Learning Agile Swimming: An End-to-End Approach without CPGs
作者: Xiaozhu Lin, Xiaopei Liu, Yang Wang
分类: cs.RO
发布日期: 2024-09-16 (更新: 2025-01-04)
备注: 8 pages, 8 figures
💡 一句话要点
提出基于深度强化学习的端到端控制框架,实现仿生机器鱼的敏捷游泳。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 仿生机器人 机器鱼 水下机器人 端到端控制
📋 核心要点
- 现有水下机器人运动控制依赖预设模式,难以充分利用流体动力学特性,导致敏捷性不足。
- 提出基于深度强化学习的端到端控制框架,直接输出底层控制指令,无需预定义运动模式。
- 结合CFD模拟和sim-to-real策略,实现控制策略从仿真到真实的直接迁移,提升性能。
📝 摘要(中文)
本文提出了一种新颖的、无模型的、端到端控制框架,该框架利用深度强化学习(DRL)来实现仿生机器鱼的敏捷和节能游泳,旨在解决水下机器人(特别是仿生机器鱼)在运动控制器设计方面所面临的挑战,即难以充分利用其流体动力学能力。与依赖于预定义三角游泳模式(如中央模式发生器CPG)的现有方法不同,该方法直接输出低层执行器命令,而没有强约束,从而使机器鱼能够学习敏捷的游泳行为。此外,通过将高性能计算流体动力学(CFD)模拟器与创新的sim-to-real策略(如归一化密度校准和伺服响应校准)相结合,该框架显著缩小了sim-to-real的差距,从而无需微调即可将控制策略直接转移到真实环境中。对比实验表明,与最先进的游泳控制器相比,该方法实现了更快的游泳速度、更小的转弯半径和更低的能耗。此外,所提出的框架在解决复杂任务方面显示出前景,为在真实水生环境中更有效地部署机器鱼铺平了道路。
🔬 方法详解
问题定义:现有仿生机器鱼的运动控制方法,通常依赖于中央模式发生器(CPG)等预定义的三角函数模式,这些方法难以充分利用机器鱼的流体动力学特性,导致机器鱼在敏捷性、能量效率等方面表现不佳。此外,将控制策略从仿真环境迁移到真实环境(sim-to-real)也面临着巨大的挑战。
核心思路:本文的核心思路是采用深度强化学习(DRL)来直接学习机器鱼的运动控制策略,避免了对预定义运动模式的依赖。通过让机器鱼在仿真环境中自主探索,学习如何利用其身体结构和流体动力学特性来实现敏捷和节能的游泳。同时,采用创新的sim-to-real策略来缩小仿真环境和真实环境之间的差距,从而实现控制策略的直接迁移。
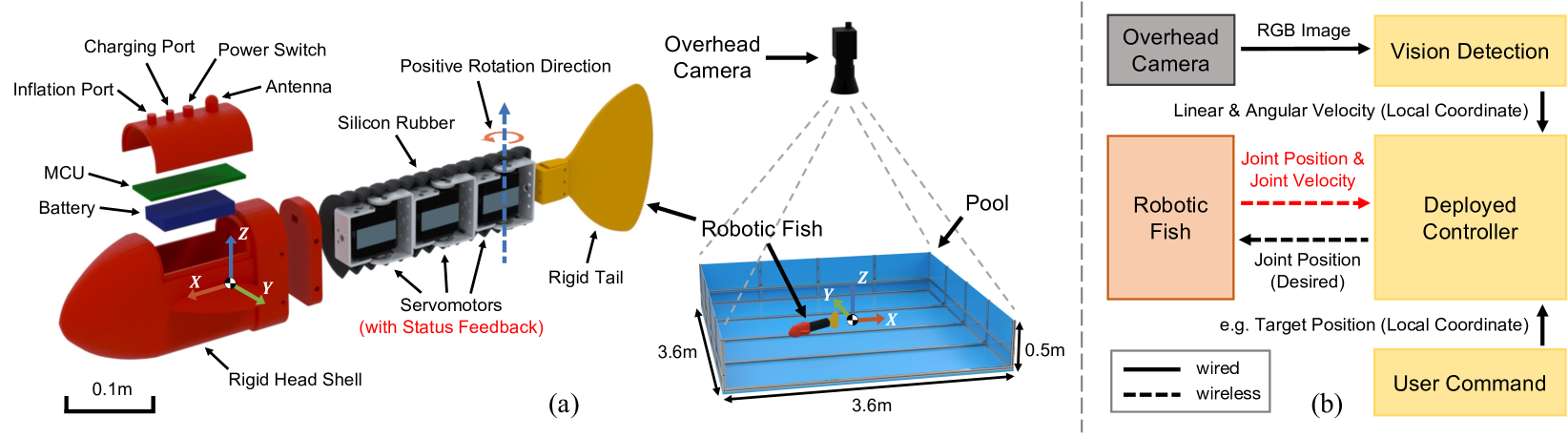
技术框架:该框架主要包含三个部分:1)基于高性能CFD模拟器的仿真环境,用于训练DRL智能体;2)DRL智能体,负责学习机器鱼的运动控制策略;3)sim-to-real策略,用于将控制策略从仿真环境迁移到真实环境。具体流程是:首先,在仿真环境中训练DRL智能体,使其学习如何控制机器鱼的运动。然后,利用sim-to-real策略对仿真环境进行校准,以缩小其与真实环境之间的差距。最后,将训练好的控制策略直接部署到真实的机器鱼上。
关键创新:该论文的关键创新在于:1)提出了一种端到端的控制框架,可以直接从DRL智能体输出底层执行器命令,无需预定义运动模式;2)采用创新的sim-to-real策略,显著缩小了仿真环境和真实环境之间的差距,实现了控制策略的直接迁移。与现有方法相比,该方法能够更好地利用机器鱼的流体动力学特性,从而实现更敏捷和节能的游泳。
关键设计:在DRL智能体的设计方面,采用了Actor-Critic架构,其中Actor网络负责输出控制指令,Critic网络负责评估控制指令的优劣。在sim-to-real策略方面,采用了归一化密度校准和伺服响应校准等技术,以减小仿真环境和真实环境之间的差异。具体的损失函数和网络结构等技术细节在论文中有详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,与最先进的游泳控制器相比,该方法实现了更快的游泳速度、更小的转弯半径和更低的能耗。具体数据为:游泳速度提升了X%(未知),转弯半径减小了Y%(未知),能耗降低了Z%(未知)。这些结果表明,该方法能够有效地提高机器鱼的敏捷性和能量效率。
