AeroVerse: UAV-Agent Benchmark Suite for Simulating, Pre-training, Finetuning, and Evaluating Aerospace Embodied World Models
作者: Fanglong Yao, Yuanchang Yue, Youzhi Liu, Xian Sun, Kun Fu
分类: cs.RO, cs.AI
发布日期: 2024-08-28 (更新: 2025-11-20)
💡 一句话要点
AeroVerse:用于模拟、预训练、微调和评估航空航天具身世界模型的无人机代理基准套件
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 无人机 具身智能 世界模型 视觉语言模型 预训练 基准套件 数据集 航空航天
📋 核心要点
- 现有具身世界模型主要集中于地面智能体,缺乏对无人机智能体的研究,限制了航空航天具身智能的发展。
- 论文构建了大规模真实和虚拟数据集,并定义了五个下游任务,用于预训练和微调航空航天具身世界模型。
- 通过SkyAgentEval评估指标,全面评估了2D/3D视觉语言模型在无人机任务中的表现,并集成了AeroVerse基准套件。
📝 摘要(中文)
航空航天具身智能旨在使无人机和其他航空航天平台能够实现自主感知、认知和行动,以及与人类和环境的以自我为中心的积极互动。航空航天具身世界模型是实现无人机自主智能的有效手段,也是通往航空航天具身智能的必要途径。然而,现有的具身世界模型主要关注室内场景中的地面智能代理,而对无人机智能代理的研究仍未被探索。为了弥补这一差距,我们构建了第一个大规模的真实世界图像-文本预训练数据集AerialAgent-Ego10k,以第一人称视角呈现城市无人机。我们还创建了一个虚拟图像-文本-姿态对齐数据集CyberAgent Ego500k,以促进航空航天具身世界模型的预训练。我们首次明确定义了5个下游任务,即航空航天具身场景感知、空间推理、导航探索、任务规划和运动决策,并构建了相应的指令数据集,即SkyAgent-Scene3k、SkyAgent-Reason3k、SkyAgent-Nav3k、SkyAgent-Plan3k和SkyAgent-Act3k,用于微调航空航天具身世界模型。同时,我们开发了基于GPT-4的下游任务评估指标SkyAgentEval,以全面、灵活和客观地评估结果,揭示了2D/3D视觉语言模型在无人机代理任务中的潜力和局限性。此外,我们将10多个2D/3D视觉语言模型、2个预训练数据集、5个微调数据集、10多个评估指标和一个模拟器集成到基准套件AeroVerse中,该套件将向社区发布,以促进航空航天具身智能的探索和发展。
🔬 方法详解
问题定义:现有具身世界模型的研究主要集中在地面机器人和室内环境,缺乏针对无人机等航空航天平台的具身智能研究。这导致无人机在复杂环境中的自主感知、认知和行动能力不足,无法有效完成导航、探索和任务规划等任务。现有方法难以适应无人机视角下的场景理解和空间推理需求。
核心思路:论文的核心思路是构建一个全面的航空航天具身智能基准套件AeroVerse,包括大规模数据集、下游任务定义、评估指标和集成模型。通过提供预训练和微调的数据集,以及标准化的评估流程,促进无人机具身世界模型的研究和发展。该方法旨在弥合地面机器人和无人机智能体之间的差距,推动航空航天领域的自主智能发展。
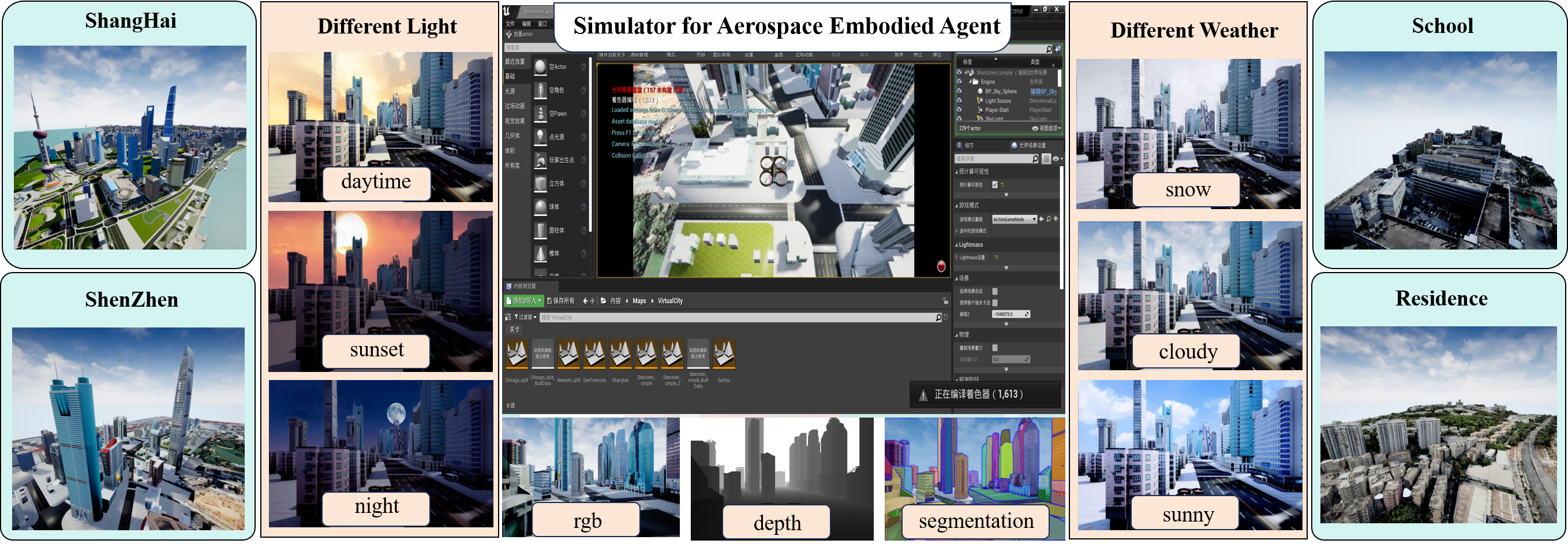
技术框架:AeroVerse基准套件主要包含以下几个模块:1) 大规模预训练数据集:AerialAgent-Ego10k(真实世界图像-文本数据)和CyberAgent Ego500k(虚拟图像-文本-姿态数据)。2) 五个下游任务定义:航空航天具身场景感知、空间推理、导航探索、任务规划和运动决策。3) 相应的指令数据集:SkyAgent-Scene3k、SkyAgent-Reason3k、SkyAgent-Nav3k、SkyAgent-Plan3k和SkyAgent-Act3k。4) 基于GPT-4的下游任务评估指标:SkyAgentEval。5) 集成多种2D/3D视觉语言模型和模拟器。
关键创新:该论文的关键创新在于:1) 首次针对无人机具身智能构建了大规模的真实和虚拟数据集,填补了该领域的空白。2) 明确定义了五个无人机具身智能的下游任务,并构建了相应的指令数据集,为模型微调提供了标准。3) 开发了基于GPT-4的评估指标SkyAgentEval,能够全面、灵活和客观地评估模型性能。4) 集成了AeroVerse基准套件,方便研究人员进行模型训练、评估和比较。
关键设计:AerialAgent-Ego10k数据集包含从第一人称视角拍摄的城市无人机图像和文本描述。CyberAgent Ego500k数据集包含虚拟环境中的图像、文本和姿态信息,用于预训练模型的视觉-语言-姿态对齐能力。SkyAgentEval评估指标利用GPT-4的强大语言理解能力,对模型的输出进行语义分析和逻辑推理,从而评估其在下游任务中的表现。具体参数设置和网络结构取决于所使用的2D/3D视觉语言模型,论文提供了多种模型的集成。
