StratXplore: Strategic Novelty-seeking and Instruction-aligned Exploration for Vision and Language Navigation
作者: Muraleekrishna Gopinathan, Jumana Abu-Khalaf, David Suter, Martin Masek
分类: cs.RO
发布日期: 2024-09-09
💡 一句话要点
StratXplore:面向视觉语言导航的策略性新颖性探索与指令对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 具身智能 路径规划 探索策略 机器人导航
📋 核心要点
- 现有VLN方法依赖回溯进行错误恢复,效率低下,且易受指令复杂性和环境部分可观测性的影响。
- StratXplore通过记忆机制感知错误,并策略性地探索与指令对齐的新颖视点,实现更优的路径校正。
- 实验表明,StratXplore在两个VLN数据集上提高了导航成功率,验证了其有效性。
📝 摘要(中文)
具身导航要求机器人理解环境并根据给定的任务进行交互。视觉语言导航(VLN)是一项具身导航任务,其中机器人根据语言指令和视觉输入,在先前见过和未见过的环境中导航。VLN智能体需要访问局部和全局动作空间;前者用于即时决策,后者用于从导航错误中恢复。先前的VLN智能体仅依赖于指令-视点对齐来进行局部和全局决策,如果指令与其当前视点不匹配,则会回溯到先前访问过的视点。由于指令的复杂性和环境的部分可观察性,这些方法容易出错。我们认为,回溯是次优的,并且意识到自己错误的智能体可以有效地恢复。为了实现最佳恢复,探索应扩展到未探索的视点(或边界)。最佳边界是最近观察到但未探索的、与指令对齐且新颖的视点。我们为VLN智能体引入了一种基于记忆且能感知错误的路径规划策略,称为 extit{StratXplore},它提出了全局和局部动作规划来选择用于路径校正的最佳边界。所提出的方法收集导航期间的所有过去动作和视点特征,然后选择适合恢复的最佳边界。实验结果表明,这种简单而有效的策略提高了在具有不同任务复杂性的两个VLN数据集上的成功率。
🔬 方法详解
问题定义:论文旨在解决视觉语言导航(VLN)任务中,智能体在遇到导航错误时,如何更有效地进行路径恢复的问题。现有方法主要依赖于回溯到先前访问过的视点,这种策略效率低下,尤其是在复杂环境中,容易陷入局部最优,且无法充分利用未探索区域的信息。
核心思路:论文的核心思路是让智能体具备“策略性新颖性探索”的能力。当智能体意识到导航错误时,不再简单地回溯,而是主动探索与当前指令对齐且具有新颖性的视点(frontier),从而找到更优的恢复路径。这种方法旨在克服回溯策略的局限性,提高导航效率和成功率。
