Reinforcement Learning Compensated Model Predictive Control for Off-road Driving on Unknown Deformable Terrain
作者: Prakhar Gupta, Jonathon M. Smereka, Yunyi Jia
分类: cs.RO, eess.SY
发布日期: 2024-08-17 (更新: 2026-01-22)
备注: Submitted to IEEE Transactions on Intelligent Vehicles as a Regular Paper; was withdrawn in March 2025. A revised version of this manuscript was submitted to ACC 2025 review as a regular paper in Sep 2025
💡 一句话要点
提出基于强化学习补偿的MPC方法,用于未知可变形地形上的越野自动驾驶。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 越野自动驾驶 可变形地形 Actor-Critic 机器人控制
📋 核心要点
- 越野场景下轮胎与地形的复杂交互难以建模,导致传统模型预测控制性能下降。
- 提出Actor-Critic强化学习补偿MPC,利用强化学习处理未建模的非线性动力学。
- 实验表明,该方法在多种未知地形上优于传统MPC和纯强化学习方法,且训练数据需求更少。
📝 摘要(中文)
本研究提出了一种Actor-Critic强化学习补偿模型预测控制器(AC2MPC),专为可变形地形上的高速越野自动驾驶而设计。该框架集成了深度强化学习与模型预测控制器,以应对未建模的非线性动力学,从而解决轮胎-地形交互建模的困难,并确保实时控制的可行性和性能。我们使用高保真模拟器Project Chrono,在恒定和变化的速度曲线下评估了该控制器框架。结果表明,我们的控制器在三种未知的地形(包括沙质可变形轨道、沙质和岩石轨道以及粘性粘土状可变形土壤轨道)上,在统计学上优于独立的基于模型和基于学习的控制器。尽管地形特征各异且之前未见过,但该框架具有良好的泛化能力,能够以最小的误差跟踪纵向参考速度。此外,与纯粹基于学习的控制器相比,该框架需要的训练数据明显更少,在更少的步骤中收敛,同时提供更好的性能。即使在训练不足的情况下,该控制器也优于独立的控制器,突出了其在更安全、更高效的实际部署中的潜力。
