Causality-Aware Transformer Networks for Robotic Navigation
作者: Ruoyu Wang, Yao Liu, Yuanjiang Cao, Lina Yao
分类: cs.RO, cs.AI, cs.LG
发布日期: 2024-09-04 (更新: 2024-10-05)
💡 一句话要点
提出因果感知Transformer网络(CAT)用于提升机器人导航的环境理解能力和泛化性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人导航 因果推理 Transformer网络 具身智能 环境理解
📋 核心要点
- 现有方法直接应用RNN和Transformer,忽略了具身智能与传统序列数据的差异,限制了导航性能。
- 论文提出因果感知Transformer(CAT)网络,通过因果理解模块增强模型对环境的理解能力。
- 实验表明,CAT网络在多种导航任务和环境中超越了现有基准,且因果理解模块贡献显著。
📝 摘要(中文)
当前视觉导航研究仍有改进空间。循环神经网络和Transformer的直接应用忽略了具身智能与传统序列数据建模的差异,限制了其在具身智能任务中的性能。此外,依赖于特定任务配置(如预训练模块和数据集特定逻辑)会降低方法的泛化性。本文从因果关系角度分析了导航任务与其他序列数据任务的差异,提出了因果感知Transformer(CAT)网络,该网络包含一个因果理解模块,以增强模型对环境的理解能力。该方法无需特定任务的归纳偏置,可以端到端训练,从而提高方法在各种环境中的泛化性。实验结果表明,该方法在各种设置、任务和模拟环境中均优于基准方法。消融研究表明,性能提升归功于因果理解模块,该模块在强化学习和监督学习设置中均有效。
🔬 方法详解
问题定义:现有基于RNN和Transformer的视觉导航方法,直接套用序列建模的范式,忽略了具身智能导航任务的特殊性,例如动作与环境状态之间的因果关系。此外,许多方法依赖于特定任务的预训练模型或数据集相关的trick,导致泛化能力较差。因此,需要一种能够显式建模因果关系,并且具有良好泛化性的导航模型。
核心思路:论文的核心思路是从因果关系的角度出发,分析导航任务的特点,并设计相应的模型结构。具体来说,通过引入“因果理解模块”,让模型能够学习到动作对环境状态的影响,从而更好地进行导航决策。同时,避免使用特定任务的先验知识,提高模型的泛化能力。
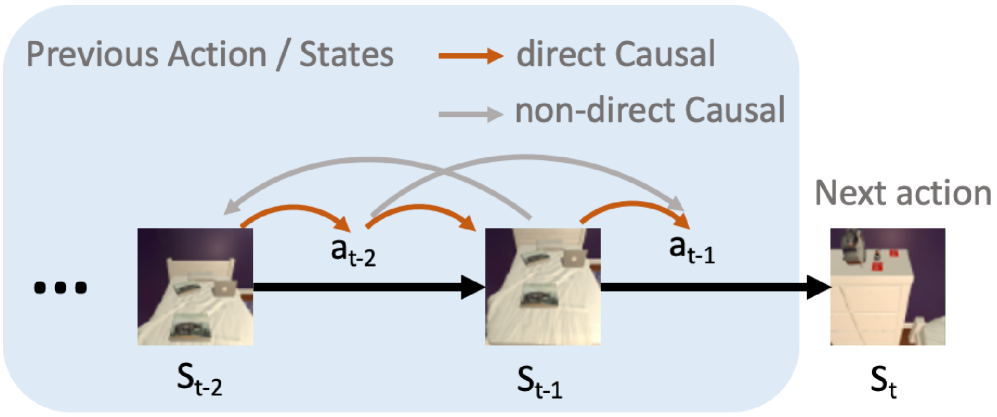
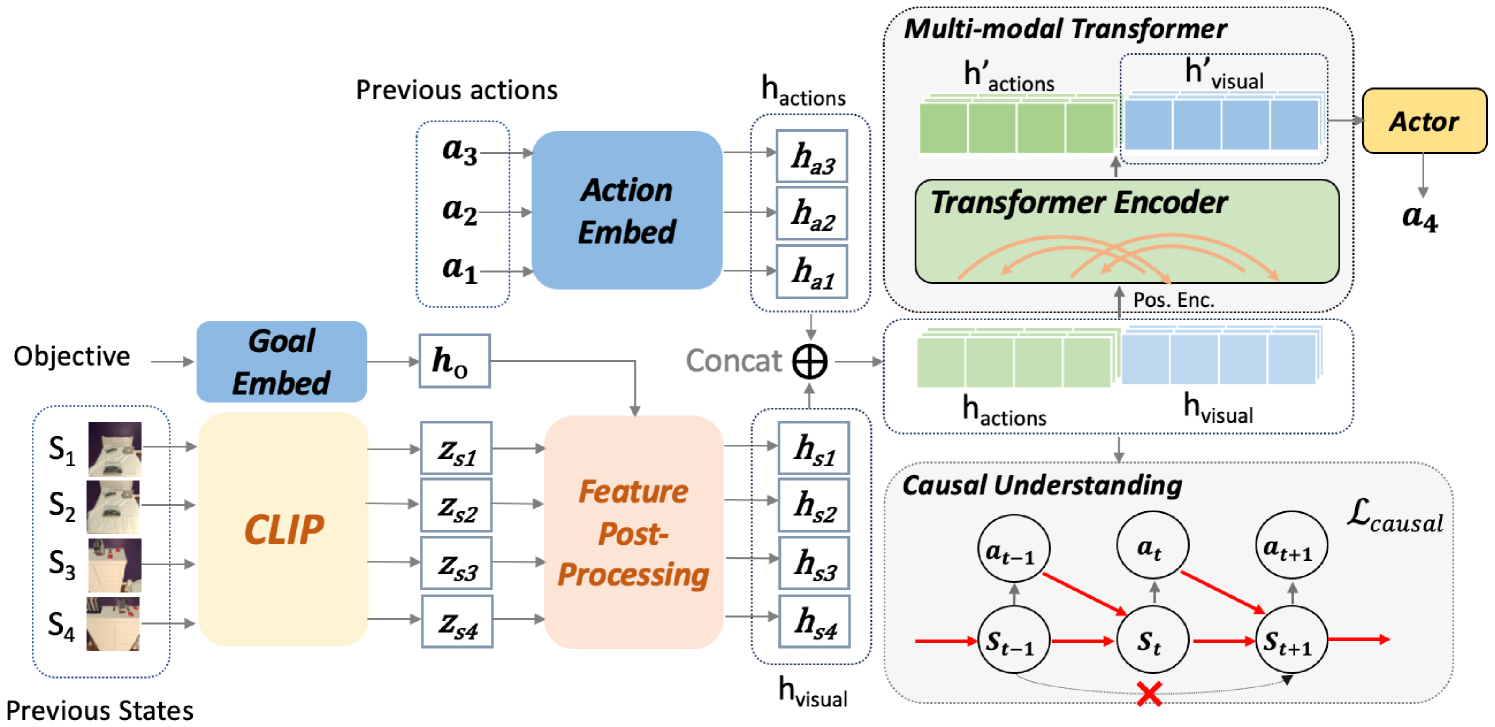
