Space-LLaVA: a Vision-Language Model Adapted to Extraterrestrial Applications
作者: Matthew Foutter, Daniele Gammelli, Justin Kruger, Ethan Foss, Praneet Bhoj, Tommaso Guffanti, Simone D'Amico, Marco Pavone
分类: cs.RO, cs.AI
发布日期: 2024-08-12 (更新: 2025-01-18)
备注: Accepted to IEEE Aerospace Conference, 23 pages, 18 figures, 3 tables
💡 一句话要点
Space-LLaVA:针对地外应用场景的视觉-语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 地外应用 空间机器人 零样本学习 数据增强
📋 核心要点
- 空间机器人面临地面操作扩展性、环境泛化能力和多模态数据处理等挑战,现有方法难以有效应对。
- Space-LLaVA通过程序化地增强地外数据集,并微调预训练的LLaVA模型,使其适应地外环境的视觉语义特征。
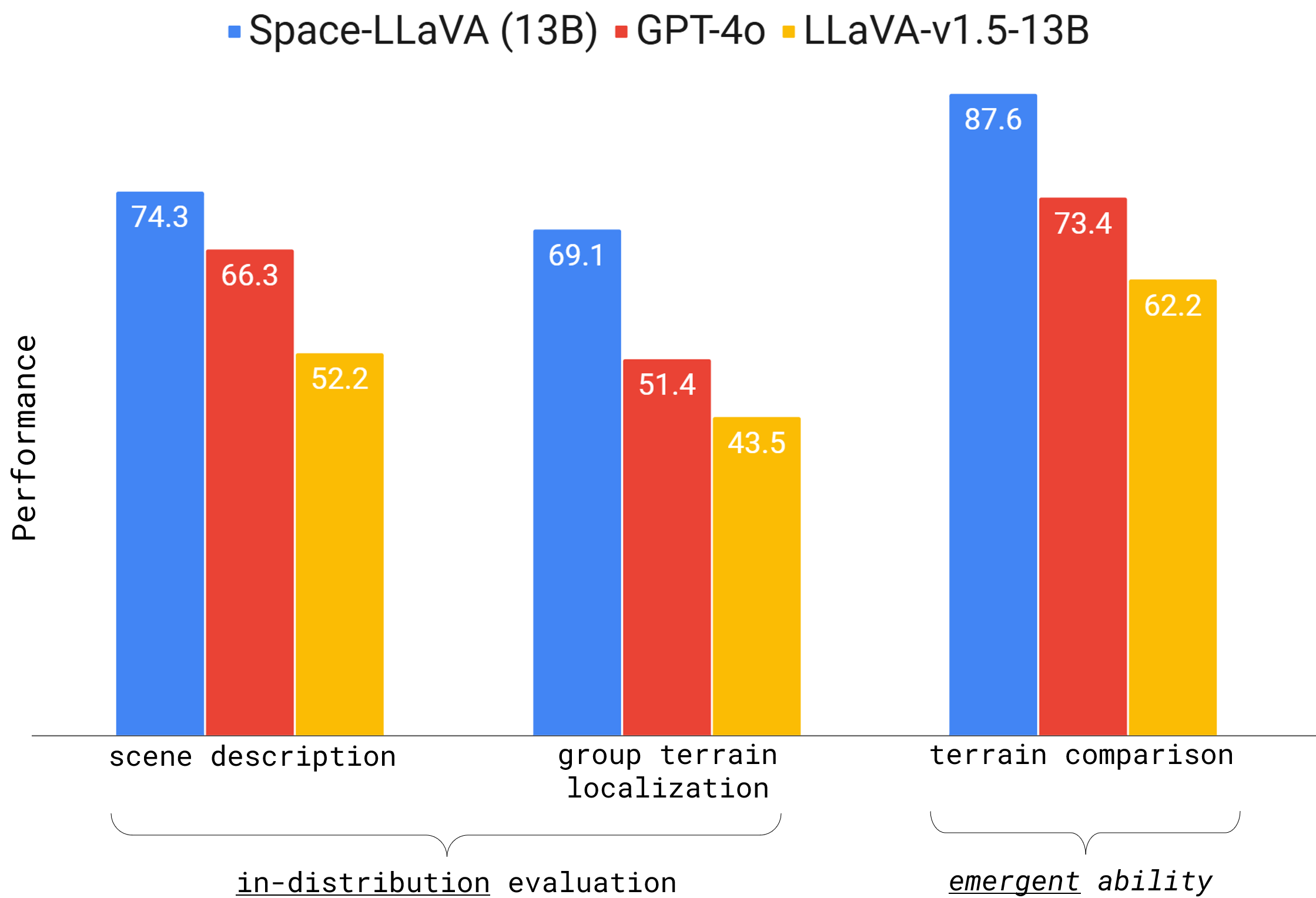
- 实验表明,Space-LLaVA在未见过的任务上表现出更强的零样本性能,证明了其在地外应用场景中的有效性。
📝 摘要(中文)
本文提出了一种针对地外应用场景的视觉-语言模型Space-LLaVA。为了解决地面操作的可扩展性、知识泛化到新环境以及多模态任务和传感器数据等空间机器人领域的挑战,研究人员通过程序化地使用细粒度的语言标注增强了三个地外数据库,构建了一个视觉问答和视觉指令跟随的合成数据集。该数据集的标注灵感来源于在火星上识别科学兴趣点所需的感知推理。研究人员在增强的数据集上微调了一个预训练的LLaVA 13B检查点,使视觉-语言模型(VLM)适应地外环境中的视觉语义特征。实验表明,FMs可以作为一种专业化工具,增强VLM在未见过的任务类型上的零样本性能,优于最先进的VLM。消融研究表明,协同微调语言骨干网络和视觉-语言适配器是实现适应的关键,而使用一小部分(如20%)的预训练数据可以防止灾难性遗忘。
🔬 方法详解
问题定义:论文旨在解决空间机器人领域中,现有视觉-语言模型在地外环境下的泛化能力不足的问题。现有方法依赖大量真实数据,标注成本高昂,且难以覆盖所有地外场景。此外,现有模型难以有效利用多模态数据,无法满足空间机器人复杂任务的需求。
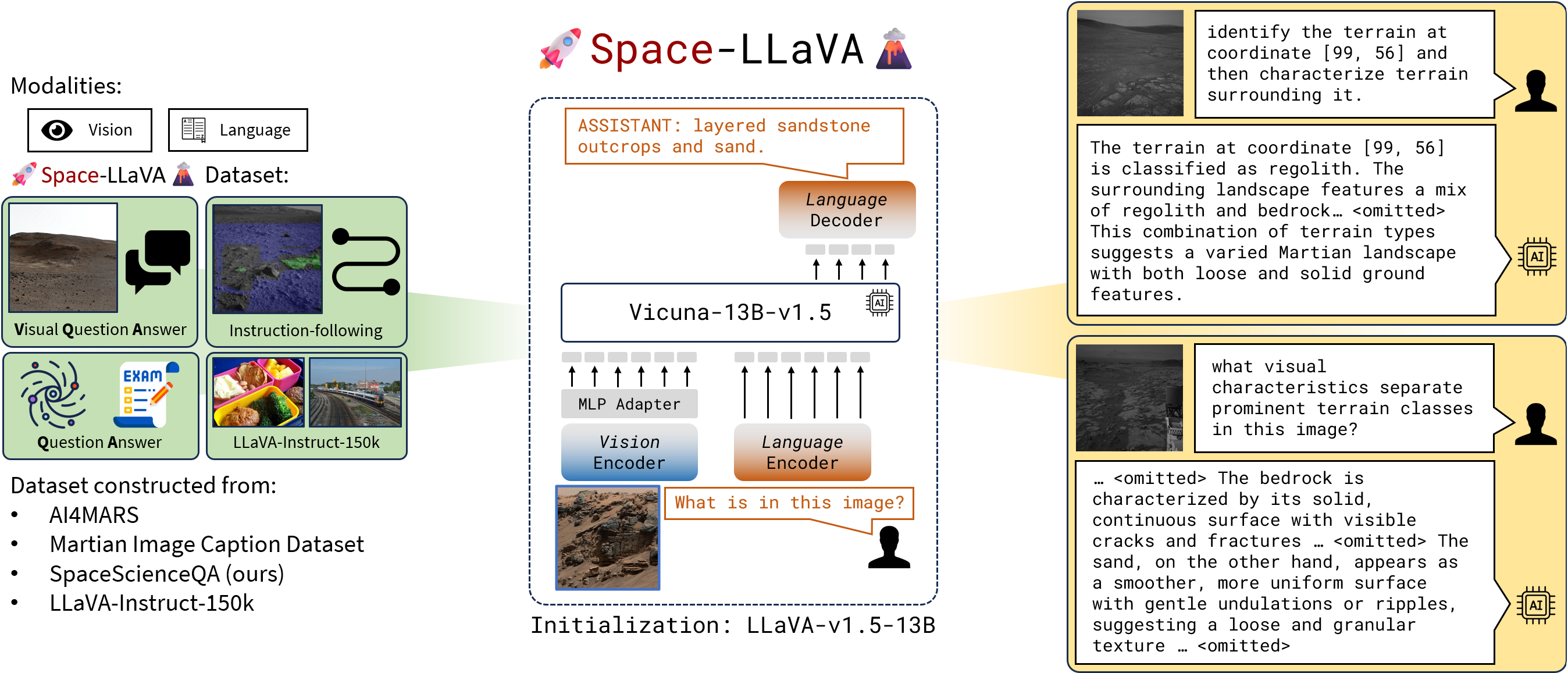