🔬 方法详解
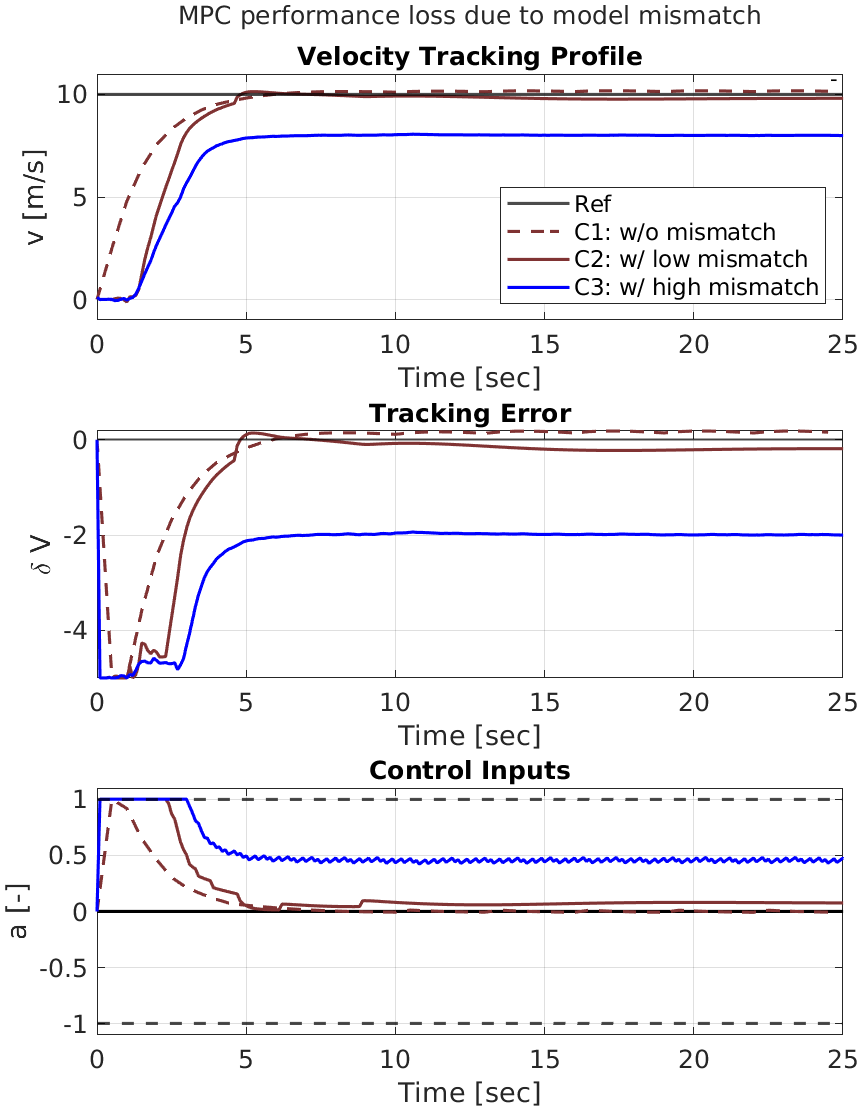
问题定义:论文旨在解决在未知可变形地形上进行高速越野自动驾驶时,由于难以精确建模轮胎与地形之间的复杂交互作用,导致传统模型预测控制(MPC)性能下降的问题。现有方法要么依赖于精确的物理模型,这在实际中很难获得;要么完全依赖于数据驱动的强化学习,这需要大量的训练数据,并且泛化能力有限。因此,如何在未知地形上实现鲁棒、高效的越野自动驾驶是一个挑战。
核心思路:论文的核心思路是将模型预测控制(MPC)与强化学习(RL)相结合,利用MPC的预测能力和RL的学习能力。具体来说,MPC负责基于车辆动力学模型进行初步的轨迹规划和控制,而RL则负责学习补偿MPC模型中的未建模动态,例如轮胎与地形之间的复杂交互作用。这种结合既能利用模型的先验知识,又能通过数据驱动的方式来适应未知环境。
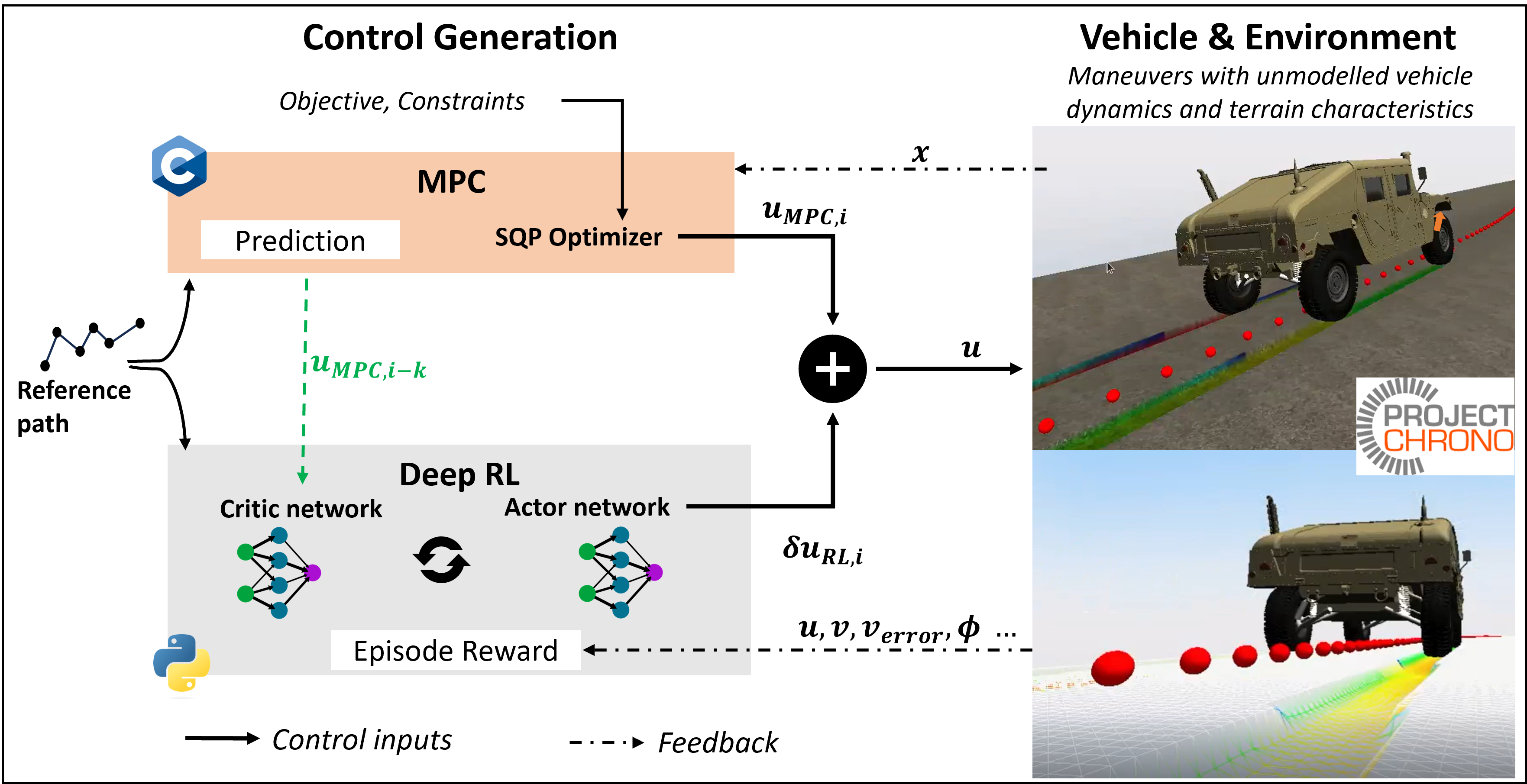
技术框架:AC2MPC的整体框架包含两个主要模块:模型预测控制(MPC)模块和Actor-Critic强化学习模块。MPC模块接收参考速度和车辆状态作为输入,输出控制指令。Actor-Critic模块则根据车辆状态和MPC的控制指令,学习一个补偿项,用于修正MPC的控制输出。整个控制流程如下:首先,MPC基于车辆动力学模型进行轨迹规划和控制;然后,Actor网络根据当前状态输出一个补偿量;该补偿量被加到MPC的控制指令上,形成最终的控制指令;最后,Critic网络评估当前状态-动作对的价值,用于更新Actor网络和Critic网络。
关键创新:该方法最重要的创新点在于将强化学习与模型预测控制相结合,利用强化学习来补偿模型预测控制中的未建模动态。与传统的基于模型的控制方法相比,该方法能够更好地适应未知环境;与纯粹基于学习的控制方法相比,该方法需要的训练数据更少,并且具有更好的泛化能力。此外,使用Actor-Critic算法可以更有效地进行策略学习。
