Bridging the gap between Learning-to-plan, Motion Primitives and Safe Reinforcement Learning
作者: Piotr Kicki, Davide Tateo, Puze Liu, Jonas Guenster, Jan Peters, Krzysztof Walas
分类: cs.RO, cs.LG
发布日期: 2024-08-26
💡 一句话要点
结合学习规划、运动原语和安全强化学习,解决机器人复杂动力学约束下的轨迹规划问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 学习规划 运动原语 安全强化学习 轨迹规划 机器人控制
📋 核心要点
- 现有学习规划方法依赖于精确的机器人和任务建模,这在复杂系统或任务模型构建困难时受限。
- 该论文提出一种新方法,结合学习规划和强化学习,集成运动原语的黑盒学习和优化。
- 实验表明,该方法在机器人空气曲棍球等复杂场景中,优于现有的安全强化学习方法,尤其是在利用任务结构时。
📝 摘要(中文)
在复杂的环境中,对于需要灵巧、快速和反应能力的机器人应用来说,满足运动学约束的轨迹规划至关重要。这些约束,包括任务、安全或执行器限制,对于确保机器人平台的正常运行和防止意外行为至关重要。虽然最近在运动学规划方面的进展表明,学习规划技术可以在复杂的约束下生成复杂的和反应性的运动,但这些技术需要对机器人和整个任务进行分析建模,当系统极其复杂或构建精确的任务模型成本过高时,这是一个限制性假设。本文通过将学习规划方法与强化学习相结合来解决这一局限性,从而实现了运动原语的黑盒学习和优化的新颖集成。我们针对最先进的安全强化学习方法评估了我们的方法,结果表明,我们的技术,特别是在利用任务结构时,在诸如机器人空气曲棍球击球等具有挑战性的场景中优于基线方法。这项工作证明了我们的集成方法在提高在复杂运动学约束下运行的机器人的性能和安全性方面的潜力。
🔬 方法详解
问题定义:论文旨在解决在复杂动力学约束下,机器人轨迹规划的问题。现有学习规划方法需要对机器人和任务进行精确的解析建模,这在系统复杂或任务模型难以构建时变得不可行。此外,如何保证规划过程的安全性也是一个挑战。
核心思路:论文的核心思路是将学习规划(Learning-to-Plan)方法与强化学习(Reinforcement Learning)相结合。学习规划负责生成满足运动学约束的轨迹,而强化学习则用于学习运动原语,从而避免了对机器人和任务的精确建模。通过这种结合,可以在保证安全性的前提下,实现高效的轨迹规划。
技术框架:整体框架包含以下几个主要模块:1) 运动原语学习模块:使用强化学习方法,学习一系列运动原语,这些原语可以视为机器人可以执行的基本动作。2) 学习规划模块:利用学习到的运动原语,结合任务目标和约束,生成轨迹。3) 安全保障模块:采用安全强化学习方法,确保在规划和执行过程中,机器人不会违反安全约束。整个流程是,首先通过强化学习学习运动原语,然后利用学习规划模块,结合运动原语和任务目标,生成轨迹,最后通过安全保障模块,确保轨迹的安全性。
关键创新:论文的关键创新在于将学习规划和强化学习相结合,从而避免了对机器人和任务的精确建模。这种结合使得该方法可以应用于更复杂的系统和任务。此外,论文还提出了一种利用任务结构的方法,进一步提高了规划的效率和安全性。
关键设计:论文中,运动原语的学习采用了一种基于策略梯度的强化学习算法。安全保障模块采用了一种基于 Lyapunov 函数的安全强化学习方法。在学习规划模块中,采用了一种基于优化的方法,通过优化轨迹的代价函数,生成满足约束的轨迹。代价函数的设计考虑了任务目标、运动平滑性和安全性等因素。
🖼️ 关键图片

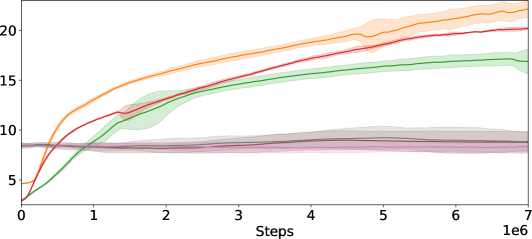

📊 实验亮点
论文在机器人空气曲棍球场景中进行了实验,结果表明,该方法在击球成功率和安全性方面均优于现有的安全强化学习方法。特别是在利用任务结构时,该方法的性能提升更为显著。实验结果验证了该方法在复杂动力学约束下的轨迹规划能力。
🎯 应用场景
该研究成果可应用于各种需要复杂运动规划的机器人应用,例如:自主导航、工业自动化、医疗机器人、以及人机协作等领域。通过学习运动原语和结合安全强化学习,可以使机器人在复杂环境中更安全、更高效地完成任务,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Trajectory planning under kinodynamic constraints is fundamental for advanced robotics applications that require dexterous, reactive, and rapid skills in complex environments. These constraints, which may represent task, safety, or actuator limitations, are essential for ensuring the proper functioning of robotic platforms and preventing unexpected behaviors. Recent advances in kinodynamic planning demonstrate that learning-to-plan techniques can generate complex and reactive motions under intricate constraints. However, these techniques necessitate the analytical modeling of both the robot and the entire task, a limiting assumption when systems are extremely complex or when constructing accurate task models is prohibitive. This paper addresses this limitation by combining learning-to-plan methods with reinforcement learning, resulting in a novel integration of black-box learning of motion primitives and optimization. We evaluate our approach against state-of-the-art safe reinforcement learning methods, showing that our technique, particularly when exploiting task structure, outperforms baseline methods in challenging scenarios such as planning to hit in robot air hockey. This work demonstrates the potential of our integrated approach to enhance the performance and safety of robots operating under complex kinodynamic constraints.