核心思路:论文的核心思路是利用程序化数据增强方法,生成包含细粒度语言标注的合成地外数据集,并在此基础上微调预训练的视觉-语言模型LLaVA。通过这种方式,模型可以学习到地外环境的视觉语义特征,从而提高其泛化能力和零样本性能。
技术框架:Space-LLaVA的整体框架包括以下几个主要步骤:1) 选择三个地外数据库作为基础数据;2) 使用程序化方法生成细粒度的语言标注,构建视觉问答和视觉指令跟随的合成数据集;3) 在合成数据集上微调预训练的LLaVA 13B模型,包括视觉编码器、语言模型和视觉-语言适配器;4) 在未见过的地外任务上评估模型的零样本性能。
关键创新:论文的关键创新在于:1) 提出了一种程序化的数据增强方法,可以高效地生成包含细粒度语言标注的地外数据集;2) 通过协同微调语言骨干网络和视觉-语言适配器,实现了模型对地外环境的有效适应;3) 实验证明,使用少量预训练数据可以有效防止灾难性遗忘。与现有方法相比,Space-LLaVA无需大量真实数据即可实现良好的泛化性能。
关键设计:在数据增强方面,论文设计了多种规则和模板,用于生成不同类型的语言标注,例如描述图像内容、回答问题、给出指令等。在模型微调方面,论文采用了AdamW优化器,并设置了合适的学习率和权重衰减系数。此外,论文还探索了不同比例的预训练数据对模型性能的影响,发现使用20%的预训练数据可以有效防止灾难性遗忘。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Space-LLaVA在未见过的地外任务上表现出优异的零样本性能,显著优于其他视觉-语言模型。消融研究表明,协同微调语言骨干网络和视觉-语言适配器是实现最佳性能的关键。此外,实验还证明,使用少量预训练数据可以有效防止灾难性遗忘,保证模型的稳定性和泛化能力。
🎯 应用场景
Space-LLaVA可应用于多种地外任务,例如火星车自主导航、科学目标识别、资源勘探等。该研究成果有助于降低空间任务的成本和风险,提高任务的效率和可靠性。未来,Space-LLaVA有望成为空间机器人的核心组成部分,为人类探索宇宙提供强大的智能支持。
📄 摘要(原文)
Foundation Models (FMs), e.g., large language models, possess attributes of intelligence which offer promise to endow a robot with the contextual understanding necessary to navigate complex, unstructured tasks in the wild. We see three core challenges in the future of space robotics that motivate building an FM for the space robotics community: 1) Scalability of ground-in-the-loop operations; 2) Generalizing prior knowledge to novel environments; and 3) Multi-modality in tasks and sensor data. As a first-step towards a space foundation model, we programmatically augment three extraterrestrial databases with fine-grained language annotations inspired by the sensory reasoning necessary to e.g., identify a site of scientific interest on Mars, building a synthetic dataset of visual-question-answer and visual instruction-following tuples. We fine-tune a pre-trained LLaVA 13B checkpoint on our augmented dataset to adapt a Vision-Language Model (VLM) to the visual semantic features in an extraterrestrial environment, demonstrating FMs as a tool for specialization and enhancing a VLM's zero-shot performance on unseen task types in comparison to state-of-the-art VLMs. Ablation studies show that fine-tuning the language backbone and vision-language adapter in concert is key to facilitate adaption while a small percentage, e.g., 20%, of the pre-training data can be used to safeguard against catastrophic forgetting.