能够更有效地利用更大的模型容量,从而实现更好的性能。
关键设计:特征嵌入分解模块的具体实现是将原始的特征嵌入通过多个线性层进行变换,每个线性层后面跟随一个激活函数。非因果注意力的实现方式是在注意力计算过程中,允许每个时间步的query访问所有时间步的key和value。损失函数仍然采用标准的Diffusion Policy损失函数,即预测噪声与真实噪声之间的均方误差。
🖼️ 关键图片
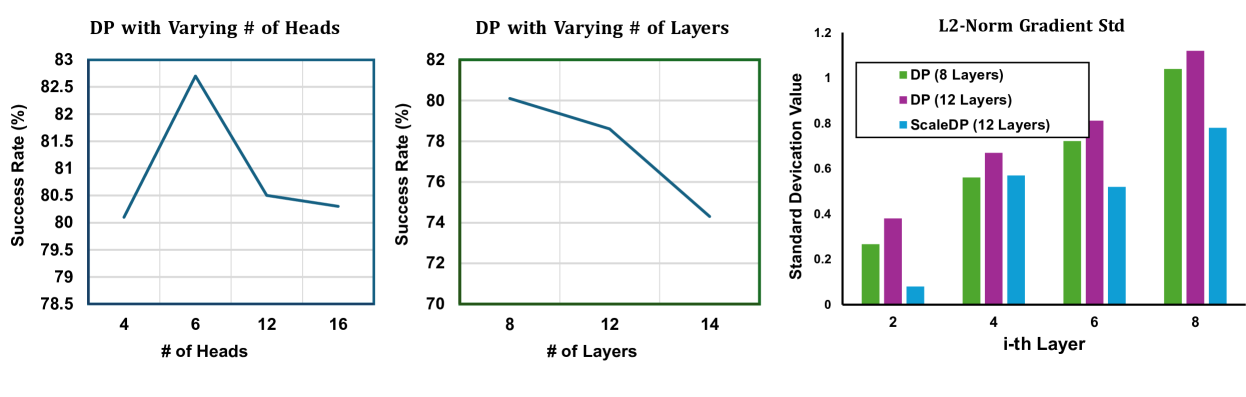
📊 实验亮点
ScaleDP在MetaWorld的50个任务上,相比DP取得了平均21.6%的性能提升。在7个真实机器人任务中,ScaleDP在单臂任务上相比DP-T提升了36.25%,在双臂任务上提升了75%。这些结果表明,ScaleDP能够有效地扩展模型规模,并显著提高机器人的操作性能。
🎯 应用场景
该研究成果可广泛应用于机器人操作领域,尤其是在需要复杂视觉感知和精确动作控制的任务中,例如工业自动化、家庭服务机器人、医疗机器人等。通过扩展模型规模,可以提升机器人在复杂环境中的适应性和泛化能力,使其能够更好地完成各种任务。未来,该方法有望进一步推广到其他机器人学习任务中,例如导航、抓取等。
📄 摘要(原文)
Diffusion Policy is a powerful technique tool for learning end-to-end visuomotor robot control. It is expected that Diffusion Policy possesses scalability, a key attribute for deep neural networks, typically suggesting that increasing model size would lead to enhanced performance. However, our observations indicate that Diffusion Policy in transformer architecture (\DP) struggles to scale effectively; even minor additions of layers can deteriorate training outcomes. To address this issue, we introduce Scalable Diffusion Transformer Policy for visuomotor learning. Our proposed method, namely \textbf{\methodname}, introduces two modules that improve the training dynamic of Diffusion Policy and allow the network to better handle multimodal action distribution. First, we identify that \DP~suffers from large gradient issues, making the optimization of Diffusion Policy unstable. To resolve this issue, we factorize the feature embedding of observation into multiple affine layers, and integrate it into the transformer blocks. Additionally, our utilize non-causal attention which allows the policy network to \enquote{see} future actions during prediction, helping to reduce compounding errors. We demonstrate that our proposed method successfully scales the Diffusion Policy from 10 million to 1 billion parameters. This new model, named \methodname, can effectively scale up the model size with improved performance and generalization. We benchmark \methodname~across 50 different tasks from MetaWorld and find that our largest \methodname~outperforms \DP~with an average improvement of 21.6\%. Across 7 real-world robot tasks, our ScaleDP demonstrates an average improvement of 36.25\% over DP-T on four single-arm tasks and 75\% on three bimanual tasks. We believe our work paves the way for scaling up models for visuomotor learning. The project page is available at scaling-diffusion-policy.github.io.