PIP-Loco: A Proprioceptive Infinite Horizon Planning Framework for Quadrupedal Robot Locomotion
作者: Aditya Shirwatkar, Naman Saxena, Kishore Chandra, Shishir Kolathaya
分类: cs.RO, cs.LG
发布日期: 2024-09-14 (更新: 2025-04-15)
备注: Accepted at IEEE International Conference on Robotics and Automation (ICRA) 2025
💡 一句话要点
PIP-Loco:融合规划与强化学习的四足机器人无限时域运动框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 运动控制 强化学习 模型预测控制 本体感受规划
📋 核心要点
- 传统MPC方法在复杂地形和任务中存在鲁棒性问题,而无模型RL方法缺乏约束处理和规划能力。
- 论文提出PIP-Loco框架,融合本体感受规划与强化学习,利用内部模型进行无限时域的运动规划。
- 实验结果表明,该框架在多地形场景中具有良好的鲁棒性,并在仿真和硬件平台上均得到验证。
📝 摘要(中文)
针对四足机器人运动控制,模型预测控制(MPC)虽然能够实施约束并提供可解释的指令序列,但在复杂任务和快速变化的地形上表现不佳。另一方面,无模型强化学习(RL)方法在多种地形上优于MPC,但缺乏处理约束或进行规划的能力。为了解决这些局限性,我们提出了一个将本体感受规划与RL相结合的框架,通过时域实现敏捷和安全的运动行为。受MPC启发,我们引入了一个包含速度估计器和Dreamer模块的内部模型。在训练过程中,该框架学习一个专家策略和一个相互依赖的内部模型,从而促进探索以改进运动行为。在部署期间,Dreamer模块解决一个无限时域MPC问题,调整动作和速度命令以满足约束。我们通过内部模型组件的消融研究验证了训练框架的鲁棒性,并证明了其对训练噪声的改进鲁棒性。最后,我们在仿真和硬件中的多地形场景中评估了我们的方法。
