Continual Skill and Task Learning via Dialogue
作者: Weiwei Gu, Suresh Kondepudi, Lixiao Huang, Nakul Gopalan
分类: cs.RO, cs.AI, cs.CL
发布日期: 2024-09-05 (更新: 2024-09-11)
💡 一句话要点
提出基于对话的持续技能与任务学习框架,提升机器人交互学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 机器人学习 人机交互 自然语言对话 技能学习
📋 核心要点
- 现有方法难以使机器人通过交互高效地持续学习新技能和任务,尤其是在与人类用户交互时。
- 该论文提出了一种基于对话的持续学习框架,利用语言-技能对齐嵌入和大型语言模型进行交互式学习。
- 实验表明,该方法在少样本学习新技能和保持原有技能方面均表现出色,并在真实机器人任务中取得了良好效果。
📝 摘要(中文)
本文提出了一种持续交互式机器人学习框架,旨在使机器人能够通过与人类用户的自然语言对话交互,高效地学习新技能以解决新任务。该框架结合了对话机制和语言-技能对齐嵌入,用于查询或确认用户请求的技能和/或任务。该框架集成了三个关键组件:一是ACT-LoRA,一种基于低秩自适应的视觉-运动控制策略,使现有最优ACT模型能够进行少样本持续学习;二是技能对齐模型,将跨技能表征的演示投影到共享嵌入空间,从而判断何时向用户提问或请求演示;三是集成现有大型语言模型(LLM),与人类用户交互,以执行基于上下文的交互式持续技能学习来解决任务。实验表明,ACT-LoRA模型仅用五个新技能的演示进行训练,即可达到100%的准确率,同时在RLBench数据集的预训练技能上保持74.75%的准确率。一项包含8名受试者的人工评估研究表明,该框架在三明治制作任务中实现了75%的成功率,证明了机器人可以通过与非专业用户的对话学习新技能或任务知识。
🔬 方法详解
问题定义:现有机器人学习方法要么侧重于提高指令跟随代理的性能,要么被动地学习新技能或概念。然而,在实际应用中,机器人需要能够与人类用户交互,主动学习新技能以解决新任务,并且需要具备持续学习的能力,即在学习新技能的同时,不忘记已学技能。
核心思路:本文的核心思路是利用自然语言对话作为机器人与人类用户交互的桥梁,通过对话主动查询和确认用户请求的技能和任务信息。同时,利用语言-技能对齐嵌入,将语言指令和机器人技能联系起来,从而使机器人能够理解用户的意图并执行相应的动作。
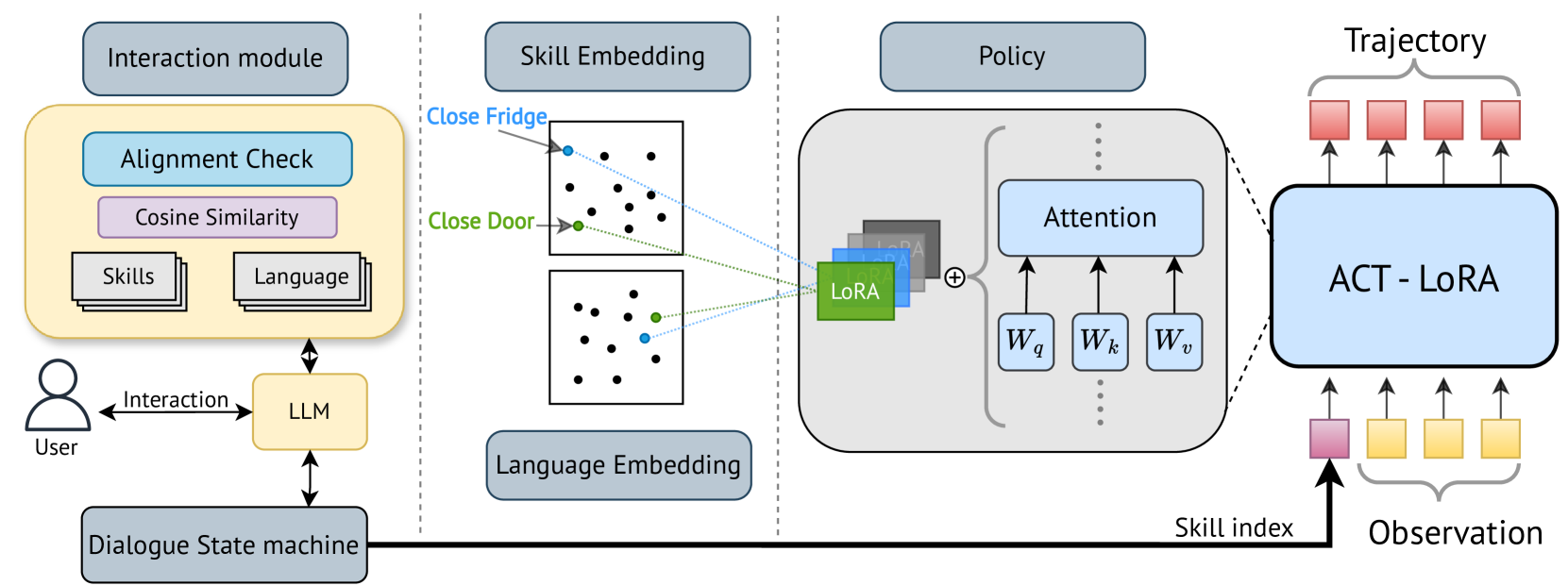
技术框架:该框架包含三个主要模块:1) ACT-LoRA:用于视觉-运动控制的策略网络,基于ACT模型,并采用低秩自适应方法进行持续学习;2) 技能对齐模型:将不同技能的演示投影到共享嵌入空间,用于判断何时需要向用户提问或请求演示;3) 大型语言模型(LLM):用于与人类用户进行自然语言对话,理解用户的意图并提供反馈。整体流程是:用户通过自然语言指令请求机器人执行任务,LLM解析指令,技能对齐模型判断是否需要向用户提问或请求演示,ACT-LoRA执行相应的动作,并根据用户的反馈进行调整。
关键创新:该论文的关键创新在于将对话机制与语言-技能对齐嵌入相结合,实现了机器人与人类用户之间的交互式持续学习。ACT-LoRA模型通过低秩自适应方法,在少样本学习新技能的同时,有效地避免了灾难性遗忘问题。
关键设计:ACT-LoRA模型在ACT模型的基础上,引入了低秩自适应(LoRA)方法,通过训练少量参数来适应新技能,从而减少了计算量和存储空间。技能对齐模型采用对比学习方法,将语言指令和机器人技能的嵌入向量对齐,从而使机器人能够理解用户的意图。LLM采用预训练的语言模型,并根据具体的任务进行微调。
🖼️ 关键图片

📊 实验亮点
ACT-LoRA模型仅用五个新技能的演示进行训练,即可达到100%的准确率,同时在RLBench数据集的预训练技能上保持74.75%的准确率,显著优于其他模型。在真实机器人三明治制作任务中,该框架实现了75%的成功率,证明了其在实际应用中的有效性。
🎯 应用场景
该研究成果可应用于各种需要人机协作的机器人应用场景,例如:家庭服务机器人、工业机器人、医疗机器人等。通过与人类用户的自然语言交互,机器人可以快速学习新技能,适应不同的任务需求,提高工作效率和服务质量。此外,该研究也有助于推动机器人自主学习和智能化的发展。
