IR2: Implicit Rendezvous for Robotic Exploration Teams under Sparse Intermittent Connectivity
作者: Derek Ming Siang Tan, Yixiao Ma, Jingsong Liang, Yi Cheng Chng, Yuhong Cao, Guillaume Sartoretti
分类: cs.RO
发布日期: 2024-09-07 (更新: 2025-10-21)
备注: \c{opyright} 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
💡 一句话要点
针对稀疏间断连接下机器人探索团队,提出基于隐式汇合的深度强化学习方法IR2
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多机器人探索 深度强化学习 信息共享 稀疏通信 隐式汇合
📋 核心要点
- 现有方法在多机器人探索中,常忽略稀疏间断连接的通信约束,或因预先规划汇合点导致不必要的绕行。
- IR2利用深度强化学习,通过注意力机制神经网络,使机器人权衡独立探索和信息共享的长期收益。
- 实验表明,IR2在探索路径长度上优于现有方法6.6-34.1%,并在硬件上验证了策略的有效性。
📝 摘要(中文)
本文提出了一种名为IR2的深度强化学习方法,用于解决稀疏和间断连接下多机器人探索的信息共享问题。针对现有方法忽略通信约束或效率低下的问题,IR2利用基于注意力机制的神经网络,通过强化学习和课程学习,使机器人能够有效权衡断开连接进行独立探索和重新连接进行信息共享之间的长期利弊。此外,论文提出了一种分层图结构,以维护稀疏但信息丰富的图,从而使该方法能够扩展到大规模环境。在三个大规模Gazebo环境中进行的仿真结果表明,与最先进的基线方法相比,IR2的探索路径缩短了6.6-34.1%。最后,论文还将学习到的策略部署在硬件上。
🔬 方法详解
问题定义:论文旨在解决在通信受限(稀疏且间断连接)的大规模环境中,多机器人团队如何高效地进行信息共享和协同探索的问题。现有方法要么假设全局连通性,这在实际场景中不成立;要么采用保持近距离或视线连接的方式,导致效率低下,例如预先规划的汇合点方法会产生不必要的绕行,而基于追逐的方法则过于贪婪,导致短视决策。
核心思路:IR2的核心思路是让机器人学习在断开连接进行独立探索和重新连接进行信息共享之间进行权衡。通过深度强化学习,机器人可以预测未来收益,从而做出更明智的决策,避免盲目地追求即时通信或不必要的绕行。隐式汇合是指机器人不需要预先规划具体的汇合地点,而是通过学习到的策略,在合适的时间和地点自发地汇合,以交换信息。
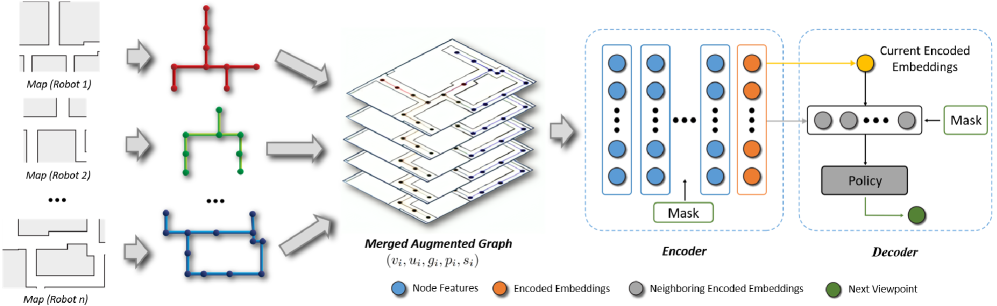
技术框架:IR2的整体框架包括以下几个主要部分:1) 基于注意力机制的神经网络:用于学习机器人的策略,输入包括机器人的局部观测、通信状态和历史信息等,输出是机器人的动作。2) 强化学习训练:使用强化学习算法(具体算法未知)训练神经网络,目标是最大化探索效率。3) 课程学习:通过逐步增加环境的复杂性,加速训练过程并提高策略的泛化能力。4) 分层图结构:用于维护环境的地图信息,并支持大规模环境的探索。该图结构是稀疏的,但包含了足够的信息,以便机器人进行决策。
关键创新:IR2的关键创新在于:1) 提出了隐式汇合的概念,允许机器人在没有预先规划的情况下自发地汇合,从而提高了探索效率。2) 使用基于注意力机制的神经网络,使机器人能够有效地处理复杂的环境信息和通信状态。3) 提出了分层图结构,使该方法能够扩展到大规模环境。与现有方法的本质区别在于,IR2不是简单地追求即时通信或预先规划汇合点,而是通过学习到的策略,在探索效率和信息共享之间进行权衡。
关键设计:论文中关于关键设计的细节描述相对有限。已知的信息包括:使用了基于注意力机制的神经网络,但具体的网络结构未知。使用了强化学习算法进行训练,但具体的算法选择未知。使用了课程学习来加速训练,但具体的课程设置未知。提出了分层图结构,但具体的图结构和维护方法未知。损失函数和参数设置等细节也未在摘要中提及,属于未知信息。
🖼️ 关键图片

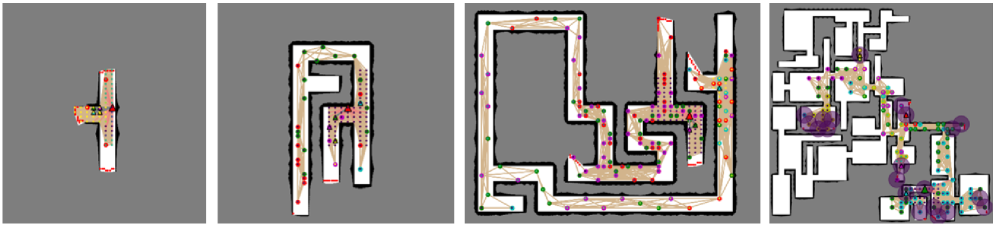