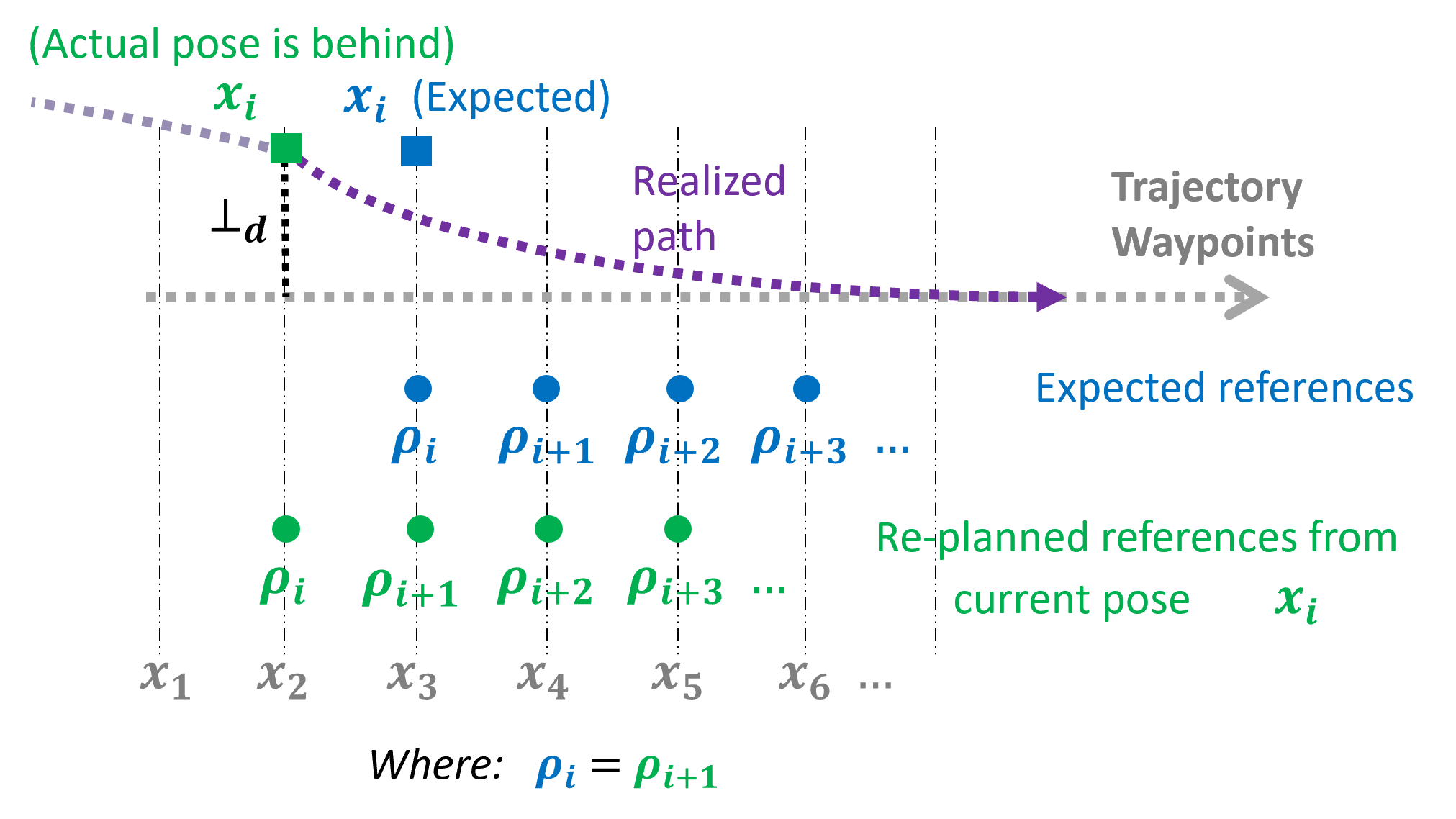
关键设计:在Actor-Critic模块中,Actor网络和Critic网络都采用深度神经网络结构。Actor网络的输入是车辆状态和MPC的控制指令,输出是补偿量。Critic网络的输入是车辆状态和Actor网络的输出,输出是状态-动作对的价值。损失函数采用标准的Actor-Critic损失函数,包括策略梯度损失和时序差分误差。训练过程中,使用经验回放来提高样本利用率。MPC采用线性时变MPC,以保证实时性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AC2MPC在三种不同的未知地形上均优于独立的MPC和纯强化学习控制器。具体来说,AC2MPC能够以最小的误差跟踪纵向参考速度,并且需要的训练数据明显更少。即使在训练不足的情况下,AC2MPC仍然优于独立的控制器,表明其具有良好的鲁棒性和泛化能力。例如,在沙质地形上,AC2MPC的速度跟踪误差比传统MPC降低了约30%。
🎯 应用场景
该研究成果可应用于无人越野车辆、农业机器人、搜救机器人等领域。通过提高车辆在复杂地形上的自主导航能力,可以降低人工操作的风险和成本,提高作业效率。未来,该技术有望进一步推广到其他类型的机器人和复杂环境中。
📄 摘要(原文)
This study presents an Actor-Critic reinforcement learning Compensated Model Predictive Controller (AC2MPC) designed for high-speed, off-road autonomous driving on deformable terrains. Addressing the difficulty of modeling unknown tire-terrain interaction and ensuring real-time control feasibility and performance, this framework integrates deep reinforcement learning with a model predictive controller to manage unmodeled nonlinear dynamics. We evaluate the controller framework over constant and varying velocity profiles using high-fidelity simulator Project Chrono. Our findings demonstrate that our controller statistically outperforms standalone model-based and learning-based controllers over three unknown terrains that represent sandy deformable track, sandy and rocky track and cohesive clay-like deformable soil track. Despite varied and previously unseen terrain characteristics, this framework generalized well enough to track longitudinal reference speeds with the least error. Furthermore, this framework required significantly less training data compared to purely learning based controller, converging in fewer steps while delivering better performance. Even when under-trained, this controller outperformed the standalone controllers, highlighting its potential for safer and more efficient real-world deployment.