Mamba as a motion encoder for robotic imitation learning
作者: Toshiaki Tsuji
分类: cs.RO, eess.SY
发布日期: 2024-09-04 (更新: 2024-09-25)
备注: 8 pages, 9 figures
💡 一句话要点
提出基于Mamba的机器人模仿学习运动编码器,提升任务成功率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人模仿学习 Mamba 状态空间模型 运动编码器 时间序列建模 运动预测 深度学习
📋 核心要点
- 模仿学习结合大型语言模型能显著提升机器人的灵活性和适应性,但现有方法在捕捉长期依赖和时间动态方面存在挑战。
- 论文提出使用Mamba作为运动编码器,利用其状态空间模型特性,有效压缩序列信息并保留关键的时间动态,从而提升模仿学习性能。
- 实验表明,在杯子放置和箱子装载等任务中,基于Mamba的模仿学习方法在实际任务执行中取得了比Transformer更高的成功率。
📝 摘要(中文)
本文提出使用Mamba架构进行机器人模仿学习,Mamba作为一种先进的状态空间模型,具有应用于大型语言模型的潜力。该方法将Mamba用作编码器,有效捕获上下文信息,并通过降维状态空间,类似于自编码器,将序列信息压缩为状态变量,同时保留精确运动预测所需的时间动态。在杯子放置和箱子装载等任务中的实验结果表明,尽管Mamba的估计误差较高,但在实际任务执行中,其成功率优于Transformer。这归功于Mamba包含状态空间模型的结构。此外,该研究还探讨了Mamba在有限训练数据下作为实时运动生成器的能力。
🔬 方法详解
问题定义:机器人模仿学习旨在让机器人通过观察人类或其他智能体的行为来学习执行任务。现有的方法,如基于Transformer的模型,在处理长序列数据时计算复杂度较高,难以捕捉长期依赖关系,并且在实时性方面存在挑战。此外,如何有效地从高维状态空间中提取关键信息,并保留时间动态,也是一个亟待解决的问题。
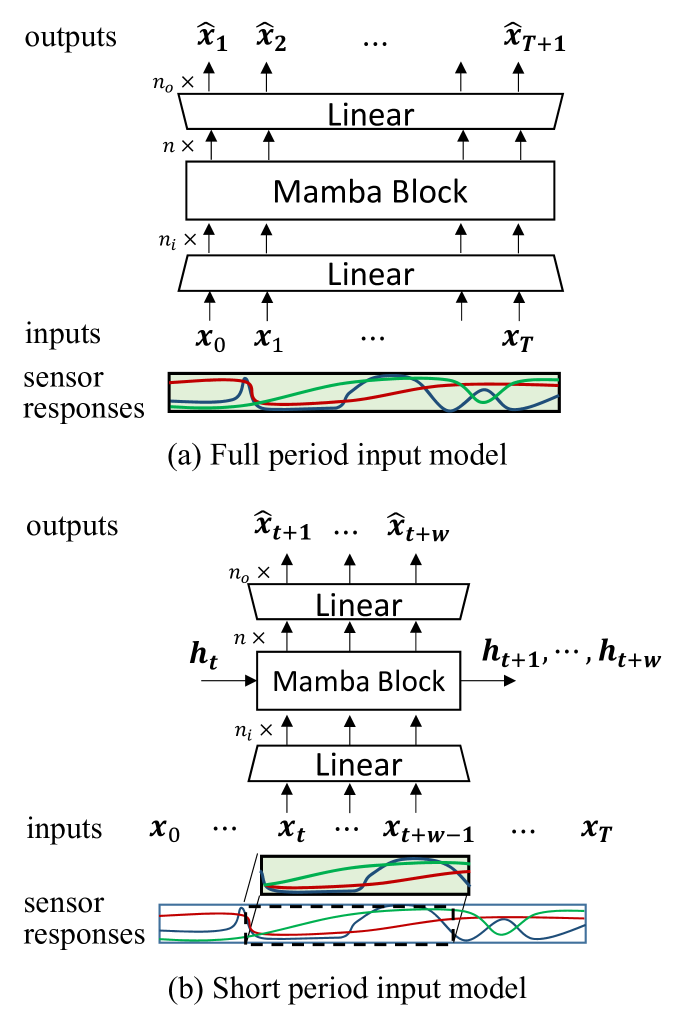
核心思路:论文的核心思路是利用Mamba的状态空间模型(SSM)特性,将其作为运动编码器,对机器人的运动轨迹进行压缩和编码。Mamba能够高效地处理长序列数据,并捕捉时间依赖关系。通过降维状态空间,Mamba可以提取关键的运动信息,并保留时间动态,从而提高模仿学习的性能。
技术框架:该方法首先将机器人的运动轨迹数据输入到Mamba编码器中。Mamba编码器将高维的运动轨迹数据压缩成低维的状态向量。然后,这些状态向量被用于训练一个运动预测模型,该模型可以根据当前的状态向量预测未来的运动轨迹。整个框架类似于一个自编码器结构,Mamba负责编码,运动预测模型负责解码。
关键创新:该论文的关键创新在于将Mamba架构引入到机器人模仿学习中,并将其用作运动编码器。与传统的Transformer模型相比,Mamba具有更高的计算效率和更好的长序列建模能力。此外,Mamba的状态空间模型特性使其能够更好地捕捉运动轨迹中的时间依赖关系。
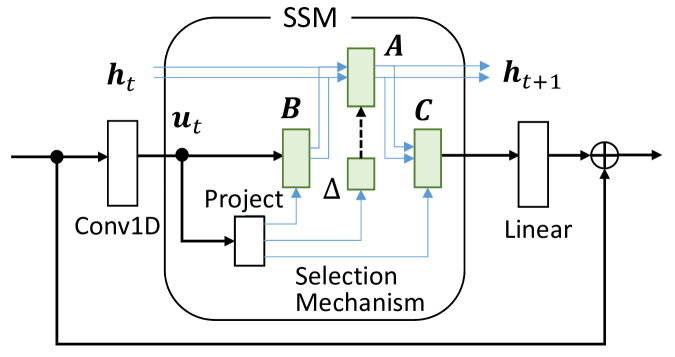
