VLM-Vac: Enhancing Smart Vacuums through VLM Knowledge Distillation and Language-Guided Experience Replay
作者: Reihaneh Mirjalili, Michael Krawez, Florian Walter, Wolfram Burgard
分类: cs.RO
发布日期: 2024-09-21
💡 一句话要点
VLM-Vac:通过VLM知识蒸馏和语言引导经验回放增强智能吸尘器自主性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 智能吸尘器 视觉-语言模型 知识蒸馏 经验回放 持续学习 机器人自主导航 物体检测
📋 核心要点
- 现有智能吸尘器在复杂动态环境中识别和处理物体能力有限,频繁使用VLM计算成本高昂。
- VLM-Vac利用知识蒸馏将VLM知识迁移到小型模型,并结合语言引导经验回放提升持续学习能力。
- 实验表明,该方法能有效降低计算成本,并在小物体检测方面优于传统视觉聚类方法。
📝 摘要(中文)
本文提出了一种名为VLM-Vac的新框架,旨在增强智能扫地机器人的自主性。我们的方法将视觉-语言模型(VLM)的零样本物体检测能力与知识蒸馏(KD)策略相结合。通过利用VLM,机器人可以将物体分类为可操作的类别——避开或吸入,适用于各种背景。然而,频繁查询VLM在计算上是昂贵的,并且不适用于实际部署。为了解决这个问题,我们实施了一个KD过程,逐步将VLM的关键知识转移到一个更小、更高效的模型。我们的真实实验表明,这个较小的模型逐渐从VLM学习,并且随着时间的推移需要显著减少查询次数。此外,我们通过利用一种基于语言引导采样的新型经验回放方法,解决了动态家庭环境中持续学习的挑战。我们的结果表明,这种方法不仅节能,而且超越了传统的基于视觉的聚类方法,尤其是在检测各种背景下的小物体方面。
🔬 方法详解
问题定义:智能吸尘器需要在动态变化的家庭环境中自主识别物体并做出相应决策(避开或吸入)。现有方法,如基于视觉的聚类,在处理小物体和复杂背景时表现不佳。频繁查询大型VLM虽然精度高,但计算成本过高,不适合实时部署。
核心思路:利用VLM的强大零样本物体检测能力作为教师信号,通过知识蒸馏训练一个更小、更高效的模型,使其能够在本地快速进行物体识别。同时,采用语言引导的经验回放策略,使模型能够持续学习并适应新的环境变化。
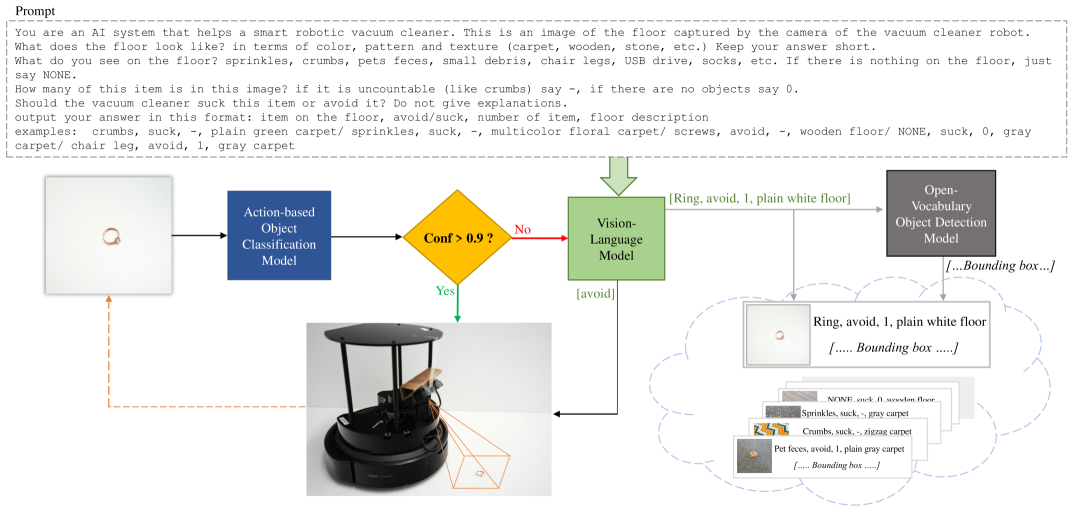
技术框架:VLM-Vac框架包含以下主要模块:1) VLM物体检测模块:使用VLM对环境进行初步感知,生成物体类别标签。2) 知识蒸馏模块:将VLM的输出作为教师信号,训练一个小型视觉模型(学生模型)。3) 语言引导经验回放模块:利用语言描述对历史经验进行采样,用于持续学习和模型更新。整体流程是,首先使用VLM进行环境感知,然后利用知识蒸馏训练小型模型,最后通过语言引导经验回放进行持续学习。
关键创新:1) 结合VLM和知识蒸馏,在保证精度的前提下显著降低计算成本。2) 提出了一种基于语言引导的经验回放方法,能够更有效地选择有价值的经验进行学习,从而提高持续学习的效率和效果。3) 将VLM应用于智能吸尘器领域,探索了VLM在机器人自主导航和环境感知方面的潜力。
关键设计:知识蒸馏过程中,使用了交叉熵损失函数来衡量学生模型和教师模型之间的差异。语言引导经验回放中,使用了CLIP模型将图像和语言描述映射到同一语义空间,并根据相似度进行经验采样。具体网络结构和参数设置未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,VLM-Vac框架能够有效降低计算成本,并在小物体检测方面优于传统的基于视觉的聚类方法。具体性能数据和对比基线未在摘要中给出,属于未知信息。但摘要强调了该方法在节能和检测小物体方面的优势。
🎯 应用场景
该研究成果可应用于智能家居、服务机器人等领域,提升机器人在复杂环境中的自主导航和物体识别能力。通过降低计算成本和提高持续学习能力,使得机器人能够更好地适应动态变化的环境,提供更智能、更高效的服务。未来,该技术还可扩展到其他需要实时环境感知的机器人应用中,例如自动驾驶、安防巡逻等。
📄 摘要(原文)
In this paper, we propose VLM-Vac, a novel framework designed to enhance the autonomy of smart robot vacuum cleaners. Our approach integrates the zero-shot object detection capabilities of a Vision-Language Model (VLM) with a Knowledge Distillation (KD) strategy. By leveraging the VLM, the robot can categorize objects into actionable classes -- either to avoid or to suck -- across diverse backgrounds. However, frequently querying the VLM is computationally expensive and impractical for real-world deployment. To address this issue, we implement a KD process that gradually transfers the essential knowledge of the VLM to a smaller, more efficient model. Our real-world experiments demonstrate that this smaller model progressively learns from the VLM and requires significantly fewer queries over time. Additionally, we tackle the challenge of continual learning in dynamic home environments by exploiting a novel experience replay method based on language-guided sampling. Our results show that this approach is not only energy-efficient but also surpasses conventional vision-based clustering methods, particularly in detecting small objects across diverse backgrounds.