MPGNet: Learning Move-Push-Grasping Synergy for Target-Oriented Grasping in Occluded Scenes
作者: Dayou Li, Chenkun Zhao, Shuo Yang, Ran Song, Xiaolei Li, Wei Zhang
分类: cs.RO
发布日期: 2024-08-20
备注: Accepted to IROS 2024
💡 一句话要点
MPGNet:学习移动-推-抓取协同策略,解决遮挡场景下的目标导向抓取
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 目标导向抓取 遮挡场景 机器人操作 移动-推-抓取协同 深度学习 策略网络 多阶段训练
📋 核心要点
- 现有方法在遮挡场景下的目标导向抓取中,通常依赖推-抓取协同,操作效率和鲁棒性有待提升。
- MPGNet通过学习移动、推和抓取动作之间的协同,实现更高效的目标导向抓取,提升操作的灵活性。
- 通过模拟和真实环境实验验证了MPGNet的有效性,表明其在目标导向抓取任务中具有优越的性能。
📝 摘要(中文)
本文关注遮挡场景下的目标导向抓取问题,其中目标对象由二值掩码指定,目标是以尽可能少的机器人操作次数抓取目标对象。现有方法大多依赖于推-抓取协同来完成此任务。为了提供更强大的目标导向抓取流程,我们提出了MPGNet,一个三分支网络,用于学习移动、推和抓取动作之间的协同。我们还提出了一种多阶段训练策略来训练MPGNet,它包含对应于三个动作的三个策略网络。通过模拟和真实世界的实验证明了我们方法的有效性。
🔬 方法详解
问题定义:论文旨在解决遮挡场景下,机器人如何以最少的动作次数抓取特定目标物体的问题。现有方法主要依赖推-抓取协同,但缺乏对物体位置的预先调整(移动),且推的策略较为单一,导致效率不高,鲁棒性较差。
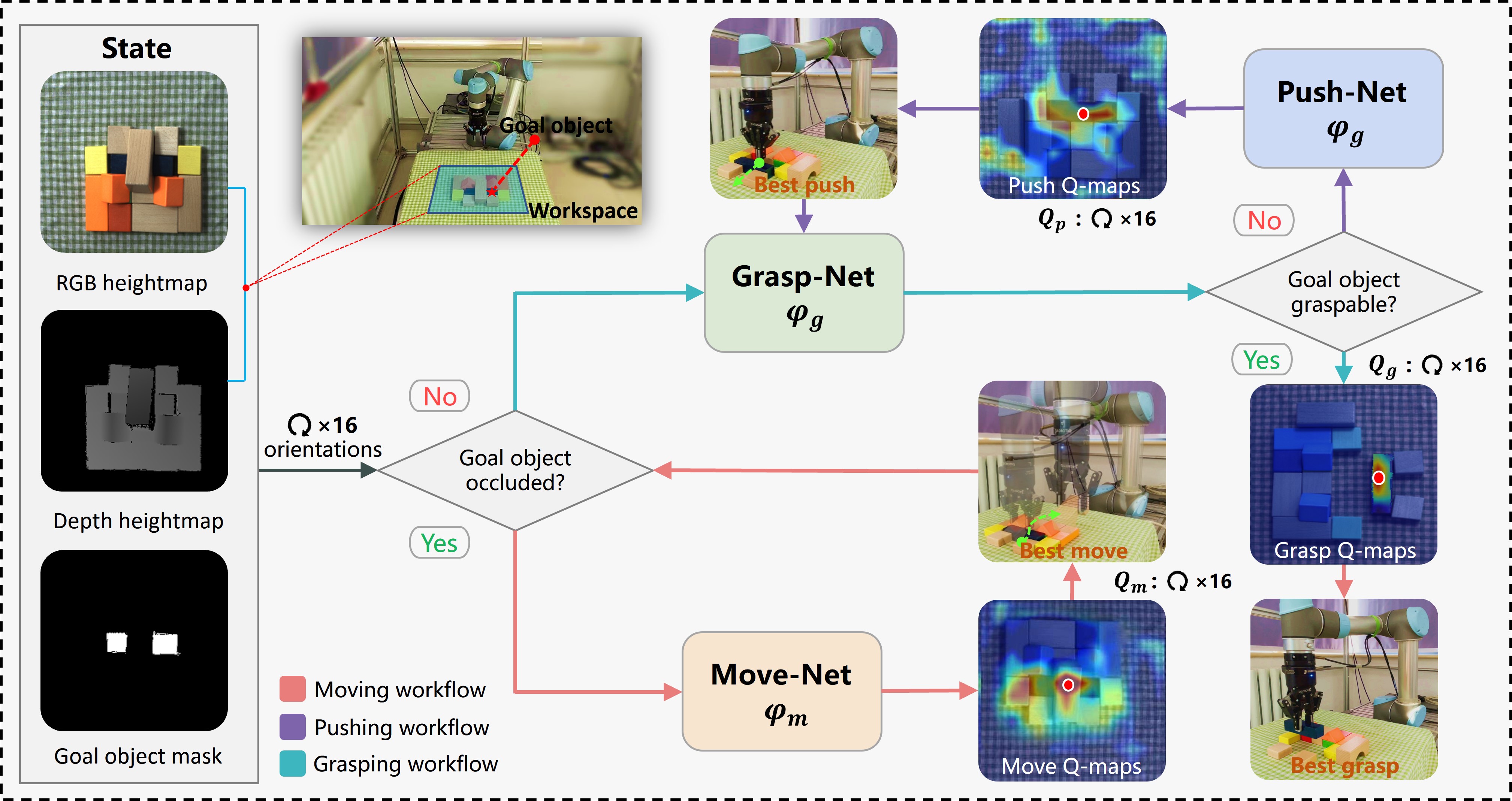
核心思路:论文的核心在于学习移动(Move)、推(Push)、抓取(Grasp)三种动作的协同策略。通过移动调整物体位置,推开遮挡物,最终实现目标物体的可靠抓取。这种协同策略旨在提高抓取效率和成功率。
技术框架:MPGNet是一个三分支网络,每个分支分别对应移动、推和抓取三个动作的策略网络。整体流程为:首先,移动策略网络预测最佳移动方向;然后,推送策略网络预测最佳推送方向;最后,抓取策略网络预测最佳抓取姿态。整个过程可以循环多次,直到成功抓取目标物体。采用多阶段训练策略,分别训练三个策略网络。
关键创新:论文的关键创新在于将移动动作引入到推-抓取协同中,形成移动-推-抓取协同策略。这种策略能够更有效地处理遮挡场景,提高抓取效率和成功率。此外,多阶段训练策略也有助于更好地训练各个策略网络。
