Bidirectional Intent Communication: A Role for Large Foundation Models
作者: Tim Schreiter, Rishi Hazra, Jens Rüppel, Andrey Rudenko
分类: cs.RO, cs.HC
发布日期: 2024-08-20
备注: 2024 33rd IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Workshop: Large Language Models in the RoMan Age
💡 一句话要点
Bident:面向人机协作的、基于大模型的双向意图沟通框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机交互 双向沟通 意图理解 多模态融合 大型基础模型 协作机器人 个性化教育 医疗保健
📋 核心要点
- 现有方法在人机交互中,主要以任务为中心,忽略了人类用户的意图和反馈,限制了协作效率。
- Bident框架通过整合多模态输入(语音、视线)和输出(语言、动作),实现双向意图沟通,提升人机协作体验。
- 论文重点在于框架设计,具体实验结果未知,但展示了在个性化教育和医疗保健领域的应用潜力。
📝 摘要(中文)
将多模态基础模型集成到自主代理中,显著增强了它们对语言的理解、感知和规划能力。然而,现有工作主要采用以任务为中心的策略,极少关注人机交互。本论文提出了“Bident”框架,旨在将机器人无缝集成到与人类共享的空间中。Bident通过整合语音和用户视线动态等多模态输入来增强交互体验。此外,Bident支持口头表达和手势等物理动作,使其能够灵活地进行双向人机交互。潜在的应用包括个性化教育(机器人可以适应个人学习风格和节奏)和医疗保健(机器人可以在家庭和工作环境中提供个性化的支持、陪伴和日常帮助)。
🔬 方法详解
问题定义:现有的人机交互系统通常以任务为中心,机器人主要执行预定义的任务,缺乏对人类意图的理解和响应,难以实现自然流畅的协作。现有方法的痛点在于缺乏双向沟通机制,无法根据人类的反馈动态调整行为。
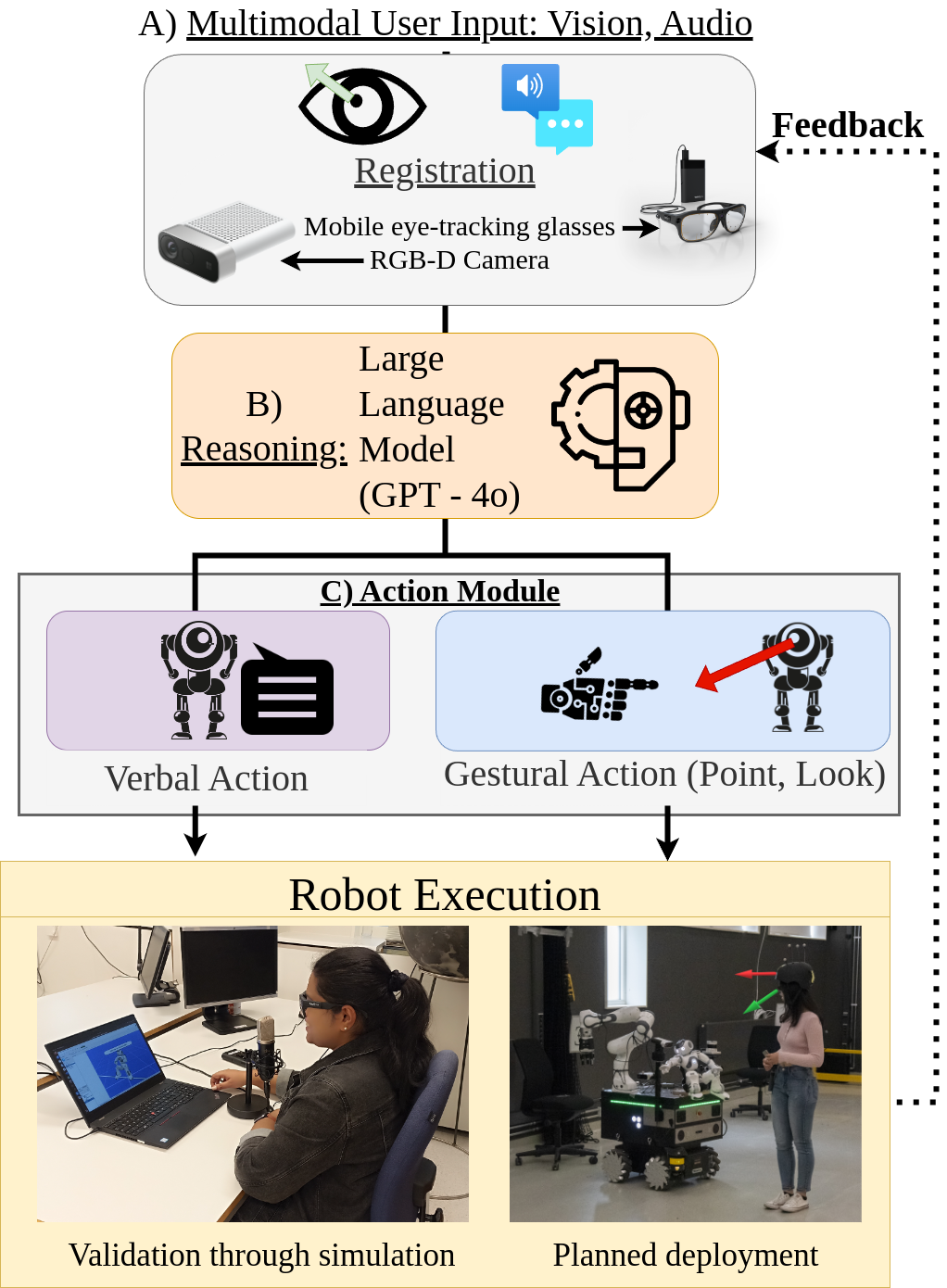
核心思路:Bident的核心思路是建立一个双向意图沟通渠道,使机器人能够理解人类的意图,并根据人类的反馈调整自身行为。通过整合多模态输入(如语音和视线)和输出(如语言和动作),实现更自然、更高效的人机交互。
技术框架:Bident框架包含以下主要模块:1) 多模态输入模块:负责接收和处理来自人类的语音、视线等信息。2) 意图理解模块:利用大型基础模型理解人类的意图。3) 行为规划模块:根据理解的意图规划机器人的行为。4) 多模态输出模块:负责将机器人的行为以语言、动作等形式表达出来。整个流程是一个循环迭代的过程,机器人不断接收人类的反馈,并根据反馈调整自身行为。
关键创新:Bident的关键创新在于其双向意图沟通机制。与传统的单向控制方式不同,Bident允许机器人和人类进行持续的交流和协作,从而实现更智能、更灵活的人机交互。此外,Bident框架利用大型基础模型进行意图理解,可以处理更复杂、更模糊的人类指令。
