cc-DRL: a Convex Combined Deep Reinforcement Learning Flight Control Design for a Morphing Quadrotor
作者: Tao Yang, Huai-Ning Wu, Jun-Wei Wang
分类: cs.RO, cs.AI, cs.LG, eess.SY
发布日期: 2024-08-23
💡 一句话要点
提出基于凸组合深度强化学习的变体四旋翼飞行控制算法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 变体四旋翼 深度强化学习 凸组合 飞行控制 无模型控制
📋 核心要点
- 变体四旋翼飞行控制面临挑战,其复杂动力学难以建模,传统控制方法难以适用。
- 提出cc-DRL算法,结合无模型深度强化学习和凸组合技术,实现对变体四旋翼的有效控制。
- 通过仿真验证了cc-DRL算法的有效性,表明其能够应对变体四旋翼的复杂飞行控制问题。
📝 摘要(中文)
与普通四旋翼相比,变体四旋翼的形状改变使其具有更好的飞行性能,但也导致了更复杂的飞行动力学。通常,变体四旋翼很难甚至不可能建立精确的数学模型来描述其复杂的飞行动力学。为了解决变体四旋翼的飞行控制设计问题,本文采用无模型控制技术(例如,深度强化学习,DRL)和凸组合(CC)技术相结合的方法,提出了一种凸组合深度强化学习(cc-DRL)飞行控制算法,用于一类通过改变四个臂杆长度来实现形状变化的变体四旋翼的位置和姿态控制。在所提出的cc-DRL飞行控制算法中,利用近端策略优化算法(一种无模型DRL算法)离线训练一些选定的代表性臂长模式对应的最优飞行控制律,从而通过凸组合技术构建cc-DRL飞行控制方案。最后,仿真结果表明了所提出的飞行控制算法的有效性和优点。
🔬 方法详解
问题定义:针对变体四旋翼飞行控制问题,由于其形状变化导致飞行动力学复杂且难以精确建模,传统的基于模型的控制方法难以有效控制。因此,需要一种能够适应复杂动力学且无需精确模型的控制方法。
核心思路:论文的核心思路是将无模型的深度强化学习(DRL)与凸组合(CC)技术相结合。首先,利用DRL学习不同臂长模式下的最优控制策略;然后,通过凸组合将这些策略组合起来,形成一个能够适应臂长变化的控制策略。这样,即使动力学模型未知,也能实现对变体四旋翼的有效控制。
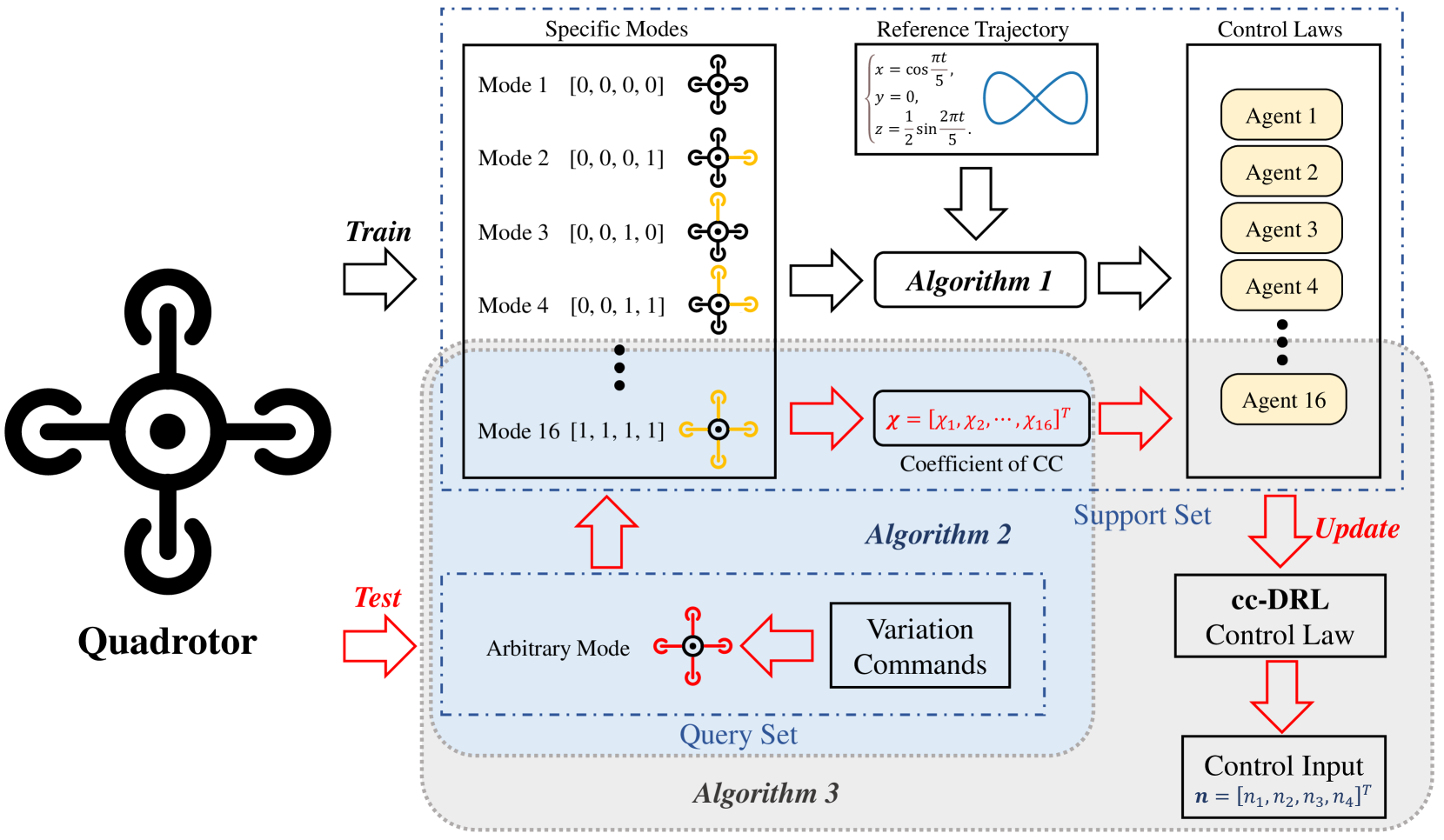
技术框架:cc-DRL飞行控制算法的整体框架如下:1) 选择若干具有代表性的臂长模式。2) 针对每种臂长模式,使用近端策略优化(PPO)算法离线训练一个最优飞行控制律。3) 使用凸组合技术,将这些针对不同臂长模式训练得到的控制律组合成一个统一的控制策略。该策略能够根据当前的臂长,自适应地调整控制参数,从而实现对变体四旋翼的控制。
关键创新:该方法最重要的创新点在于将深度强化学习与凸组合技术相结合,从而在无需精确动力学模型的情况下,实现了对变体四旋翼的有效控制。与传统的基于模型的控制方法相比,该方法不需要进行复杂的建模过程,并且能够更好地适应变体四旋翼的复杂动力学。
关键设计:在算法设计中,选择了近端策略优化(PPO)作为DRL算法,因为它具有较好的稳定性和收敛性。臂长模式的选择需要具有代表性,能够覆盖变体四旋翼的整个工作范围。凸组合的权重需要根据当前的臂长进行调整,以保证控制策略的平滑过渡。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过仿真实验验证了所提出的cc-DRL飞行控制算法的有效性。虽然论文中没有给出具体的性能数据和对比基线,但仿真结果表明,该算法能够实现对变体四旋翼的位置和姿态的稳定控制,证明了该方法的可行性。
