HDPlanner: Advancing Autonomous Deployments in Unknown Environments through Hierarchical Decision Networks
作者: Jingsong Liang, Yuhong Cao, Yixiao Ma, Hanqi Zhao, Guillaume Sartoretti
分类: cs.RO
发布日期: 2024-08-07
备注: Submitted to RA-L
💡 一句话要点
HDPlanner:基于分层决策网络提升未知环境下的自主部署能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主探索 机器人导航 深度强化学习 分层决策网络 注意力机制
📋 核心要点
- 现有自主探索和导航方法在未知环境中难以兼顾效率和鲁棒性,面临着长期规划和环境适应的挑战。
- HDPlanner采用分层注意力网络,将长期目标分解为短期任务分配和路径规划,实现多尺度空间推理和协同决策。
- 实验表明,HDPlanner在仿真和真实环境中均优于现有方法,显著减少了行驶距离,并具备实时规划能力。
📝 摘要(中文)
本文提出HDPlanner,一个基于深度强化学习(DRL)的框架,旨在解决移动机器人的两个核心且具有挑战性的任务:自主探索和导航。在该任务中,机器人必须自适应地优化其轨迹,通过在未知环境中持续交互来实现任务目标。HDPlanner依赖于新颖的分层注意力网络,使机器人能够推理跨多个空间尺度的信念并按顺序协同决策。我们的网络将长期目标分解为短期的信息性任务分配和信息性路径规划。我们进一步提出了一种基于对比学习的联合优化,以增强HDPlanner的鲁棒性。大量的仿真实验表明,HDPlanner显著优于最先进的传统和基于学习的基线,包括数百个测试地图和大规模、复杂的Gazebo环境。值得注意的是,HDPlanner实现了实时规划,与探索基准相比,行驶距离减少了高达35.7%,与导航基准相比,减少了高达16.5%。此外,我们在硬件上验证了我们的方法,它在室内和室外环境中生成高质量的自适应轨迹,突出了其在现实世界中的适用性,而无需额外的训练。
🔬 方法详解
问题定义:论文旨在解决移动机器人在未知环境中的自主探索和导航问题。现有方法通常难以在探索效率、路径优化和环境适应性之间取得平衡,尤其是在复杂和大规模环境中,容易陷入局部最优或规划出冗余路径。此外,现有方法在真实环境中的鲁棒性也面临挑战。
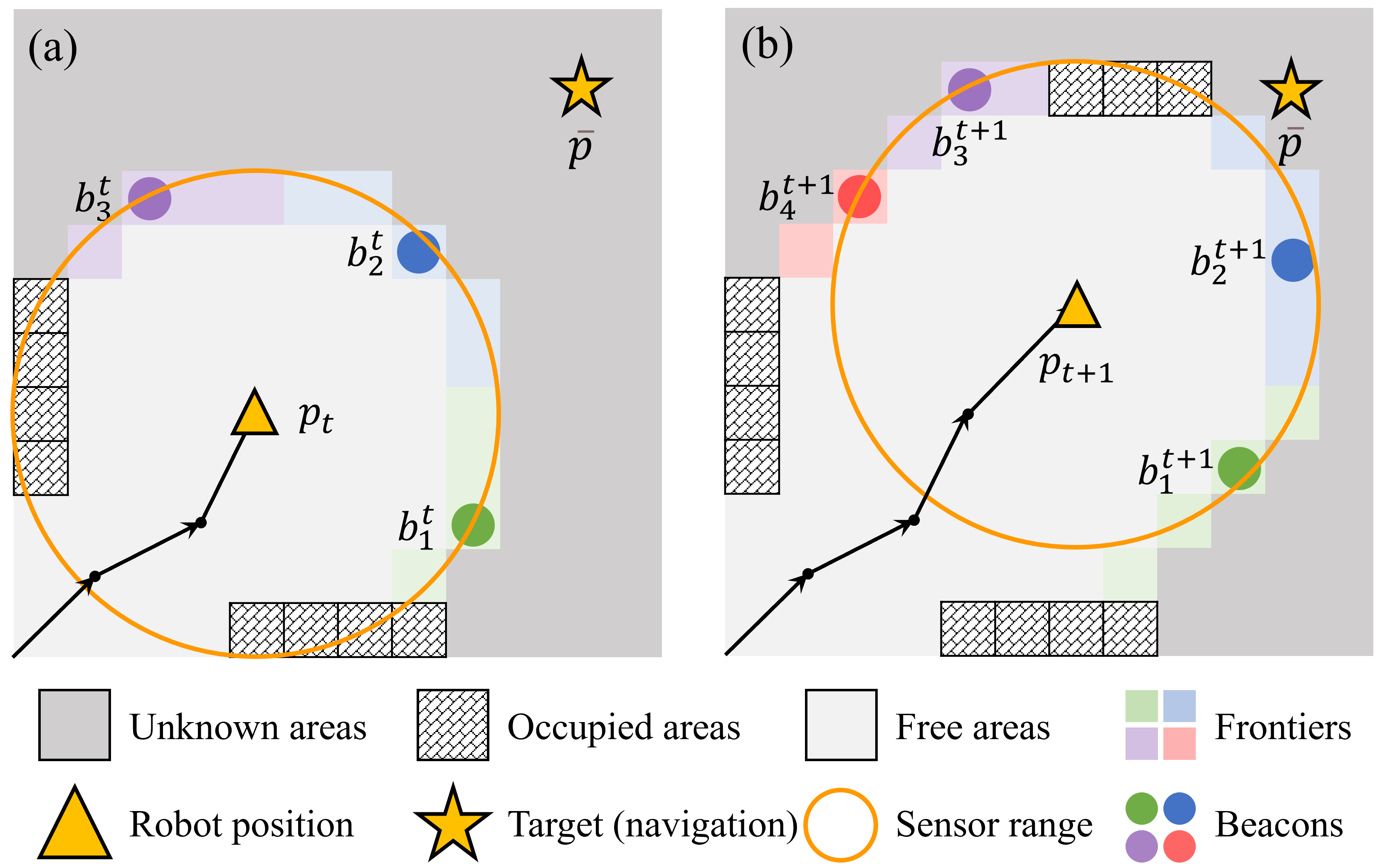
核心思路:HDPlanner的核心思路是利用分层决策网络,将复杂的长期规划问题分解为一系列短期的、更易于管理的子任务。通过分层结构,机器人可以首先进行全局的任务分配,然后针对每个任务进行局部路径规划,从而实现更高效和鲁棒的探索和导航。注意力机制的引入使得网络能够关注关键信息,提高决策的准确性。
技术框架:HDPlanner的整体框架包含以下几个主要模块:1) 感知模块:负责从传感器数据中提取环境信息,构建环境地图。2) 分层决策网络:包含高层任务分配网络和低层路径规划网络。高层网络根据全局环境信息,将长期目标分解为一系列短期任务。低层网络根据局部环境信息,为每个任务规划最优路径。3) 对比学习模块:用于增强模型的鲁棒性,通过对比学习,模型可以学习到更具区分性的特征表示,从而提高在未知环境中的泛化能力。
关键创新:HDPlanner的关键创新在于其分层注意力网络结构和对比学习的联合优化。分层结构使得模型能够进行多尺度的空间推理,从而更好地理解环境。注意力机制使得模型能够关注关键信息,提高决策的准确性。对比学习则增强了模型的鲁棒性,使其能够更好地适应未知环境。
关键设计:高层任务分配网络和低层路径规划网络均采用深度神经网络结构。高层网络输入全局环境地图,输出任务分配概率。低层网络输入局部环境地图和任务目标,输出路径规划结果。对比学习采用InfoNCE损失函数,鼓励模型学习到更具区分性的特征表示。具体参数设置(如网络层数、神经元数量、学习率等)根据实验结果进行调整。
