3D-TAFS: A Training-free Framework for 3D Affordance Segmentation
作者: Meng Chu, Xuan Zhang, Zhedong Zheng, Tat-Seng Chua
分类: cs.RO
发布日期: 2024-09-16 (更新: 2025-04-05)
💡 一句话要点
提出3D-TAFS免训练框架,用于3D可供性分割,提升人机交互。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D可供性分割 免训练学习 多模态融合 人机交互 机器人 3D视觉 语言理解
📋 核心要点
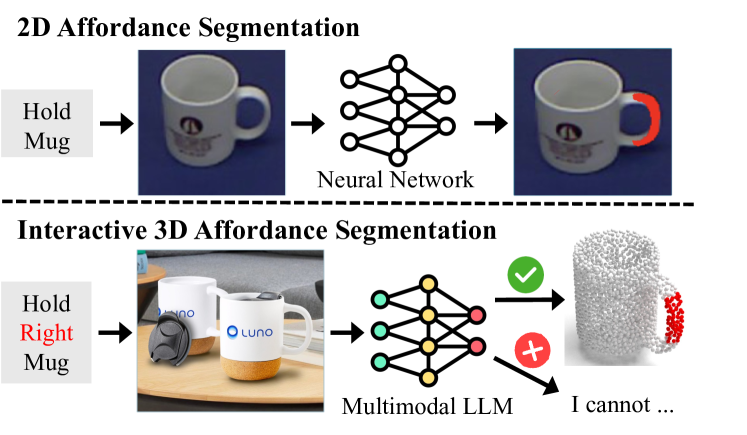
- 现有方法难以将高级语言指令转化为精确的机器人动作,尤其是在考虑与3D对象交互的可行性时。
- 3D-TAFS框架融合了大型多模态模型和3D视觉网络,实现2D/3D视觉与语言的无缝理解。
- 在IndoorAfford-Bench基准测试中,3D-TAFS在各种指标上表现出竞争性的性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种新颖的免训练多模态框架3D-TAFS,用于3D可供性分割。为了全面评估此类框架,我们构建了一个大规模基准测试集IndoorAfford-Bench,包含9248张图像,涵盖6个区域的20个不同的室内场景,支持标准化交互查询。我们的框架集成了大型多模态模型和专门的3D视觉网络,实现了2D和3D视觉理解与语言理解的无缝融合。在IndoorAfford-Bench上的大量实验验证了所提出的3D-TAFS在处理各种设置下的交互式3D可供性分割任务方面的能力,并在各种指标上表现出竞争性的性能。我们的结果突出了3D-TAFS在增强基于复杂室内环境中可供性理解的人机交互方面的潜力,从而推动了用于实际应用的更直观和高效的机器人框架的开发。
🔬 方法详解
问题定义:论文旨在解决3D场景中物体可供性分割的问题,即识别场景中哪些区域适合执行特定动作(例如,“可以放置东西的表面”)。现有方法通常需要大量训练数据,且泛化能力有限,难以适应复杂多变的室内环境。
核心思路:3D-TAFS的核心在于利用大型多模态模型(如CLIP)的强大语义理解能力,结合3D视觉信息,实现免训练的可供性分割。通过将语言指令与视觉特征对齐,无需针对特定任务进行训练,即可实现对不同场景和动作的泛化。
技术框架:3D-TAFS框架主要包含以下几个模块:1) 多模态编码器:利用CLIP等模型对语言指令和2D图像进行编码,提取语义特征。2) 3D视觉网络:处理3D点云数据,提取几何特征。3) 特征融合模块:将多模态特征和3D几何特征进行融合,得到综合表示。4) 分割模块:基于融合后的特征,预测每个3D点的可供性得分,实现分割。
关键创新:该方法最大的创新在于提出了一个免训练的框架,避免了对大量标注数据的依赖。通过利用预训练的多模态模型,实现了对不同场景和动作的泛化能力。此外,该框架有效地融合了2D图像的语义信息和3D点云的几何信息,提高了分割的准确性。
关键设计:框架的关键设计包括:1) 使用CLIP模型提取图像和文本的语义特征,保证了语义理解的准确性。2) 设计了有效的特征融合机制,将多模态特征和3D几何特征进行对齐和融合。3) 使用简单的分割模块,避免了复杂的网络结构,提高了效率。损失函数主要关注分割的准确性,采用交叉熵损失等常用损失函数。
🖼️ 关键图片


📊 实验亮点
IndoorAfford-Bench上的实验结果表明,3D-TAFS在免训练的情况下,能够实现与有监督方法相媲美的性能。该框架在各种指标上表现出竞争性的性能,验证了其在处理交互式3D可供性分割任务方面的能力。尤其是在零样本场景下,3D-TAFS的优势更加明显。
🎯 应用场景
3D-TAFS框架可应用于机器人导航、人机交互、智能家居等领域。例如,机器人可以根据用户的语言指令,识别出场景中可以放置物品的表面,从而完成物品放置任务。该研究有助于提升机器人在复杂环境中的自主性和智能化水平,实现更自然、高效的人机协作。
📄 摘要(原文)
Translating high-level linguistic instructions into precise robotic actions in the physical world remains challenging, particularly when considering the feasibility of interacting with 3D objects. In this paper, we introduce 3D-TAFS, a novel training-free multimodal framework for 3D affordance segmentation. To facilitate a comprehensive evaluation of such frameworks, we present IndoorAfford-Bench, a large-scale benchmark containing 9,248 images spanning 20 diverse indoor scenes across 6 areas, supporting standardized interaction queries. In particular, our framework integrates a large multimodal model with a specialized 3D vision network, enabling a seamless fusion of 2D and 3D visual understanding with language comprehension. Extensive experiments on IndoorAfford-Bench validate the proposed 3D-TAFS's capability in handling interactive 3D affordance segmentation tasks across diverse settings, showcasing competitive performance across various metrics. Our results highlight 3D-TAFS's potential for enhancing human-robot interaction based on affordance understanding in complex indoor environments, advancing the development of more intuitive and efficient robotic frameworks for real-world applications.