🔬 方法详解
问题定义:现有的四足机器人运动控制方法,如MPC,在面对复杂地形和快速变化的环境时,鲁棒性不足。而无模型强化学习虽然在某些地形上表现出色,但缺乏对约束的显式处理和长时域规划能力,难以保证运动的安全性和稳定性。
核心思路:论文的核心思路是将本体感受规划与强化学习相结合,利用强化学习训练一个专家策略和一个内部模型,该模型能够预测未来的状态和奖励,从而实现无限时域的规划。通过内部模型,机器人可以预见未来的风险并采取相应的措施,从而提高运动的鲁棒性和安全性。
技术框架:PIP-Loco框架主要包含三个模块:速度估计器、Dreamer模块和强化学习策略。速度估计器用于估计机器人的当前状态,Dreamer模块是一个内部模型,用于预测未来的状态和奖励。强化学习策略根据当前状态和Dreamer模块的预测结果,生成机器人的动作指令。在训练阶段,强化学习策略和Dreamer模块是共同训练的,以提高预测的准确性和策略的性能。在部署阶段,Dreamer模块用于解决一个无限时域的MPC问题,从而实现长时域的运动规划。
关键创新:该论文的关键创新在于将强化学习与内部模型相结合,实现无限时域的运动规划。传统的MPC方法需要显式地定义环境模型,而该方法通过强化学习自动学习环境模型,从而提高了对复杂环境的适应性。此外,该方法还能够显式地处理约束,从而保证运动的安全性和稳定性。
关键设计:Dreamer模块采用了一种基于隐变量模型的结构,能够学习环境的动态特性。强化学习策略采用了一种Actor-Critic结构,Actor网络用于生成动作指令,Critic网络用于评估动作的价值。损失函数包括状态预测损失、奖励预测损失和策略梯度损失。训练过程中,采用了多种技巧来提高训练的稳定性和效率,例如经验回放、目标网络和梯度裁剪。
🖼️ 关键图片
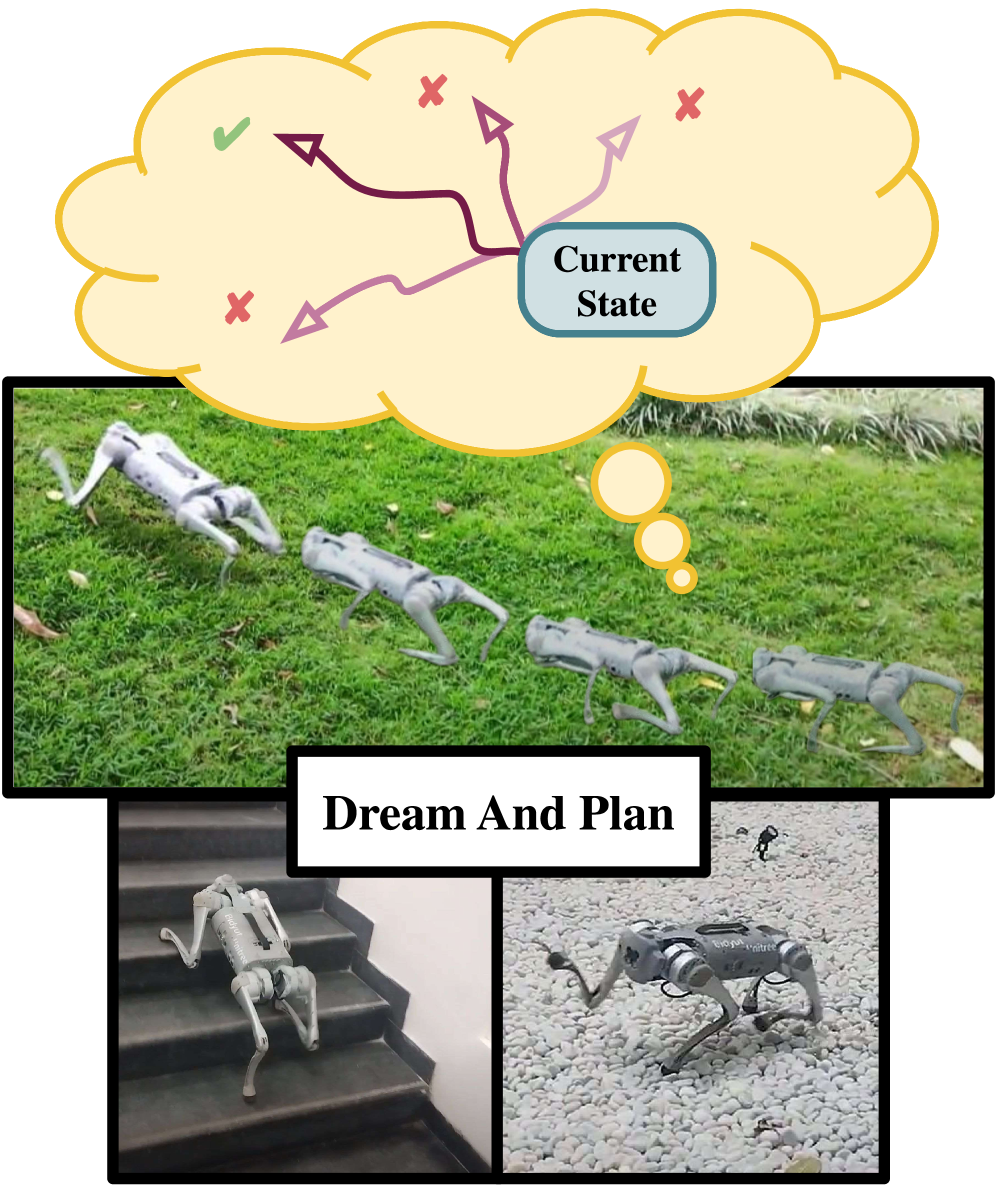