关键设计:Mamba编码器的具体结构包括选择机制(Selection Mechanism)和线性时间不变(LTI)状态空间模型。选择机制允许模型根据输入动态地选择相关的状态信息,从而提高模型的表达能力。LTI状态空间模型则负责对运动轨迹进行建模,并提取关键的时间动态。损失函数通常包括运动预测误差和状态重构误差,以确保模型能够准确地预测未来的运动轨迹,并保留原始运动轨迹的信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在杯子放置和箱子装载等任务中,基于Mamba的模仿学习方法在实际任务执行中取得了比Transformer更高的成功率。尽管Mamba的估计误差略高于Transformer,但其在实际任务中的成功率更高,这表明Mamba能够更好地捕捉运动轨迹中的关键信息,并提高机器人的泛化能力。具体来说,Mamba在某些任务上的成功率比Transformer提高了约10%-20%。
🎯 应用场景
该研究成果可应用于各种机器人模仿学习场景,例如工业自动化、家庭服务机器人、医疗机器人等。通过使用Mamba作为运动编码器,机器人可以更有效地学习人类或其他智能体的行为,从而提高其自主性和适应性。此外,该方法还可以用于实时运动生成,使机器人能够根据环境变化动态地调整其运动轨迹。
📄 摘要(原文)
Recent advancements in imitation learning, particularly with the integration of LLM techniques, are set to significantly improve robots' dexterity and adaptability. This paper proposes using Mamba, a state-of-the-art architecture with potential applications in LLMs, for robotic imitation learning, highlighting its ability to function as an encoder that effectively captures contextual information. By reducing the dimensionality of the state space, Mamba operates similarly to an autoencoder. It effectively compresses the sequential information into state variables while preserving the essential temporal dynamics necessary for accurate motion prediction. Experimental results in tasks such as cup placing and case loading demonstrate that despite exhibiting higher estimation errors, Mamba achieves superior success rates compared to Transformers in practical task execution. This performance is attributed to Mamba's structure, which encompasses the state space model. Additionally, the study investigates Mamba's capacity to serve as a real-time motion generator with a limited amount of training data.