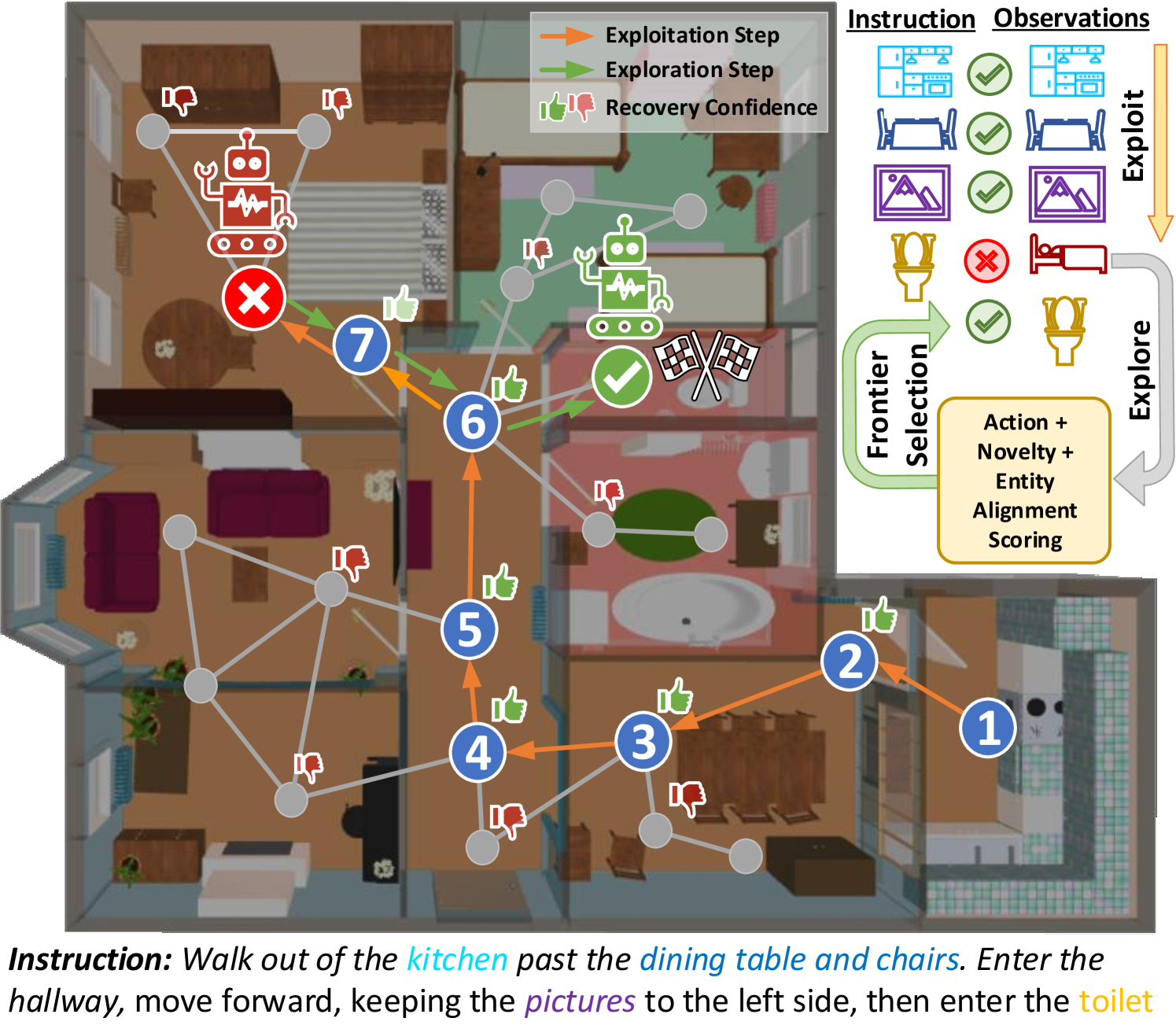
技术框架:StratXplore包含以下主要模块:1) 记忆模块:用于存储过去的行为和视点特征,帮助智能体感知错误。2) 全局动作规划:基于记忆模块的信息,选择潜在的frontier视点。3) 局部动作规划:在选定的frontier视点附近进行局部探索,以精确调整路径。4) 决策模块:综合考虑全局和局部规划的结果,选择最终的行动。
关键创新:StratXplore的关键创新在于引入了“策略性新颖性探索”的概念,并将其应用于VLN任务的路径恢复。与现有方法的回溯策略相比,StratXplore能够更有效地利用未探索区域的信息,从而找到更优的恢复路径。此外,基于记忆的错误感知机制也提高了智能体对自身状态的理解。
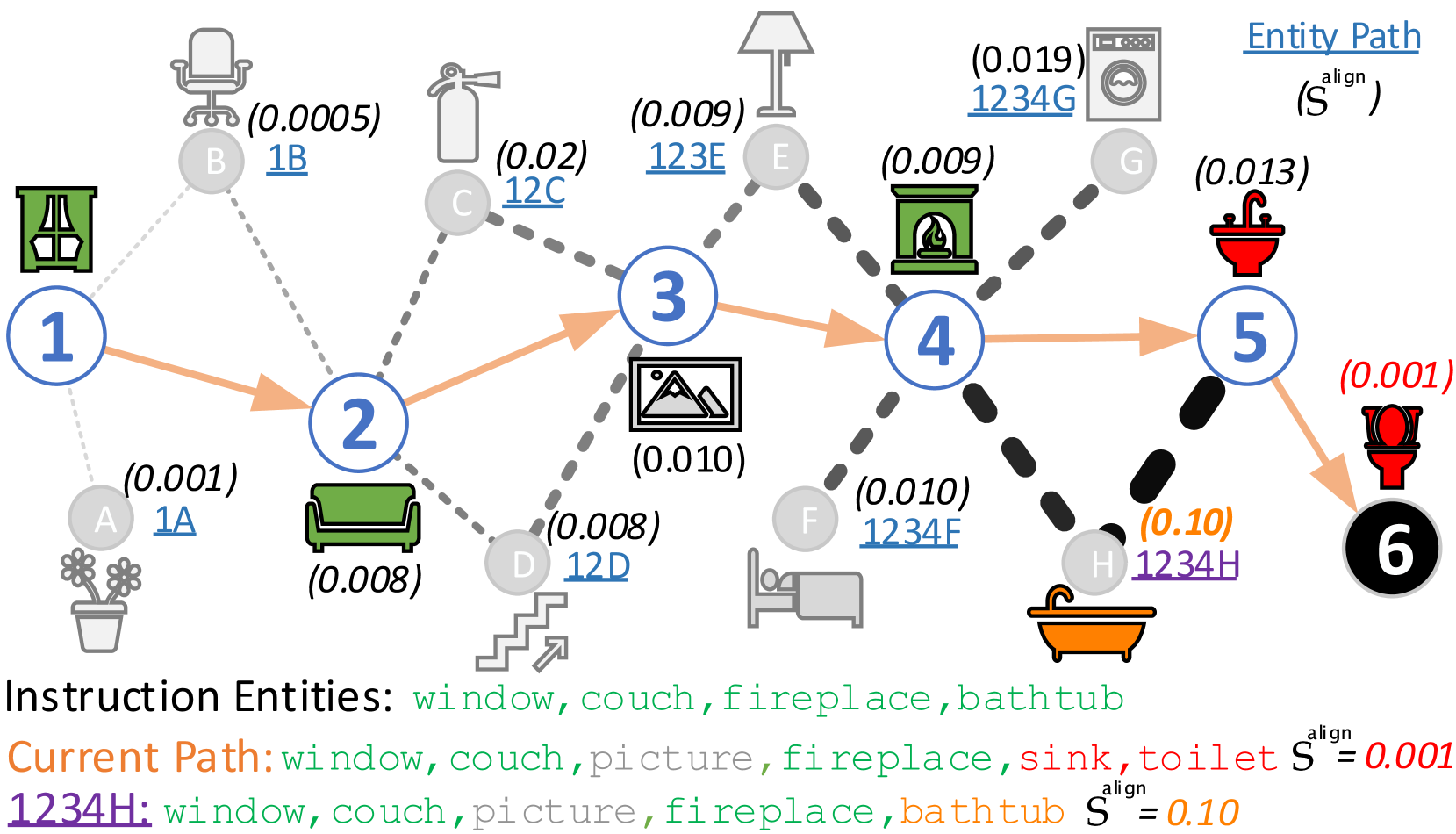
关键设计:论文中,frontier视点的选择是关键。论文定义了frontier视点需要满足两个条件:一是与当前指令对齐,二是具有新颖性。指令对齐可以通过计算指令和视点特征之间的相似度来实现。新颖性可以通过比较当前视点与已访问视点的差异来衡量。具体的参数设置和网络结构在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片

📊 实验亮点
StratXplore在两个VLN数据集上进行了实验,结果表明,该方法能够显著提高导航成功率。具体的数据和对比基线在摘要中没有给出,但强调了该方法在不同任务复杂度的场景下均表现出良好的性能。实验结果验证了策略性新颖性探索在VLN任务中的有效性。
🎯 应用场景
StratXplore的研究成果可应用于各种需要自主导航的机器人应用场景,例如:家庭服务机器人、仓库物流机器人、自动驾驶汽车等。通过提高机器人在复杂环境中的导航能力,可以提升其工作效率和可靠性,从而更好地服务于人类生活和生产。
📄 摘要(原文)
Embodied navigation requires robots to understand and interact with the environment based on given tasks. Vision-Language Navigation (VLN) is an embodied navigation task, where a robot navigates within a previously seen and unseen environment, based on linguistic instruction and visual inputs. VLN agents need access to both local and global action spaces; former for immediate decision making and the latter for recovering from navigational mistakes. Prior VLN agents rely only on instruction-viewpoint alignment for local and global decision making and back-track to a previously visited viewpoint, if the instruction and its current viewpoint mismatches. These methods are prone to mistakes, due to the complexity of the instruction and partial observability of the environment. We posit that, back-tracking is sub-optimal and agent that is aware of its mistakes can recover efficiently. For optimal recovery, exploration should be extended to unexplored viewpoints (or frontiers). The optimal frontier is a recently observed but unexplored viewpoint that aligns with the instruction and is novel. We introduce a memory-based and mistake-aware path planning strategy for VLN agents, called \textit{StratXplore}, that presents global and local action planning to select the optimal frontier for path correction. The proposed method collects all past actions and viewpoint features during navigation and then selects the optimal frontier suitable for recovery. Experimental results show this simple yet effective strategy improves the success rate on two VLN datasets with different task complexities.