关键设计:具体的技术细节包括:使用二值掩码作为目标物体的输入;三个策略网络采用类似的网络结构,但输出不同动作的参数;损失函数的设计需要考虑三个动作之间的协同关系,例如,移动和推送的目的是为了更好地抓取;多阶段训练策略的具体步骤和参数设置。
🖼️ 关键图片

📊 实验亮点
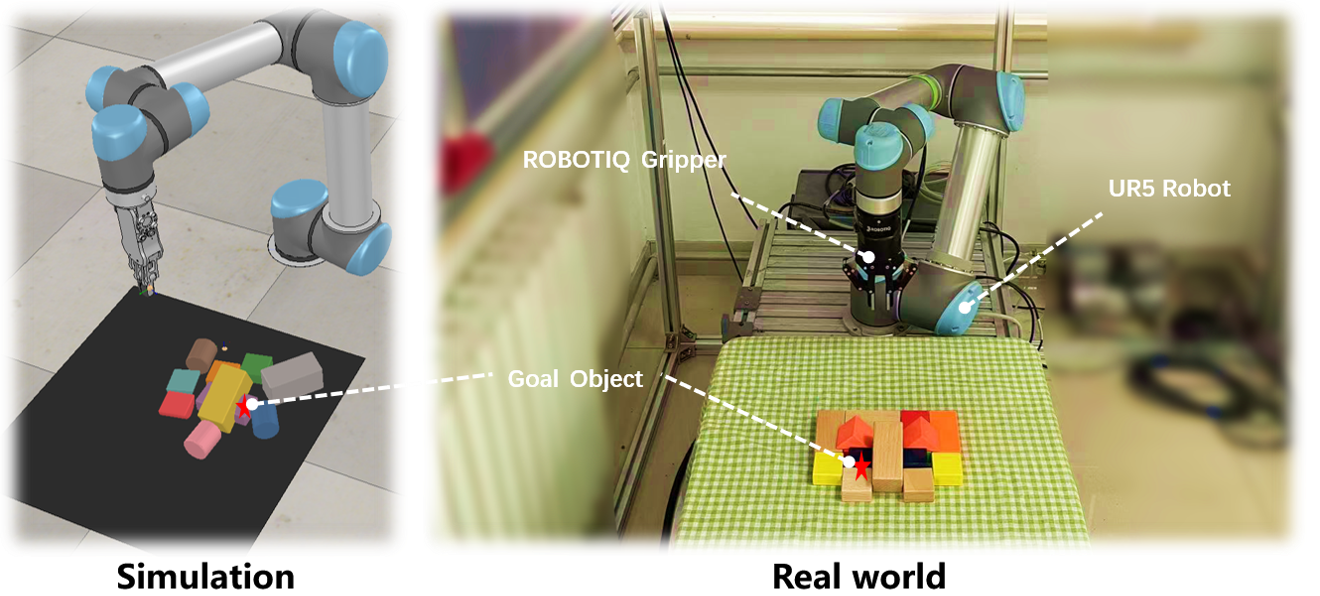
论文通过模拟和真实环境实验验证了MPGNet的有效性。实验结果表明,MPGNet在遮挡场景下的目标导向抓取任务中,相比于现有的推-抓取方法,能够显著提高抓取成功率和效率。具体的性能数据(例如成功率提升百分比、操作次数减少量)未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于自动化仓库拣选、家庭服务机器人、以及工业生产线上。在这些场景中,机器人需要在复杂的环境中抓取特定的目标物体,而目标物体可能被其他物体遮挡。MPGNet能够提高机器人在这些场景下的抓取效率和成功率,从而提高自动化水平。
📄 摘要(原文)
This paper focuses on target-oriented grasping in occluded scenes, where the target object is specified by a binary mask and the goal is to grasp the target object with as few robotic manipulations as possible. Most existing methods rely on a push-grasping synergy to complete this task. To deliver a more powerful target-oriented grasping pipeline, we present MPGNet, a three-branch network for learning a synergy between moving, pushing, and grasping actions. We also propose a multi-stage training strategy to train the MPGNet which contains three policy networks corresponding to the three actions. The effectiveness of our method is demonstrated via both simulated and real-world experiments.