Learning Robotic Manipulation Policies from Point Clouds with Conditional Flow Matching
作者: Eugenio Chisari, Nick Heppert, Max Argus, Tim Welschehold, Thomas Brox, Abhinav Valada
分类: cs.RO
发布日期: 2024-09-11
备注: Presented at CoRL 2024. Project website at http://pointflowmatch.cs.uni-freiburg.de/
💡 一句话要点
提出PointFlowMatch,结合点云与条件流匹配学习机器人操作策略,显著提升任务成功率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 模仿学习 条件流匹配 点云 扩散模型 策略学习 RLBench
📋 核心要点
- 模仿学习训练机器人策略面临输入模态、训练目标和姿态表示等多种设计选择,现有方法难以兼顾。
- 论文提出PointFlowMatch,结合点云输入和条件流匹配(CFM),利用CFM处理多模态动作分布的优势。
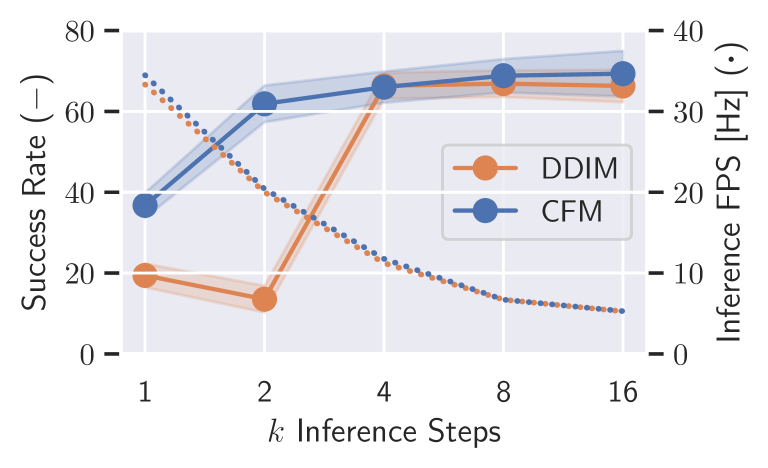
- 在RLBench的实验表明,PointFlowMatch在多个任务上显著优于现有方法,平均成功率达到67.8%。
📝 摘要(中文)
本文研究了如何从专家演示中学习机器人操作策略,特别关注了输入模态、训练目标和6自由度末端执行器姿态表示等设计选择。扩散模型因其能够预测长时程轨迹和处理多模态动作分布而备受欢迎。最近,条件流匹配(CFM)被提出作为扩散模型的一种更灵活的泛化。本文探讨了CFM在机器人策略学习中的应用,并研究了其与其他设计选择的相互作用。结果表明,CFM与点云输入观测相结合时性能最佳。此外,我们研究了在SO(3)流形上进行CFM公式化的可行性,并通过一个简化的例子评估了其适用性。在RLBench上进行的大量实验表明,我们提出的PointFlowMatch方法在八个任务上实现了67.8%的最先进平均成功率,是下一个最佳方法的两倍。
🔬 方法详解
问题定义:现有机器人操作策略学习方法在模仿学习中面临诸多设计选择,例如输入模态、训练目标和6自由度末端执行器姿态表示。这些选择会显著影响策略的学习效果。此外,传统方法难以有效处理多模态动作分布,限制了策略的泛化能力。
核心思路:论文的核心思路是将条件流匹配(CFM)应用于机器人策略学习,并结合点云输入。CFM作为扩散模型的泛化,能够更灵活地学习复杂的动作分布,并预测长时程轨迹。点云作为一种有效的场景表示,能够提供丰富的几何信息,有助于策略理解环境。
技术框架:PointFlowMatch方法的整体框架包括以下几个主要模块:1) 点云输入:使用点云传感器获取环境信息。2) 特征提取:使用神经网络提取点云特征。3) 条件流匹配:利用CFM模型学习从点云特征到动作的映射关系。4) 动作执行:将CFM模型预测的动作发送给机器人执行。
关键创新:该论文的关键创新在于将条件流匹配(CFM)应用于机器人策略学习,并结合点云输入。与传统的扩散模型相比,CFM具有更强的灵活性和更好的训练效率。此外,论文还研究了CFM在SO(3)流形上的应用,为处理旋转动作提供了一种新的思路。
关键设计:论文中一些关键的设计包括:1) 使用PointNet++提取点云特征。2) 使用Transformer网络构建CFM模型。3) 使用L2损失函数训练CFM模型。4) 探索了SO(3)流形上的CFM公式化,并使用指数映射和对数映射进行姿态表示。
🖼️ 关键图片


📊 实验亮点
PointFlowMatch在RLBench的八个任务上取得了显著的性能提升,平均成功率达到67.8%,是下一个最佳方法的两倍。这一结果表明,结合点云输入和条件流匹配(CFM)能够有效提高机器人策略学习的性能。此外,论文还验证了CFM在SO(3)流形上的可行性,为处理旋转动作提供了一种新的思路。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如物体抓取、装配、导航等。通过模仿学习,机器人可以从人类专家的演示中学习复杂的技能,从而提高自动化水平和生产效率。该方法在工业自动化、服务机器人和医疗机器人等领域具有广阔的应用前景。
📄 摘要(原文)
Learning from expert demonstrations is a promising approach for training robotic manipulation policies from limited data. However, imitation learning algorithms require a number of design choices ranging from the input modality, training objective, and 6-DoF end-effector pose representation. Diffusion-based methods have gained popularity as they enable predicting long-horizon trajectories and handle multimodal action distributions. Recently, Conditional Flow Matching (CFM) (or Rectified Flow) has been proposed as a more flexible generalization of diffusion models. In this paper, we investigate the application of CFM in the context of robotic policy learning and specifically study the interplay with the other design choices required to build an imitation learning algorithm. We show that CFM gives the best performance when combined with point cloud input observations. Additionally, we study the feasibility of a CFM formulation on the SO(3) manifold and evaluate its suitability with a simplified example. We perform extensive experiments on RLBench which demonstrate that our proposed PointFlowMatch approach achieves a state-of-the-art average success rate of 67.8% over eight tasks, double the performance of the next best method.