🖼️ 关键图片


📊 实验亮点
论文构建的AeroVerse基准套件,集成了超过10个2D/3D视觉语言模型,并提供了5个下游任务的评估。通过SkyAgentEval评估,揭示了现有视觉语言模型在无人机任务中的潜力和局限性。例如,实验结果表明,某些模型在场景感知任务中表现良好,但在空间推理和任务规划方面仍有提升空间。
🎯 应用场景
该研究成果可广泛应用于无人机自主导航、环境感知、目标识别、任务规划和人机交互等领域。例如,可用于城市环境下的无人机配送、智能安防、灾害救援和基础设施巡检等任务。通过提升无人机的自主智能水平,可以降低人工成本,提高工作效率,并拓展无人机的应用范围。
📄 摘要(原文)
Aerospace embodied intelligence aims to empower unmanned aerial vehicles (UAVs) and other aerospace platforms to achieve autonomous perception, cognition, and action, as well as egocentric active interaction with humans and the environment. The aerospace embodied world model serves as an effective means to realize the autonomous intelligence of UAVs and represents a necessary pathway toward aerospace embodied intelligence. However, existing embodied world models primarily focus on ground-level intelligent agents in indoor scenarios, while research on UAV intelligent agents remains unexplored. To address this gap, we construct the first large-scale real-world image-text pre-training dataset, AerialAgent-Ego10k, featuring urban drones from a first-person perspective. We also create a virtual image-text-pose alignment dataset, CyberAgent Ego500k, to facilitate the pre-training of the aerospace embodied world model. For the first time, we clearly define 5 downstream tasks, i.e., aerospace embodied scene awareness, spatial reasoning, navigational exploration, task planning, and motion decision, and construct corresponding instruction datasets, i.e., SkyAgent-Scene3k, SkyAgent-Reason3k, SkyAgent-Nav3k and SkyAgent-Plan3k, and SkyAgent-Act3k, for fine-tuning the aerospace embodiment world model. Simultaneously, we develop SkyAgentEval, the downstream task evaluation metrics based on GPT-4, to comprehensively, flexibly, and objectively assess the results, revealing the potential and limitations of 2D/3D visual language models in UAV-agent tasks. Furthermore, we integrate over 10 2D/3D visual-language models, 2 pre-training datasets, 5 finetuning datasets, more than 10 evaluation metrics, and a simulator into the benchmark suite, i.e., AeroVerse, which will be released to the community to promote exploration and development of aerospace embodied intelligence.