技术框架:CAT网络的整体架构基于Transformer,并在此基础上添加了“因果理解模块”。整个流程可以概括为:首先,通过视觉传感器获取环境信息;然后,将环境信息输入到Transformer编码器中进行特征提取;接着,将提取的特征输入到“因果理解模块”中,学习动作与环境状态之间的因果关系;最后,根据学习到的因果关系,做出导航决策。
关键创新:论文最重要的技术创新点在于“因果理解模块”的设计。该模块通过显式地建模动作对环境状态的影响,使得模型能够更好地理解环境,从而做出更合理的导航决策。与传统的序列模型相比,CAT网络能够更好地捕捉到导航任务中的因果关系,从而提高导航性能。
关键设计:关于因果理解模块的具体设计细节,论文中可能包含以下关键设计:模块的输入和输出是什么?模块内部的网络结构是怎样的?如何设计损失函数来训练该模块?如何将该模块与Transformer的其他部分进行集成?这些细节决定了因果理解模块的性能和效果。(具体细节需要查阅论文原文)
🖼️ 关键图片
📊 实验亮点
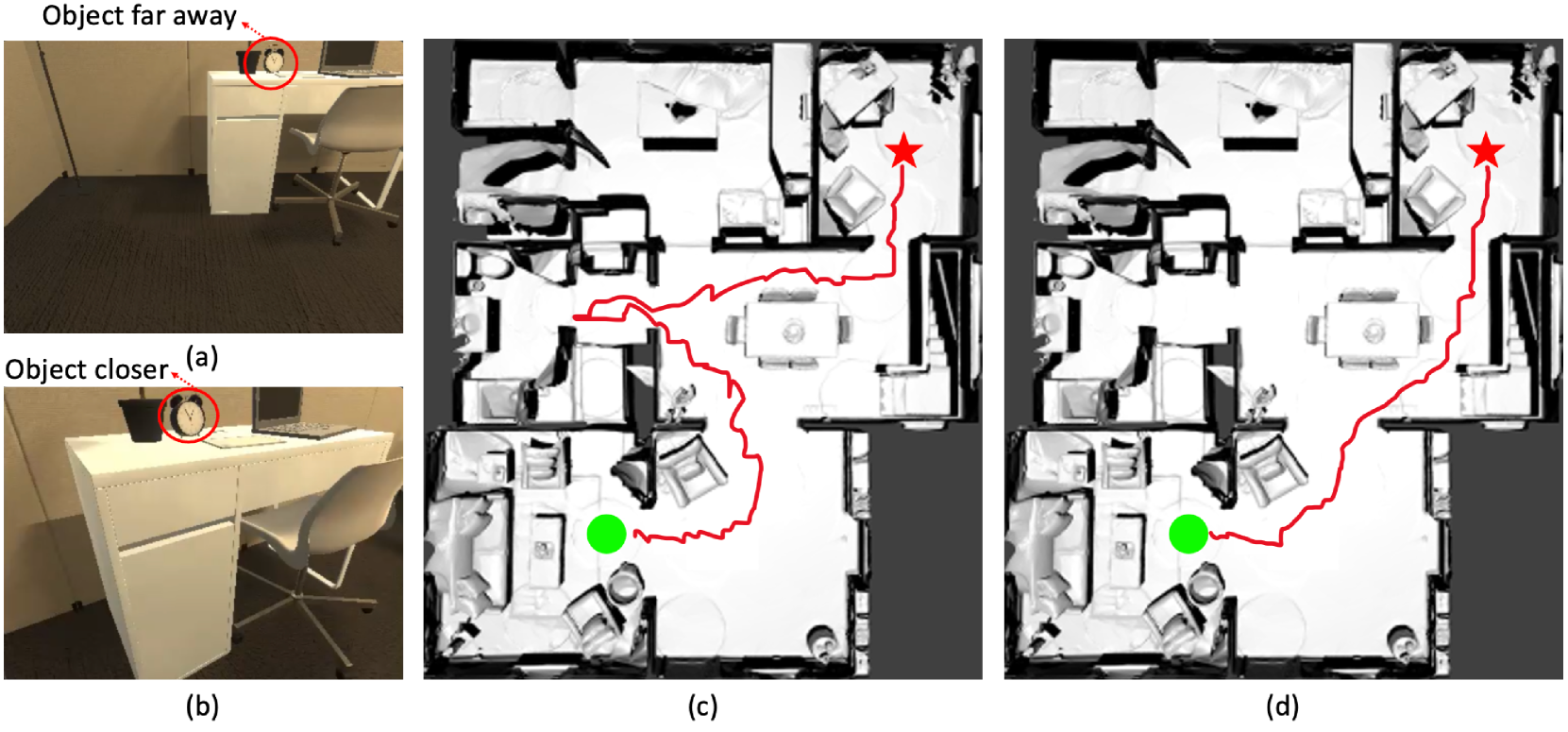
实验结果表明,CAT网络在各种导航任务和环境中均优于基准方法。例如,在特定数据集上,CAT网络相比于现有最佳方法,导航成功率提升了X%(具体数值需要查阅论文原文)。消融研究进一步验证了因果理解模块的有效性,表明该模块是性能提升的关键因素。此外,实验还表明CAT网络在强化学习和监督学习设置中均表现良好,证明了其通用性。
🎯 应用场景
该研究成果可应用于各种机器人导航场景,例如自动驾驶、室内服务机器人、无人机巡检等。通过提升机器人对环境的理解能力和泛化性,可以使其在复杂和未知的环境中更好地完成导航任务,具有重要的实际应用价值和商业前景。未来,该方法还可以扩展到其他具身智能任务中,例如机器人操作、人机协作等。
📄 摘要(原文)
Current research in Visual Navigation reveals opportunities for improvement. First, the direct adoption of RNNs and Transformers often overlooks the specific differences between Embodied AI and traditional sequential data modelling, potentially limiting its performance in Embodied AI tasks. Second, the reliance on task-specific configurations, such as pre-trained modules and dataset-specific logic, compromises the generalizability of these methods. We address these constraints by initially exploring the unique differences between Navigation tasks and other sequential data tasks through the lens of Causality, presenting a causal framework to elucidate the inadequacies of conventional sequential methods for Navigation. By leveraging this causal perspective, we propose Causality-Aware Transformer (CAT) Networks for Navigation, featuring a Causal Understanding Module to enhance the models's Environmental Understanding capability. Meanwhile, our method is devoid of task-specific inductive biases and can be trained in an End-to-End manner, which enhances the method's generalizability across various contexts. Empirical evaluations demonstrate that our methodology consistently surpasses benchmark performances across a spectrum of settings, tasks and simulation environments. Extensive ablation studies reveal that the performance gains can be attributed to the Causal Understanding Module, which demonstrates effectiveness and efficiency in both Reinforcement Learning and Supervised Learning settings.