📄 摘要(原文)
Continual and interactive robot learning is a challenging problem as the robot is present with human users who expect the robot to learn novel skills to solve novel tasks perpetually with sample efficiency. In this work we present a framework for robots to query and learn visuo-motor robot skills and task relevant information via natural language dialog interactions with human users. Previous approaches either focus on improving the performance of instruction following agents, or passively learn novel skills or concepts. Instead, we used dialog combined with a language-skill grounding embedding to query or confirm skills and/or tasks requested by a user. To achieve this goal, we developed and integrated three different components for our agent. Firstly, we propose a novel visual-motor control policy ACT with Low Rank Adaptation (ACT-LoRA), which enables the existing SoTA ACT model to perform few-shot continual learning. Secondly, we develop an alignment model that projects demonstrations across skill embodiments into a shared embedding allowing us to know when to ask questions and/or demonstrations from users. Finally, we integrated an existing LLM to interact with a human user to perform grounded interactive continual skill learning to solve a task. Our ACT-LoRA model learns novel fine-tuned skills with a 100% accuracy when trained with only five demonstrations for a novel skill while still maintaining a 74.75% accuracy on pre-trained skills in the RLBench dataset where other models fall significantly short. We also performed a human-subjects study with 8 subjects to demonstrate the continual learning capabilities of our combined framework. We achieve a success rate of 75% in the task of sandwich making with the real robot learning from participant data demonstrating that robots can learn novel skills or task knowledge from dialogue with non-expert users using our approach.