HiFi-CS: Towards Open Vocabulary Visual Grounding For Robotic Grasping Using Vision-Language Models
作者: Vineet Bhat, Prashanth Krishnamurthy, Ramesh Karri, Farshad Khorrami
分类: cs.RO, cs.AI
发布日期: 2024-09-16 (更新: 2025-03-12)
🔗 代码/项目: GITHUB
💡 一句话要点
HiFi-CS:面向机器人抓取的开放词汇视觉定位方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 机器人抓取 视觉-语言模型 特征融合 开放词汇
📋 核心要点
- 现有视觉定位方法在复杂、杂乱的环境中,尤其是在存在同一物体的多个实例时,缺乏有效的比较和泛化能力。
- HiFi-CS的核心思想是分层应用Featurewise Linear Modulation (FiLM) 来融合图像和文本特征,从而提升模型对复杂文本查询的理解和定位能力。
- 实验结果表明,HiFi-CS在封闭词汇场景下优于现有方法,且模型尺寸更小,同时能有效指导开放集目标检测器,提升开放词汇场景下的性能。
📝 摘要(中文)
本文提出HiFi-CS,旨在解决机器人抓取中,通过自然语言进行开放词汇视觉定位的问题。该方法通过分层应用Featurewise Linear Modulation (FiLM) 来融合图像和文本嵌入,从而增强复杂属性文本查询下的视觉定位能力。HiFi-CS包含一个轻量级解码器,并结合冻结的视觉-语言模型(VLM)。在封闭词汇设置下,HiFi-CS的性能优于其他基线方法,且模型尺寸缩小了100倍。该模型能够有效地指导开放集目标检测器(如GroundedSAM),从而提升开放词汇的性能。通过在真实世界的7自由度机器人手臂上进行抓取实验,验证了该方法的有效性,在15个桌面场景中实现了90.33%的视觉定位准确率。
🔬 方法详解
问题定义:论文旨在解决机器人抓取任务中,如何根据自然语言描述,在复杂场景中准确地定位目标物体的问题。现有方法在处理复杂场景,特别是存在多个相同物体实例时,定位精度较低,且对开放词汇的支持不足。
核心思路:论文的核心思路是利用视觉-语言模型(VLM)强大的语义理解能力,并通过分层特征融合的方式,将图像和文本信息有效结合,从而提升视觉定位的准确性和鲁棒性。通过FiLM操作,模型能够根据文本描述动态地调整图像特征,从而更好地关注目标物体。
技术框架:HiFi-CS的整体框架包含以下几个主要模块:1) 视觉-语言模型(VLM):用于提取图像和文本的特征嵌入。2) 分层FiLM融合模块:将图像和文本特征进行分层融合,增强特征表达能力。3) 轻量级解码器:用于将融合后的特征映射到2D/3D空间,从而实现目标物体的定位。4) 开放集目标检测器(GroundedSAM):用于在开放词汇场景下检测目标物体。
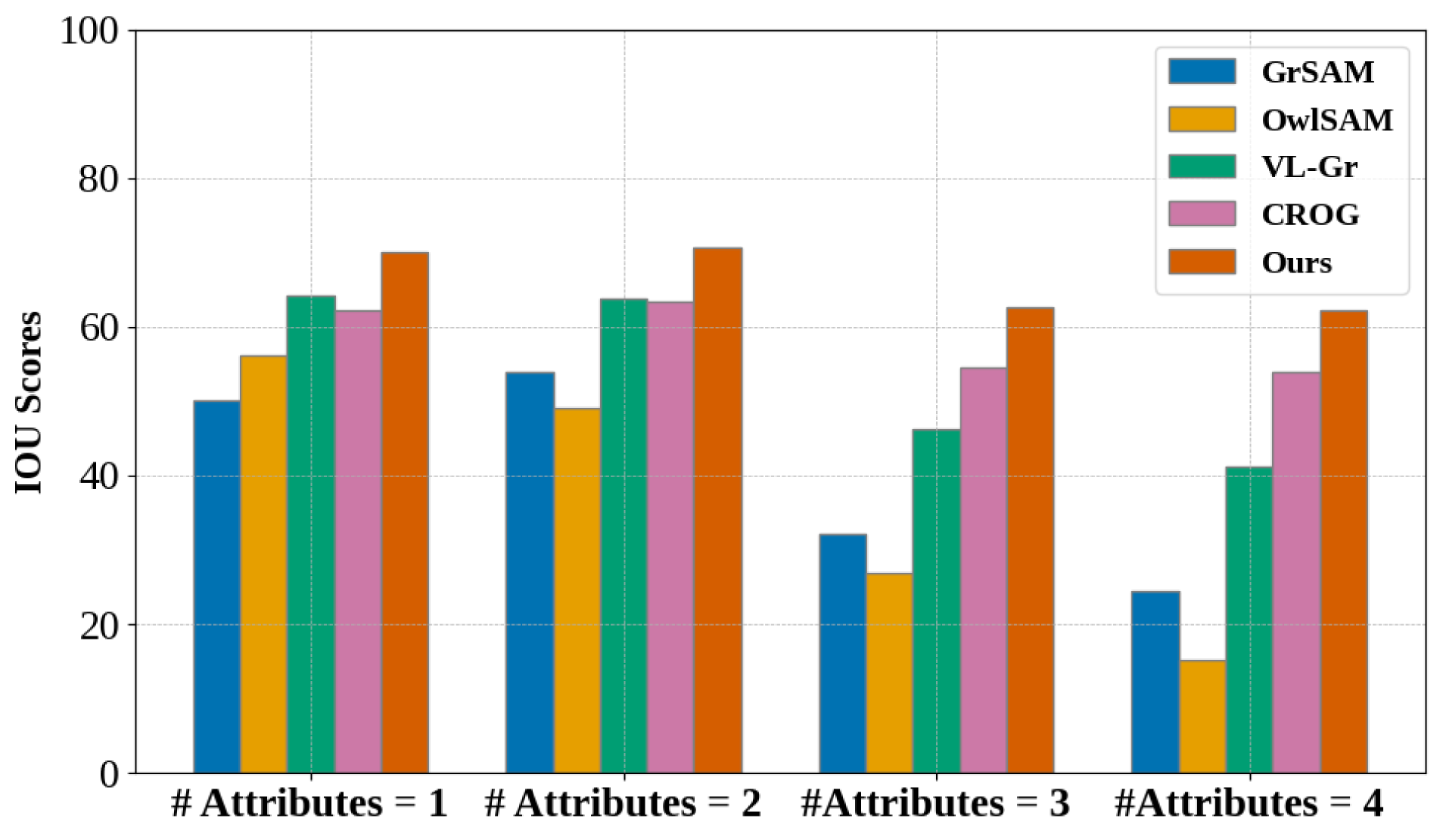
关键创新:HiFi-CS的关键创新在于分层FiLM融合模块的设计。通过在不同层级上进行特征融合,模型能够更好地捕捉图像和文本之间的细粒度关联,从而提升视觉定位的准确性。此外,轻量级解码器的设计使得模型在保持高性能的同时,减小了模型尺寸。
关键设计:HiFi-CS的关键设计包括:1) 分层FiLM融合模块的具体结构和参数设置。2) 轻量级解码器的网络结构和损失函数。3) 如何利用VLM提取的特征来指导开放集目标检测器。4) 实验中使用的具体数据集和评估指标。
🖼️ 关键图片


📊 实验亮点
HiFi-CS在真实机器人抓取实验中取得了显著成果,在15个桌面场景中实现了90.33%的视觉定位准确率。此外,该模型在封闭词汇设置下,性能优于其他基线方法,且模型尺寸缩小了100倍。HiFi-CS还能够有效地指导开放集目标检测器(如GroundedSAM),从而提升开放词汇的性能。