🎯 应用场景
该研究成果可应用于需要灵活机动的飞行机器人领域,例如搜救、侦察和环境监测等。变体四旋翼能够根据任务需求改变自身形状,从而适应不同的环境和任务要求。该研究为变体飞行器的控制提供了一种有效的解决方案,具有重要的实际应用价值和潜在的未来影响。
📄 摘要(原文)
In comparison to common quadrotors, the shape change of morphing quadrotors endows it with a more better flight performance but also results in more complex flight dynamics. Generally, it is extremely difficult or even impossible for morphing quadrotors to establish an accurate mathematical model describing their complex flight dynamics. To figure out the issue of flight control design for morphing quadrotors, this paper resorts to a combination of model-free control techniques (e.g., deep reinforcement learning, DRL) and convex combination (CC) technique, and proposes a convex-combined-DRL (cc-DRL) flight control algorithm for position and attitude of a class of morphing quadrotors, where the shape change is realized by the length variation of four arm rods. In the proposed cc-DRL flight control algorithm, proximal policy optimization algorithm that is a model-free DRL algorithm is utilized to off-line train the corresponding optimal flight control laws for some selected representative arm length modes and hereby a cc-DRL flight control scheme is constructed by the convex combination technique. Finally, simulation results are presented to show the effectiveness and merit of the proposed flight control algorithm.