📊 实验亮点
实验结果表明,IR2在三个大规模Gazebo仿真环境中,与最先进的基线方法相比,探索路径长度缩短了6.6-34.1%。这一结果表明,IR2能够有效地权衡探索效率和信息共享,从而提高了多机器人探索的整体性能。此外,论文还将学习到的策略部署在硬件上,验证了该方法在实际场景中的可行性。
🎯 应用场景
IR2适用于各种需要在通信受限环境下进行多机器人协同探索的场景,例如灾难救援、矿山勘探、环境监测和太空探索等。该研究的实际价值在于提高了多机器人探索的效率和鲁棒性,使其能够在更复杂的环境中完成任务。未来,IR2可以进一步扩展到异构机器人团队,并与其他感知和规划技术相结合,以实现更智能化的多机器人系统。
📄 摘要(原文)
Information sharing is critical in time-sensitive and realistic multi-robot exploration, especially for smaller robotic teams in large-scale environments where connectivity may be sparse and intermittent. Existing methods often overlook such communication constraints by assuming unrealistic global connectivity. Other works account for communication constraints (by maintaining close proximity or line of sight during information exchange), but are often inefficient. For instance, preplanned rendezvous approaches typically involve unnecessary detours resulting from poorly timed rendezvous, while pursuit-based approaches often result in short-sighted decisions due to their greedy nature. We present IR2, a deep reinforcement learning approach to information sharing for multi-robot exploration. Leveraging attention-based neural networks trained via reinforcement and curriculum learning, IR2 allows robots to effectively reason about the longer-term trade-offs between disconnecting for solo exploration and reconnecting for information sharing. In addition, we propose a hierarchical graph formulation to maintain a sparse yet informative graph, enabling our approach to scale to large-scale environments. We present simulation results in three large-scale Gazebo environments, which show that our approach yields 6.6-34.1% shorter exploration paths when compared to state-of-the-art baselines, and lastly deploy our learned policy on hardware. Our simulation training and testing code is available at https://ir2-explore.github.io.