🖼️ 关键图片


📊 实验亮点
HDPlanner在仿真实验中显著优于现有方法,与探索基准相比,行驶距离减少了高达35.7%,与导航基准相比,减少了高达16.5%。此外,HDPlanner在真实环境中也表现出良好的性能,能够生成高质量的自适应轨迹,验证了其在实际应用中的可行性。值得一提的是,HDPlanner无需额外的训练即可在真实环境中部署,体现了其良好的泛化能力。
🎯 应用场景
HDPlanner可广泛应用于各种需要自主探索和导航的场景,例如:仓库物流、灾难救援、自动驾驶、农业机器人、以及家庭服务机器人等。该研究成果有助于提升机器人在未知环境中的自主作业能力,降低人工干预的需求,提高工作效率和安全性。未来,该技术有望进一步拓展到更复杂的任务和环境,例如:多机器人协同探索、复杂地形导航等。
📄 摘要(原文)
In this paper, we introduce HDPlanner, a deep reinforcement learning (DRL) based framework designed to tackle two core and challenging tasks for mobile robots: autonomous exploration and navigation, where the robot must optimize its trajectory adaptively to achieve the task objective through continuous interactions in unknown environments. Specifically, HDPlanner relies on novel hierarchical attention networks to empower the robot to reason about its belief across multiple spatial scales and sequence collaborative decisions, where our networks decompose long-term objectives into short-term informative task assignments and informative path plannings. We further propose a contrastive learning-based joint optimization to enhance the robustness of HDPlanner. We empirically demonstrate that HDPlanner significantly outperforms state-of-the-art conventional and learning-based baselines on an extensive set of simulations, including hundreds of test maps and large-scale, complex Gazebo environments. Notably, HDPlanner achieves real-time planning with travel distances reduced by up to 35.7% compared to exploration benchmarks and by up to 16.5% than navigation benchmarks. Furthermore, we validate our approach on hardware, where it generates high-quality, adaptive trajectories in both indoor and outdoor environments, highlighting its real-world applicability without additional training.