Online state vector reduction during model predictive control with gradient-based trajectory optimisation
作者: David Russell, Rafael Papallas, Mehmet Dogar
分类: cs.RO
发布日期: 2024-08-21 (更新: 2024-09-12)
备注: 18 pages, 4 figures, accepted to WAFR 2024
💡 一句话要点
提出基于梯度轨迹优化的在线状态向量降维MPC方法,加速高维非抓取操作。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 轨迹优化 状态向量降维 非抓取操作 高维系统
📋 核心要点
- 高维非抓取操作因状态空间巨大而面临计算瓶颈,现有轨迹优化方法难以有效扩展。
- 论文提出在线状态向量降维方法,根据任务演变动态调整自由度,降低规划复杂度。
- 实验结果表明,该方法在异步MPC下能有效减少策略滞后,提升整体操作性能。
📝 摘要(中文)
在高维系统中进行非抓取操作面临诸多挑战,其中之一是庞大的状态空间导致计算时间过长。轨迹优化算法在各种任务中都证明了其有效性,但与大多数方法一样,难以扩展到高维系统,这些系统在杂乱环境中的非抓取操作以及可变形物体操作中普遍存在。我们认为,在操作过程中,随着系统的演变,不同的自由度对于任务的重要性会发生变化。我们利用这一思想来减少轨迹优化问题中考虑的自由度数量,从而减少规划时间。这个想法在模型预测控制(MPC)的背景下尤其重要,因为优化问题的成本格局在不断变化。我们提供了异步MPC下的仿真结果,表明我们的方法能够实现更好的整体性能,这是由于减少了策略滞后,同时仍然能够有效地优化轨迹。
🔬 方法详解
问题定义:论文旨在解决高维系统中非抓取操作中,由于状态空间维度过高,导致轨迹优化算法计算时间过长的问题。现有方法难以有效扩展到此类高维系统,限制了其在复杂环境和可变形物体操作中的应用。现有方法的痛点在于无法根据任务的动态变化调整自由度的重要性,导致不必要的计算开销。
核心思路:论文的核心思路是,在操作过程中,不同的自由度对于任务的重要性会随着系统状态的演变而发生变化。因此,可以通过在线评估每个自由度的重要性,并动态地减少轨迹优化问题中考虑的自由度数量,从而降低计算复杂度,加速规划过程。
技术框架:该方法基于模型预测控制(MPC)框架,并结合梯度轨迹优化算法。整体流程如下:1. 初始化状态向量。2. 在每个MPC迭代步骤中,评估当前状态下各个自由度的重要性。3. 根据重要性排序,选择最重要的自由度子集。4. 使用梯度轨迹优化算法,在降维后的状态空间中优化轨迹。5. 将优化后的轨迹应用于系统。6. 重复步骤2-5,直到任务完成。该方法采用异步MPC,允许规划和执行并行进行,进一步降低策略滞后。
关键创新:最重要的技术创新点是提出了在线状态向量降维策略。与现有方法相比,该方法能够根据任务的动态变化自适应地调整状态空间维度,从而显著降低计算复杂度,提高规划效率。这种在线降维策略与传统的离线降维方法相比,更具灵活性和适应性。
关键设计:论文中未明确说明评估自由度重要性的具体方法,这部分是未知信息。但是,可以推测可能使用基于梯度或灵敏度分析的方法来评估每个自由度对目标函数的影响。损失函数的设计需要考虑任务的具体目标,例如最小化操作时间、最大化操作精度等。异步MPC的实现需要仔细设计通信机制,以确保规划和执行之间的同步。
🖼️ 关键图片
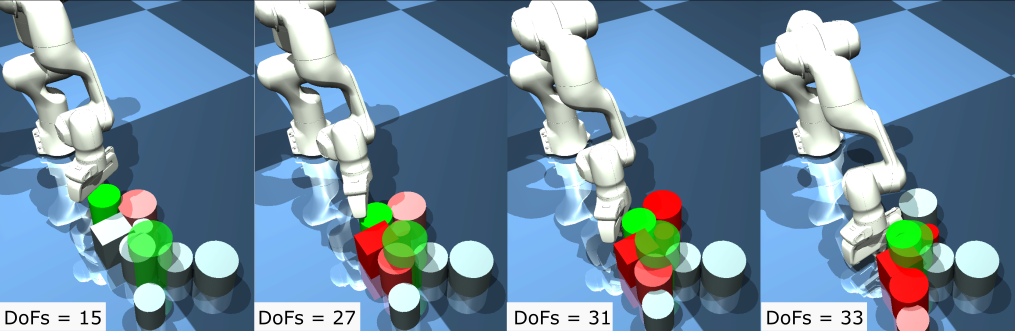


📊 实验亮点
论文通过仿真实验验证了所提出方法的有效性。实验结果表明,该方法在异步MPC下能够显著减少策略滞后,从而实现更好的整体操作性能。具体的性能数据和对比基线在摘要中没有明确给出,但强调了该方法在降低策略滞后方面的优势,这意味着更快的响应速度和更高的控制精度。
🎯 应用场景
该研究成果可应用于机器人非抓取操作、可变形物体操作、以及其他高维系统的控制问题。例如,在拥挤的仓库环境中,机器人可以通过该方法快速规划出操作路径,高效地完成物品的拣选和放置任务。此外,该方法还可以应用于医疗机器人手术,提高手术的精度和效率。未来,该方法有望推动高维复杂系统的智能化控制。
📄 摘要(原文)
Non-prehensile manipulation in high-dimensional systems is challenging for a variety of reasons. One of the main reasons is the computationally long planning times that come with a large state space. Trajectory optimisation algorithms have proved their utility in a wide variety of tasks, but, like most methods struggle scaling to the high dimensional systems ubiquitous to non-prehensile manipulation in clutter as well as deformable object manipulation. We reason that, during manipulation, different degrees of freedom will become more or less important to the task over time as the system evolves. We leverage this idea to reduce the number of degrees of freedom considered in a trajectory optimisation problem, to reduce planning times. This idea is particularly relevant in the context of model predictive control (MPC) where the cost landscape of the optimisation problem is constantly evolving. We provide simulation results under asynchronous MPC and show our methods are capable of achieving better overall performance due to the decreased policy lag whilst still being able to optimise trajectories effectively.