One Policy to Run Them All: an End-to-end Learning Approach to Multi-Embodiment Locomotion
作者: Nico Bohlinger, Grzegorz Czechmanowski, Maciej Krupka, Piotr Kicki, Krzysztof Walas, Jan Peters, Davide Tateo
分类: cs.RO, cs.LG
发布日期: 2024-09-10 (更新: 2025-10-01)
💡 一句话要点
提出URMA:一种端到端多形态机器人运动学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多形态机器人 强化学习 运动控制 零样本迁移 形态无关
📋 核心要点
- 现有腿式机器人控制方法难以泛化到不同形态的机器人,缺乏统一的学习框架。
- URMA通过形态无关的编码器和解码器,学习抽象的运动控制器,实现跨形态的策略共享。
- 实验证明URMA学习的策略可以迁移到模拟和真实环境中未见过的机器人平台。
📝 摘要(中文)
深度强化学习技术在鲁棒的腿式机器人运动控制方面取得了显著进展。然而,目前缺乏一个能够轻松有效地控制各种腿式机器人平台(如四足、人形和六足机器人),并能零样本或少样本迁移到未见过的机器人形态的统一学习框架。本文提出了统一机器人形态架构(URMA),旨在弥合这一差距。URMA将端到端的多任务强化学习方法引入腿式机器人领域,使学习到的策略能够控制任何类型的机器人形态。该方法的关键思想是,借助形态无关的编码器和解码器,网络可以学习一种抽象的运动控制器,从而在不同形态之间无缝共享。这种灵活的架构可以被视为构建腿式机器人运动基础模型的潜在第一步。实验表明,URMA可以在多种形态上学习运动策略,并可以轻松地迁移到模拟和真实世界中未见过的机器人平台。
🔬 方法详解
问题定义:现有腿式机器人控制方法通常针对特定机器人形态设计,难以泛化到其他形态的机器人。缺乏一个统一的学习框架,能够处理各种腿式机器人平台,并实现零样本或少样本迁移到未见过的机器人形态。这限制了腿式机器人在复杂和多样化环境中的应用。
核心思路:URMA的核心思路是学习一个抽象的运动控制器,该控制器不依赖于特定的机器人形态。通过形态无关的编码器和解码器,将机器人形态信息从输入中解耦,使网络能够学习一种通用的运动策略,从而实现跨形态的策略共享和迁移。
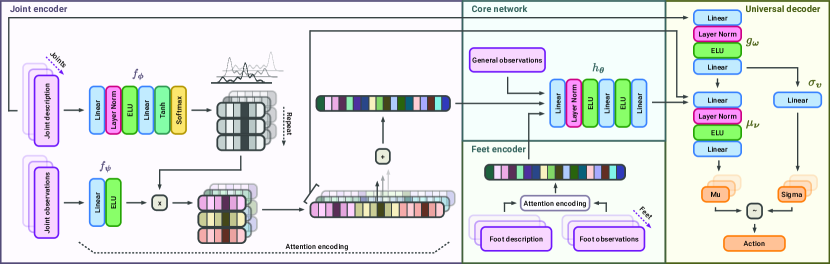
技术框架:URMA的整体架构是一个端到端的强化学习框架,包括以下主要模块:1) 机器人状态编码器:将机器人状态(如关节角度、速度等)编码为低维向量表示。2) 形态编码器:将机器人形态信息(如腿的数量、长度等)编码为低维向量表示。3) 运动控制器:根据状态编码和形态编码,生成控制指令。4) 运动解码器:将控制指令解码为具体的关节力矩或位置控制信号。5) 强化学习算法:使用强化学习算法(如PPO)训练运动控制器,使其能够实现期望的运动目标。
关键创新:URMA最重要的技术创新点在于其形态无关的编码器和解码器设计。这些模块能够将机器人状态和形态信息解耦,使网络能够学习一种通用的运动策略,从而实现跨形态的策略共享和迁移。与现有方法相比,URMA不需要针对每种机器人形态单独训练策略,大大提高了学习效率和泛化能力。
关键设计:URMA的关键设计包括:1) 形态编码器的输入特征选择:选择能够充分描述机器人形态的关键参数,如腿的数量、长度、质量分布等。2) 损失函数设计:除了标准的强化学习奖励函数外,还可以添加一些辅助损失函数,如形态一致性损失,以鼓励网络学习形态无关的表示。3) 网络结构设计:可以使用Transformer等具有强大表示能力的神经网络结构,以提高编码器和解码器的性能。
🖼️ 关键图片

📊 实验亮点
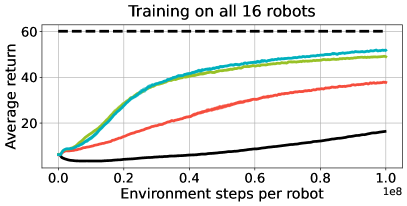
URMA在多种模拟和真实机器人平台上进行了实验验证。实验结果表明,URMA学习的策略可以成功迁移到未见过的机器人形态上,并且在某些情况下,其性能甚至优于针对特定机器人形态训练的策略。例如,URMA可以在四足机器人上学习运动策略,然后将其零样本迁移到六足机器人上,并实现稳定的行走。
🎯 应用场景
URMA具有广泛的应用前景,例如:1) 快速部署新型腿式机器人:无需针对每种新型机器人单独训练策略,可以快速将其部署到实际应用中。2) 机器人集群控制:可以利用URMA控制不同形态的机器人协同完成任务。3) 虚拟环境训练:可以在虚拟环境中训练URMA,然后将其迁移到真实机器人上,降低了训练成本和风险。未来,URMA有望成为腿式机器人领域的基础模型。
📄 摘要(原文)
Deep Reinforcement Learning techniques are achieving state-of-the-art results in robust legged locomotion. While there exists a wide variety of legged platforms such as quadruped, humanoids, and hexapods, the field is still missing a single learning framework that can control all these different embodiments easily and effectively and possibly transfer, zero or few-shot, to unseen robot embodiments. We introduce URMA, the Unified Robot Morphology Architecture, to close this gap. Our framework brings the end-to-end Multi-Task Reinforcement Learning approach to the realm of legged robots, enabling the learned policy to control any type of robot morphology. The key idea of our method is to allow the network to learn an abstract locomotion controller that can be seamlessly shared between embodiments thanks to our morphology-agnostic encoders and decoders. This flexible architecture can be seen as a potential first step in building a foundation model for legged robot locomotion. Our experiments show that URMA can learn a locomotion policy on multiple embodiments that can be easily transferred to unseen robot platforms in simulation and the real world.