🎯 应用场景
HiFi-CS技术可广泛应用于机器人抓取、人机交互、智能制造等领域。例如,在智能仓储中,机器人可以根据自然语言指令准确抓取指定货物;在家庭服务机器人中,可以根据用户指令完成物品整理等任务。该研究有助于提升机器人的智能化水平,实现更自然、高效的人机协作。
📄 摘要(原文)
Robots interacting with humans through natural language can unlock numerous applications such as Referring Grasp Synthesis (RGS). Given a text query, RGS determines a stable grasp pose to manipulate the referred object in the robot's workspace. RGS comprises two steps: visual grounding and grasp pose estimation. Recent studies leverage powerful Vision-Language Models (VLMs) for visually grounding free-flowing natural language in real-world robotic execution. However, comparisons in complex, cluttered environments with multiple instances of the same object are lacking. This paper introduces HiFi-CS, featuring hierarchical application of Featurewise Linear Modulation (FiLM) to fuse image and text embeddings, enhancing visual grounding for complex attribute rich text queries encountered in robotic grasping. Visual grounding associates an object in 2D/3D space with natural language input and is studied in two scenarios: Closed and Open Vocabulary. HiFi-CS features a lightweight decoder combined with a frozen VLM and outperforms competitive baselines in closed vocabulary settings while being 100x smaller in size. Our model can effectively guide open-set object detectors like GroundedSAM to enhance open-vocabulary performance. We validate our approach through real-world RGS experiments using a 7-DOF robotic arm, achieving 90.33\% visual grounding accuracy in 15 tabletop scenes. Our codebase is provided here: https://github.com/vineet2104/hifics