Stable-BC: Controlling Covariate Shift with Stable Behavior Cloning
作者: Shaunak A. Mehta, Yusuf Umut Ciftci, Balamurugan Ramachandran, Somil Bansal, Dylan P. Losey
分类: cs.RO
发布日期: 2024-08-12
💡 一句话要点
Stable-BC:通过稳定行为克隆控制协变量偏移,提升模仿学习鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 行为克隆 模仿学习 协变量偏移 控制理论 稳定性 机器人 鲁棒性
📋 核心要点
- 行为克隆在面对训练数据之外的状态时,容易产生累积误差,导致性能下降,这是模仿学习中的一个核心问题。
- Stable-BC的核心思想是利用控制理论分析误差动态,设计策略使机器人行为向专家行为收敛,从而提高鲁棒性。
- 实验表明,Stable-BC在模拟和真实机器人环境中均表现出良好的性能,验证了其对协变量偏移的鲁棒性。
📝 摘要(中文)
行为克隆是一种常见的模仿学习范式。在这种方法中,机器人收集专家演示数据,然后训练策略以匹配专家的行为。当机器人学习器访问专家已经演示过正确行为的状态时,效果良好;但机器人不可避免地会遇到训练数据集之外的新状态。如果机器人在这些新状态下采取错误的行动,可能会进一步偏离训练数据,从而导致越来越不正确的行动和累积误差。现有工作试图通过增强训练数据来解决这一根本挑战。相比之下,本文开发了行为克隆策略的控制理论性质。具体来说,我们考虑系统当前状态与专家数据集中的状态之间的误差动态。从误差动态中,我们推导出基于模型和无模型的稳定性条件:在这些条件下,机器人调整其策略,使其当前行为收敛于专家数据集中的示例行为。实际上,这产生了Stable-BC,它是标准行为克隆的一个易于实现的扩展,并且可以证明对协变量偏移具有鲁棒性。我们在具有交互式、非线性和视觉环境的模拟中证明了我们算法的有效性。我们还进行了实验,其中机器人手臂使用Stable-BC来玩空气曲棍球。
🔬 方法详解
问题定义:行为克隆(BC)在模仿学习中被广泛应用,但其性能严重依赖于训练数据的覆盖范围。当机器人遇到训练数据中未曾出现的状态(即协变量偏移)时,BC策略容易做出错误决策,导致状态进一步偏离训练数据,产生累积误差。现有方法主要通过数据增强来缓解这个问题,但难以完全解决。
核心思路:Stable-BC的核心思路是利用控制理论来分析和控制机器人状态与专家状态之间的误差动态。通过设计满足特定稳定性条件的策略,确保机器人的行为能够向专家行为收敛,从而抑制误差的累积,提高对协变量偏移的鲁棒性。这种方法从策略设计的角度出发,而非单纯依赖数据增强。
技术框架:Stable-BC的整体框架是在标准行为克隆的基础上,增加了一个稳定性约束。首先,利用专家数据训练一个初始的BC策略。然后,基于误差动态推导出稳定性条件,这些条件可以是基于模型的,也可以是无模型的。最后,通过优化策略,使其在模仿专家行为的同时,满足稳定性条件。这可以通过修改损失函数或添加正则化项来实现。
关键创新:Stable-BC最重要的技术创新在于将控制理论引入到行为克隆中,并推导出了保证策略稳定性的条件。与传统BC方法不同,Stable-BC不仅关注模仿的准确性,更关注策略的稳定性,从而提高了对协变量偏移的鲁棒性。这种方法为解决模仿学习中的泛化问题提供了一个新的视角。
关键设计:Stable-BC的关键设计在于稳定性条件的推导和策略优化。稳定性条件可以基于李雅普诺夫稳定性理论或其他控制理论方法推导。策略优化可以通过添加正则化项到BC损失函数中来实现,例如,添加一个惩罚项,使得策略的输出更加平滑,或者使得策略的输出更加接近一个已知的稳定策略。具体的损失函数形式和正则化系数需要根据具体任务进行调整。
🖼️ 关键图片


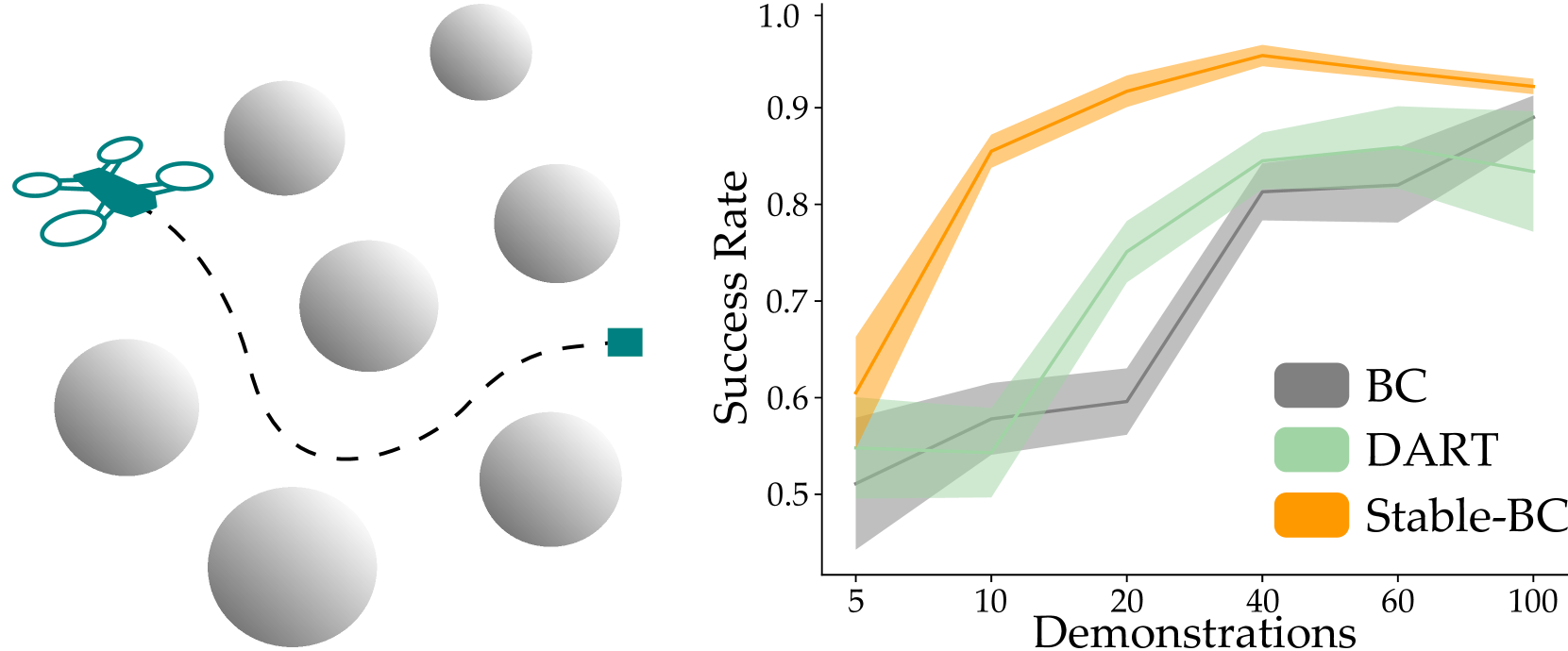
📊 实验亮点