关键设计:论文中没有详细描述关键参数设置、损失函数、网络结构等技术细节。这些细节可能依赖于具体应用场景和所使用的大型基础模型。未来的研究可以进一步探索如何优化这些技术细节,以提高Bident框架的性能和鲁棒性。
🖼️ 关键图片

📊 实验亮点
由于论文侧重于框架设计,并未提供具体的实验结果。其亮点在于提出了一个新颖的双向意图沟通框架,并展示了其在个性化教育和医疗保健领域的潜在应用价值。未来的研究可以进一步验证该框架的有效性,并探索其在更多领域的应用。
🎯 应用场景
Bident框架具有广泛的应用前景,例如个性化教育领域,机器人可以根据学生的学习风格和进度提供定制化的辅导;在医疗保健领域,机器人可以为老年人或残疾人提供陪伴、日常帮助和情感支持;在智能家居领域,机器人可以根据用户的语音指令和行为习惯,自动调节家居环境,提供更舒适的生活体验。该研究有望推动人机协作技术的发展,使机器人更好地服务于人类。
📄 摘要(原文)
Integrating multimodal foundation models has significantly enhanced autonomous agents' language comprehension, perception, and planning capabilities. However, while existing works adopt a \emph{task-centric} approach with minimal human interaction, applying these models to developing assistive \emph{user-centric} robots that can interact and cooperate with humans remains underexplored. This paper introduces ``Bident'', a framework designed to integrate robots seamlessly into shared spaces with humans. Bident enhances the interactive experience by incorporating multimodal inputs like speech and user gaze dynamics. Furthermore, Bident supports verbal utterances and physical actions like gestures, making it versatile for bidirectional human-robot interactions. Potential applications include personalized education, where robots can adapt to individual learning styles and paces, and healthcare, where robots can offer personalized support, companionship, and everyday assistance in the home and workplace environments.