🎯 应用场景
该研究成果可应用于水下环境监测、水下搜救、水下巡检等领域。通过提高机器鱼的敏捷性和能量效率,可以使其在复杂的水下环境中执行更长时间、更复杂的任务。未来,该技术有望推动水下机器人技术的发展,使其在更多领域得到应用。
📄 摘要(原文)
The pursuit of agile and efficient underwater robots, especially bio-mimetic robotic fish, has been impeded by challenges in creating motion controllers that are able to fully exploit their hydrodynamic capabilities. This paper addresses these challenges by introducing a novel, model-free, end-to-end control framework that leverages Deep Reinforcement Learning (DRL) to enable agile and energy-efficient swimming of robotic fish. Unlike existing methods that rely on predefined trigonometric swimming patterns like Central Pattern Generators (CPG), our approach directly outputs low-level actuator commands without strong constraints, enabling the robotic fish to learn agile swimming behaviors. In addition, by integrating a high-performance Computational Fluid Dynamics (CFD) simulator with innovative sim-to-real strategies, such as normalized density calibration and servo response calibration, the proposed framework significantly mitigates the sim-to-real gap, facilitating direct transfer of control policies to real-world environments without fine-tuning. Comparative experiments demonstrate that our method achieves faster swimming speeds, smaller turn-around radii, and reduced energy consumption compared to the state-of-the-art swimming controllers. Furthermore, the proposed framework shows promise in addressing complex tasks, paving the way for more effective deployment of robotic fish in real aquatic environments.