Stable-BC在多个模拟环境中进行了验证,包括交互式、非线性和视觉环境。实验结果表明,Stable-BC能够显著提高行为克隆策略的鲁棒性,降低累积误差。在机器人手臂玩空气曲棍球的实验中,Stable-BC也表现出了良好的性能,证明了其在真实机器人环境中的有效性。具体性能提升数据未知。
🎯 应用场景
Stable-BC具有广泛的应用前景,尤其适用于需要在复杂、动态环境中进行模仿学习的机器人系统。例如,它可以应用于自动驾驶、机器人操作、医疗机器人等领域,提高机器人在未知环境中的适应性和安全性。此外,该方法还可以用于训练更鲁棒的AI助手,使其能够更好地理解和执行人类指令。
📄 摘要(原文)
Behavior cloning is a common imitation learning paradigm. Under behavior cloning the robot collects expert demonstrations, and then trains a policy to match the actions taken by the expert. This works well when the robot learner visits states where the expert has already demonstrated the correct action; but inevitably the robot will also encounter new states outside of its training dataset. If the robot learner takes the wrong action at these new states it could move farther from the training data, which in turn leads to increasingly incorrect actions and compounding errors. Existing works try to address this fundamental challenge by augmenting or enhancing the training data. By contrast, in our paper we develop the control theoretic properties of behavior cloned policies. Specifically, we consider the error dynamics between the system's current state and the states in the expert dataset. From the error dynamics we derive model-based and model-free conditions for stability: under these conditions the robot shapes its policy so that its current behavior converges towards example behaviors in the expert dataset. In practice, this results in Stable-BC, an easy to implement extension of standard behavior cloning that is provably robust to covariate shift. We demonstrate the effectiveness of our algorithm in simulations with interactive, nonlinear, and visual environments. We also conduct experiments where a robot arm uses Stable-BC to play air hockey. See our website here: https://collab.me.vt.edu/Stable-BC/