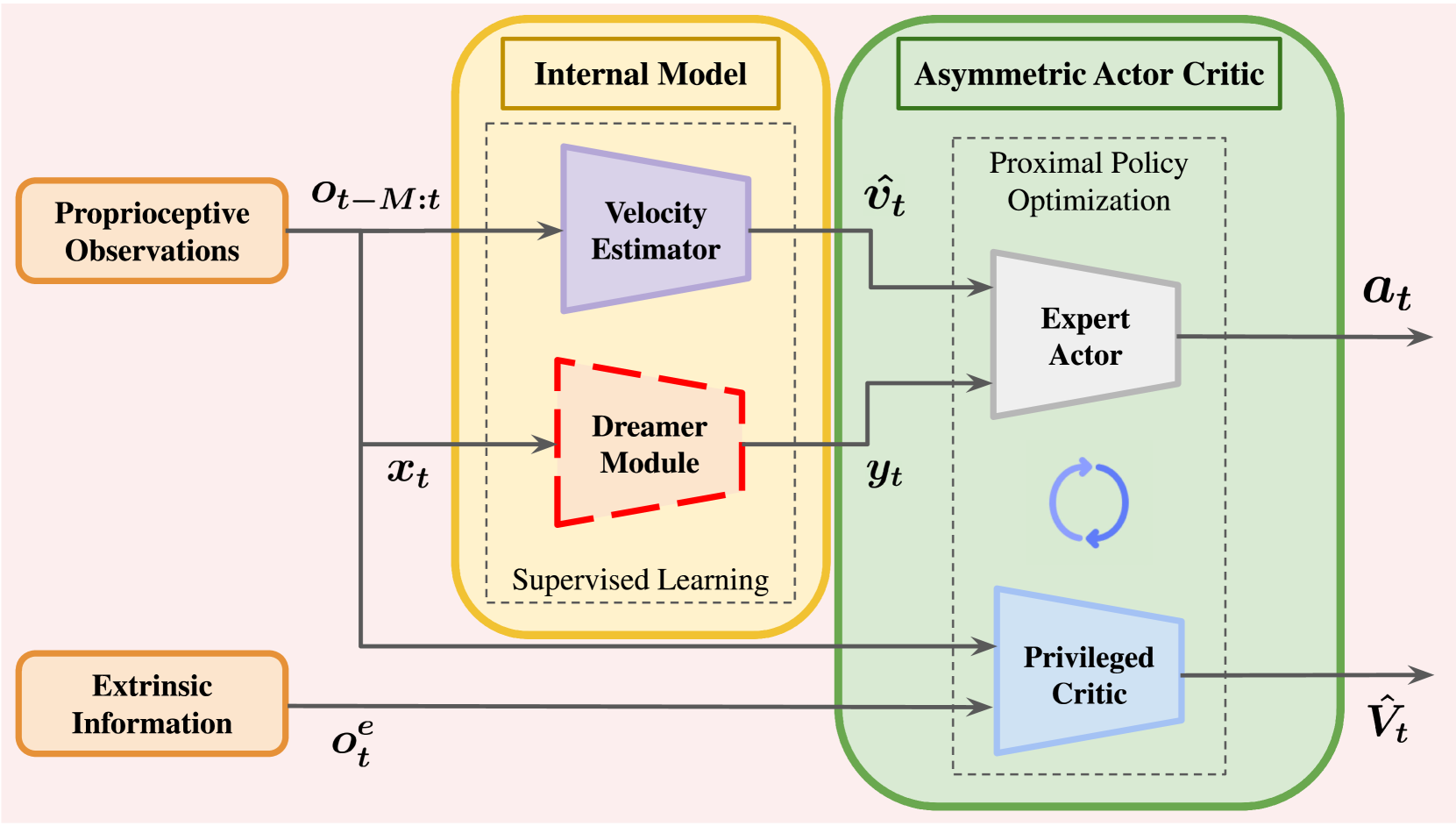
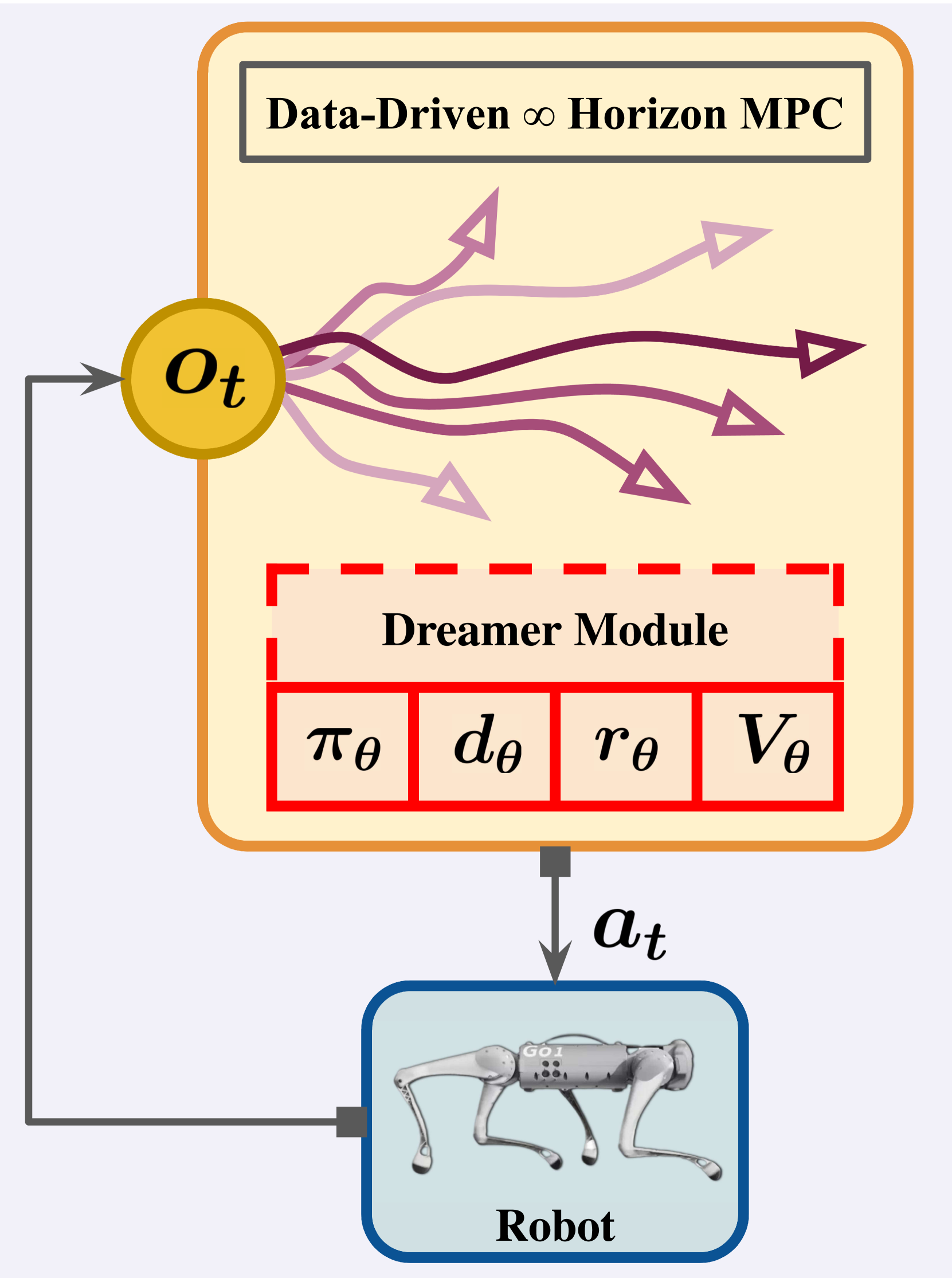
📊 实验亮点
论文通过消融实验验证了内部模型各组件的有效性,并证明了该框架对训练噪声具有更强的鲁棒性。在仿真和硬件实验中,PIP-Loco在多地形场景下表现出优异的运动能力,相较于传统方法,能够更好地适应复杂环境,并实现更稳定的运动控制。
🎯 应用场景
该研究成果可应用于各种需要四足机器人进行复杂地形运动的场景,例如搜救、勘探、物流等。通过提高四足机器人的运动能力和鲁棒性,可以使其在恶劣环境中执行任务,从而降低人类的风险和成本。此外,该研究还可以为其他类型的机器人运动控制提供借鉴。
📄 摘要(原文)
A core strength of Model Predictive Control (MPC) for quadrupedal locomotion has been its ability to enforce constraints and provide interpretability of the sequence of commands over the horizon. However, despite being able to plan, MPC struggles to scale with task complexity, often failing to achieve robust behavior on rapidly changing surfaces. On the other hand, model-free Reinforcement Learning (RL) methods have outperformed MPC on multiple terrains, showing emergent motions but inherently lack any ability to handle constraints or perform planning. To address these limitations, we propose a framework that integrates proprioceptive planning with RL, allowing for agile and safe locomotion behaviors through the horizon. Inspired by MPC, we incorporate an internal model that includes a velocity estimator and a Dreamer module. During training, the framework learns an expert policy and an internal model that are co-dependent, facilitating exploration for improved locomotion behaviors. During deployment, the Dreamer module solves an infinite-horizon MPC problem, adapting actions and velocity commands to respect the constraints. We validate the robustness of our training framework through ablation studies on internal model components and demonstrate improved robustness to training noise. Finally, we evaluate our approach across multi-terrain scenarios in both simulation and hardware.